
Zabbix5.0监控Kafka
Zabbix5.0监控Kafka1.什么是KafkaApacheKafka是一个分布式流媒体平台它主要有3种功能:1:发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因2:以容错的方式记录消息流,kafka以文件的方式来存储消息流3:可以再消息发布的时候进行处理2.使用场景1:在系统或应用程序之间构建可靠的用于传输实时数据的管道,消息队列功能2:构建实时的流数据处理
Zabbix5.0监控Kafka

1.什么是Kafka
ApacheKafka是一个分布式流媒体平台它主要有3种功能:
1:发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因
2:以容错的方式记录消息流,kafka以文件的方式来存储消息流
3:可以再消息发布的时候进行处理
2.使用场景
1:在系统或应用程序之间构建可靠的用于传输实时数据的管道,消息队列功能
2:构建实时的流数据处理程序来变换或处理数据流,数据处理功能
3.工作机制
3.1 整体架构
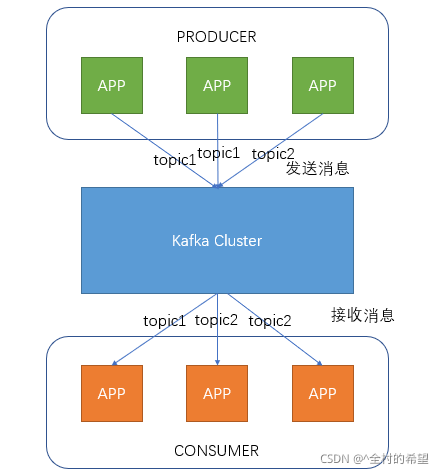
Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个producer发送了分类为topic1的消息,另外一个发送了topic2的消息。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息
Consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
从上图中就可以看出同一个Topic下的消费者和生产者的数量并不是对应的。
3.2 存储策略
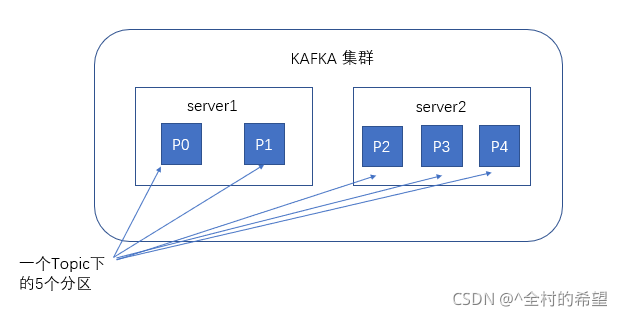
谈到kafka的存储,就不得不提到分区,即partitions,创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
3.3 生产者交互策略
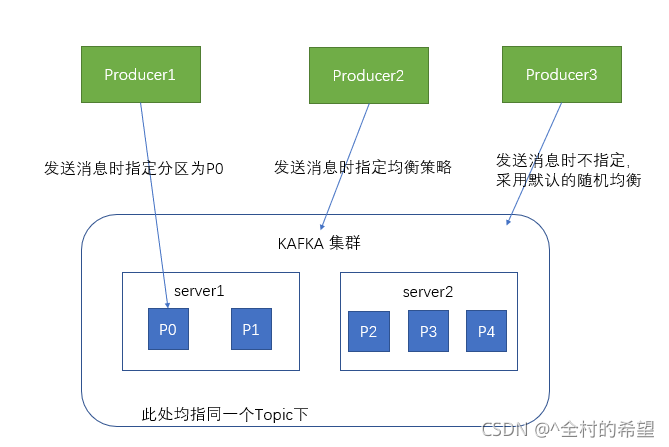
生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中,也可以通过指定均衡策略来将消息发送到不同的分区中,如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中。
3.4 消费者交互策略
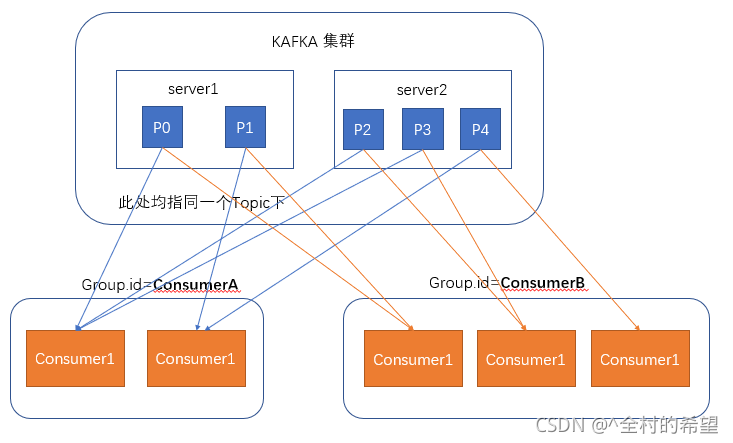
在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
4.监控指标
版本查看方法
4.1 Kafka版本查看方法
yum 安装方式在 /etc/下可以找到
Ambari + HDP 安装方式在 /usr/hdp/3.1.5.0-152/kafka
查看Kafka版本:/usr/hdp/3.1.5.0-152/kafka/libs下的文件信息即可看到
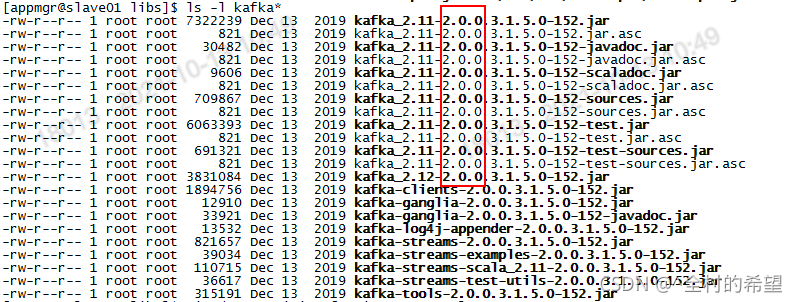
2.11是scale语言的版本
2.0.0是kafka的版本
3.1.5.0.152是hdp的版本
4.2 Kafka监控指标
AllTopicsMessagesInPerSec #所有的topic的消息速率(消息数/秒)
AllTopicsBytesInPerSec #所有的topic的流入数据速率(字节/秒)
