Elasticsearch:跨集群复制 Cross-cluster replication(CCR)
跨集群复制(CCR)功能支持将远程集群中的索引复制到本地集群。可以在一些常见的生产用例中使用此功能:灾难恢复(DR)/高可用性(HA):如果主群集发生故障,则进行灾难恢复。 辅助群集可以用作热备份地理位置优越:在Elasticsearch中复制数据以更接近用户或应用程序服务器,从而减少延迟。可以在本地提供阅读服务集中报告:将数据从大量较小的集群复制回集中式报告集群请注意:CCR 是...
跨集群复制(CCR)功能支持将远程集群中的索引复制到本地集群。 可以在一些常见的生产用例中使用此功能:
- 灾难恢复(DR)/高可用性(HA):如果主群集发生故障,则进行灾难恢复。 辅助群集可以用作热备份
- 地理位置优越:在 Elasticsearch 中复制数据以更接近用户或应用程序服务器,从而减少延迟。可以在本地提供阅读服务
- 集中报告:将数据从大量较小的集群复制回一个中央集群进行报告
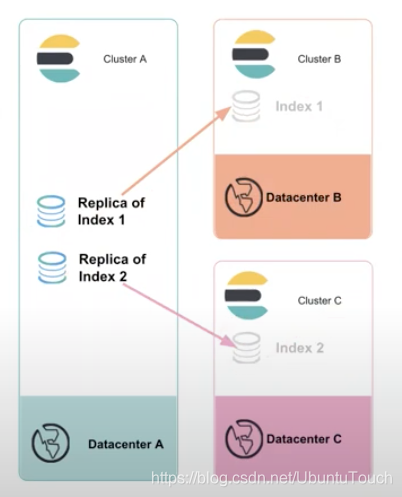
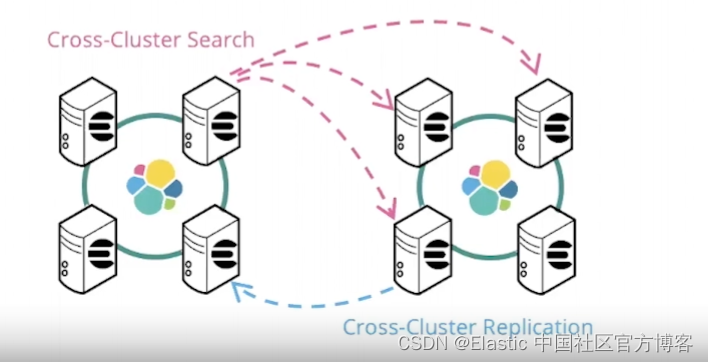
请注意:CCR 是一个自 6.7 的一个 platinum 功能。如果你想了解更多关于 CCR 跨集群的安全问题,请参阅我的另外一篇文章 “Elasticsearch:跨集群搜索 Cross-cluster search(CCS)及安全”。
CCR 是按索引编制的
复制是针对每个索引来配置的。对于每个配置的复制,都有
- 复制源索引称为 leader 索引
- 复制目标索引称为 follower 索引
一个集群可以同时包含 leader 索引和 follower 索引:
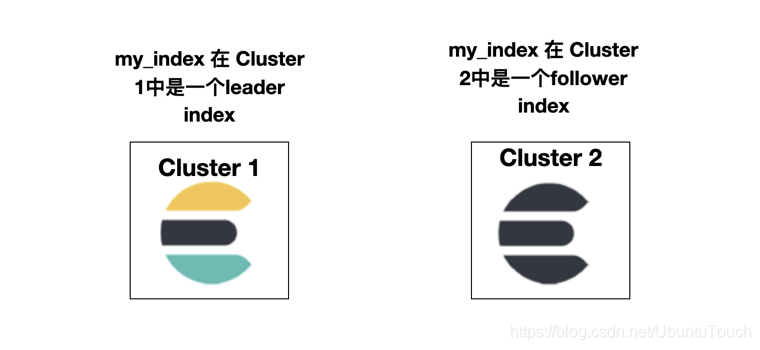
复制是主动-被动关系
你可以使用 leader 索引来进行读或写,这个索引存在于远程集群里,但是你只能针对 follower 索引进行读操作。follower 索引存在于本地的集群里。
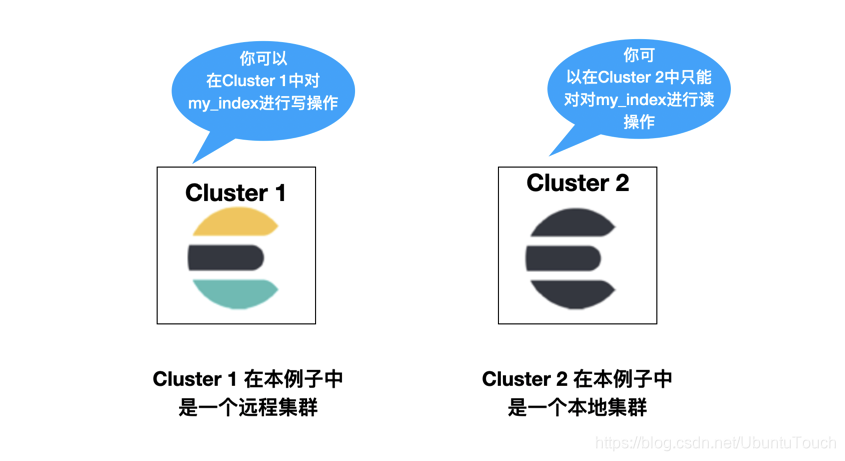
复制是基于拉动的
关注者中的每个分片将从其领导者索引中的相应分片中拉取更改。follower 的索引的分片数量与其 leader 索引相同
- 所有操作均由 follower 复制
- 复制几乎实时完成
- 操作被 follower 分片拉动并批量建立索引
- 多个请求同时进行,更改可以同时进行
CCR 的前提条件
在进行 CCR 之前,我们必须满足一下的一些条件:
- 跨集群复制需要远程集群。
- 本地集群的 Elasticsearch 版本必须与远程集群相同或比远程集群新。 如果较新,则这些版本还必须兼容以下矩阵中概述的版本。
- 就像上面所讲的那样,因为 CCR 是一个 platinum 功能,你必须购买版权,或者你可以先尝试一个免费的测试
如果启用了弹性安全功能,那么你需要具有适当的用户权限。当我们使用 elastic 用户名时,需要特别注意,因为它具有超级用户的角色,你可能会无意中做了一个重大的更改。
- 在远程群集上,您将需要具有 read_ccr 权限的群集用户,以及 follower 索引必须具有 monitor 及和 read 权限
- 在本地群集上,同一用户将需要 manage_ccr 群集权限。follower 索引必须具有 monitor,read, write 及 manage_follow_index的权限
CCR 带来的好处
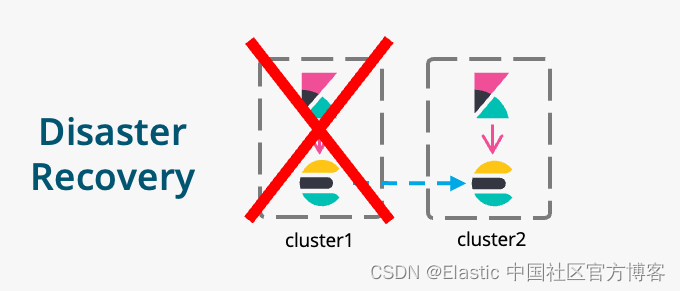
灾难恢复
当一个集群不能正常工作时,如果这个集群里的数据已经被另外一个集群成功复制,那么我们很容易快速地恢复这些数据:
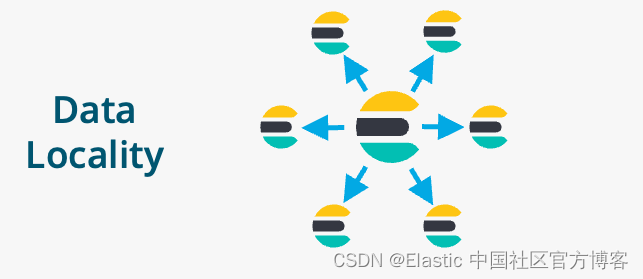
数据局部性
我们可以把一个远程集群的数据复制到本地,这样更容易被搜索(速度提高):
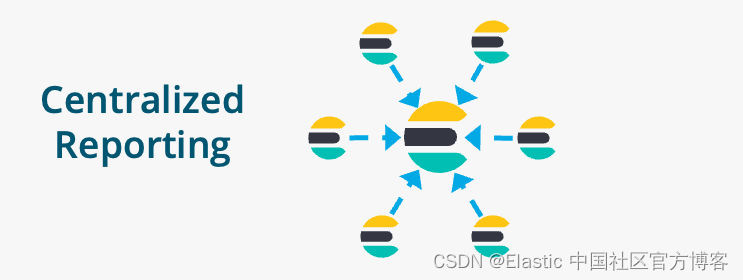
集中报告
我们可以把各个地方的数据汇总到同一个集群,这样一个中央集群的数据包含所有位于分部的集群数据。这可以帮助我们快速地对数据进行统计:
动手实践
在这个实验里,我们首先按照我之前的文章 “Elasticsearch:跨集群搜索 Cross-cluster search (CCS)” 来安装我们的两个集群。不过,这里有两个小的区别:
- 我们为每个集群打开安全。我们可以按照我之前的文章 “Elasticsearch:设置Elastic账户安全” 来对我们的两个集群设置安全。为了方便,我们将使用 elastic 用户来进行操作,尽管我们需要特别的小心
- 由于这个功能是 platinum 功能,在没有购买的情况下,我们可以进行尝试来测试这个功能。为此,我们必须安装如下的方式打开这个功能:

在上面,我们选择 “Start trial” 这个按钮,并接受相应的条件。接下来,我们就可以开始我们的测试了。
我们也可以按照如下的命令来启动 trial:
curl -X POST "http://localhost:9200/_license/start_trial?acknowledge=true"cluster_1
我们在 cluster_1 上创建如下的一个叫做 twitter 的索引:
POST _bulk
{"index":{"_index":"twitter","_id":1}}
{"user":"张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}, "DOB": "1999-04-01"}
{"index":{"_index":"twitter","_id":2}}
{"user":"老刘","message":"出发,下一站云南!","uid":3,"age":22,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}, "DOB": "1997-04-01"}
{"index":{"_index":"twitter","_id":3}}
{"user":"李四","message":"happy birthday!","uid":4,"age":25,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}, "DOB": "1994-04-01"}
{"index":{"_index":"twitter","_id":4}}
{"user":"老贾","message":"123,gogogo","uid":5,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}, "DOB": "1989-04-01"}
{"index":{"_index":"twitter","_id":5}}
{"user":"老王","message":"Happy BirthDay My Friend!","uid":6,"age":26,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}, "DOB": "1993-04-01"}
{"index":{"_index":"twitter","_id":6}}
{"user":"老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":28,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}, "DOB": "1991-04-01"}cluster_2
我们在 cluster_2 上进行如下的操作:

我们点击 “Add a remote cluster”:

我们填入相应的名称及seed的相关信息,并点击“Save”:

当我们点击完 “Save” 后,就会出现上的画面,表明我们的 remote_twitter 已经连接成功。在上面我们点击 “Close”。我们接下来点击 “Cross-Cluster Replication”:

我们点击上面的 “Create a follower index”:

我们填入相应的信息。注意上面我们定义一个叫做 twitter_copy 的 follower index。当我们填入上面的信息过后,我们点击 “Create” 按钮:

我们可以看到刚才创建的 twitter_copy 的状态经过很短的时间由 paused 变为 active,表明我们的 index 创建是成功的。
我们点击 Dev Tools,并打入如下的命令:

我们可以看到最新创建的 twitter_copy 这个索引。我们可以针对这个索引进行搜索:

我们可以看到我们有7个结果。我们可以在我们的 cluster_1 中加入一个新的文档:

我们在 cluster_1 中为 twitter 索引新增加了一个文档。这个文档的 id 为8。接下来我们在 cluster_2 中马上来查一下:
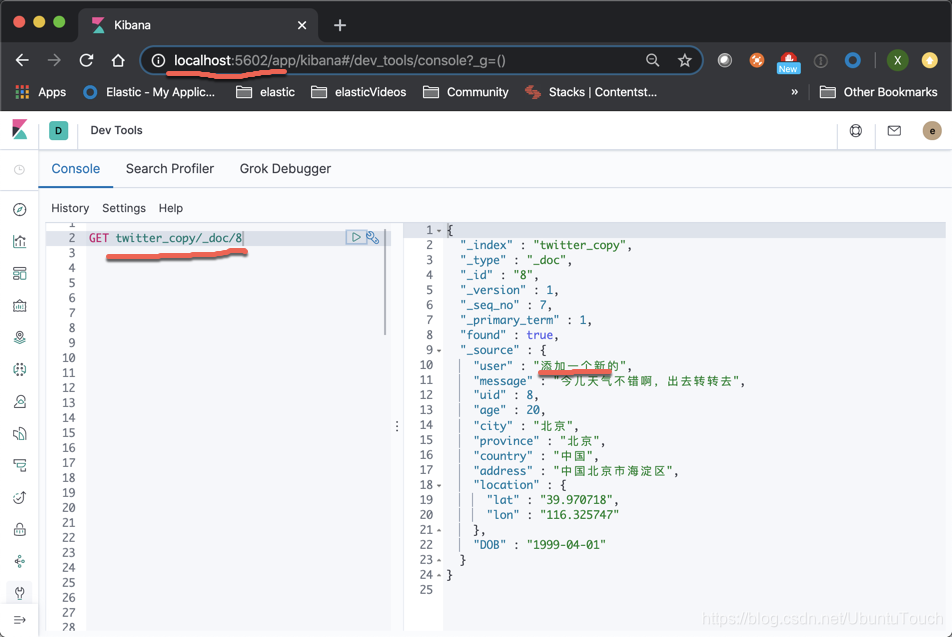
我们可以看到我们最新添加的一个 id 为8的文档已经被成功在 cluster_2 中可见。这说明我们的自动复制功能已经在起作用。
除了上面的界面来生产一个 twitter_copy 的索引(我们不需要预先生产任何的 twitter_copy 索引,下面的命令将生成 twitter_copy),我们也可以直接使用 API 来完成。在 cluster_2 的 Kibana 中打入如下的命令:
PUT twitter_copy/_ccr/follow
{
"remote_cluster" : "remote_twitter",
"leader_index" : "twitter"
}当我们执行上面的命令后,它会自动帮我拷贝索引 twitter。
发起 index pattern 复制
如果你有时间序列数据,请启用 auto-follow 功能以自动创建关注者索引。我们安装如下的方法来进行:



在上面,我们定义了所有以 logs 为开头的索引,都将备份。备份的文件名是以 -copy 为结尾的文件名。点击上面的 Create 按钮:

经过上面的配置后,我们可以在 Kibana 中打入如下的命令来进行查看:
GET /_ccr/auto_follow/remote_logs上面的命令显示的结果为:
{
"patterns" : [
{
"name" : "remote_logs",
"pattern" : {
"active" : true,
"remote_cluster" : "remote_ccr",
"leader_index_patterns" : [
"logs*"
],
"follow_index_pattern" : "{{leader_index}}-copy"
}
}
]也就是说,我们也可以直接通过如的方法来进行配置:
PUT /_ccr/auto_follow/remote_logs
{
"remote_cluster": "remote_ccr",
"leader_index_patterns": "logs*",
"follow_index_pattern": "{{leader_index}}-copy"
}在我们的 cluster_1 的 Kibana 中,我们打入如下的命令来生产相应的 log 索引:
PUT logs_1/_doc/1
{
"message": "This is log 1"
}
PUT logs_2/_doc/1
{
"message": "This is log 2"
}上面的两个命令在 cluster_1 的集群中生成两个索引: logs_1 及 logs_2。
那么我到 cluster_2 的集群的 Kibana 中来进行查看:
GET _cat/indices上面的命令显示:

我们可以看到两个新生成的索: logs_1-copy 以及 logs_2-copy。显然两个索引被自动复制。我们可以更进一步来进行查看:
GET logs*/_search上面的命令显示:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "logs_1-copy",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"message" : "This is log 1"
}
},
{
"_index" : "logs_2-copy",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"message" : "This is log 2"
}
}
]
}
}
参考:
【1】Cross-cluster replication | Elasticsearch Guide [8.4] | Elastic
【2】Cross-cluster search and security | Elasticsearch Guide [8.4] | Elastic

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)