{Produce|Fetch-consumer|Fetch-follower}-RequestsPerSec #producer或Fetch-consumer或Fetch-follower的请求速率(请求次数/秒)
AllTopicsBytesOutPerSec #所有的topic的流出数据速率(字节/秒)
LogFlushRateAndTimeMs #刷日志的速率和耗时
UnderReplicatedPartitions #正在做复制的partition的数量(|ISR| < |all replicas|)
ActiveControllerCount #当前的broker是否为controller
LeaderElectionRateAndTimeMs #选举leader的速率
UncleanLeaderElectionsPerSec #Unclean的leader选举速率
PartitionCount #该broker上的partition的数量
LeaderCount #Leader的replica的数量
ISRShrinksPerSec #ISR的收缩(shrink)速率
ISRExpandsPerSec #ISR的扩大(expansion)速率
([-.\w]+)-MaxLag #follower落后leader replica的最大的消息数量
([-.\w]+)-ConsumerLag #每个follower replica落后的消息速率
PurgatorySize #等待producer purgatory的请求数
{Produce|Fetch-Consumer|Fetch-Follower}-TotalTimeMs #一个请求(producer,Fetch-Consumer,Fetch-Follower)耗费的所有时间
{Produce|Fetch-Consumer|Fetch-Follower}-QueueTimeMs #请求(producer,Fetch-Consumer,Fetch-Follower)在请求队列中的等待时间
“{Produce|Fetch-Consumer|Fetch-Follower}-RemoteTimeMs #请求(producer,Fetch-Consumer,Fetch-Follower)等待follower花费的时间
{Produce|Fetch-Consumer|Fetch-Follower}-ResponseSendTimeMs #发送响应花费的时间
5.如何监控
5.1 开启JMX
登陆kafka服务器,修改配置
#vim bin/kafka-server-start.sh,添加JMX_PORT参数,由于bin/kafak-run-class.sh的JMX配置已经存在,只需要给一个JMX_PORT环境变量即可
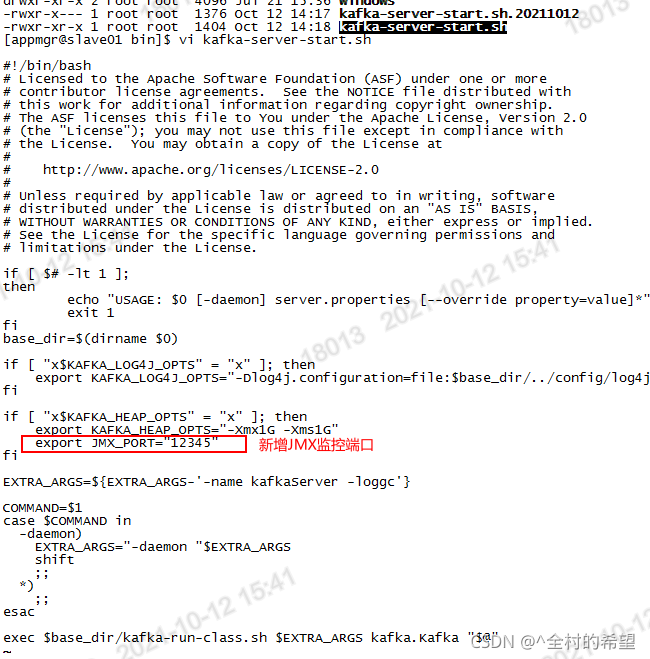
5.2 重启kafka
Kafka关闭命令(备注:先进入kafka目录)
bin/kafka-server-stop.sh
Kafka启动命令(备注:先进入kafka目录)
nohup bin/kafka-server-start.sh config/server.properties >/dev/null 2>&1 &
5.3 zabbxi server配置
5.3.1 安装java-gataway
(在安装zabbix server时就可以指定安装)
yum install -y zabbix-java-gataway
5.3.2 修改zabbix-server配置文件
vim /usr/local/zabbix/etc/zabbix_server.conf
JavaGateway=127.0.0.1
JavaGatewayPort=10052
StartJavaPollers=3
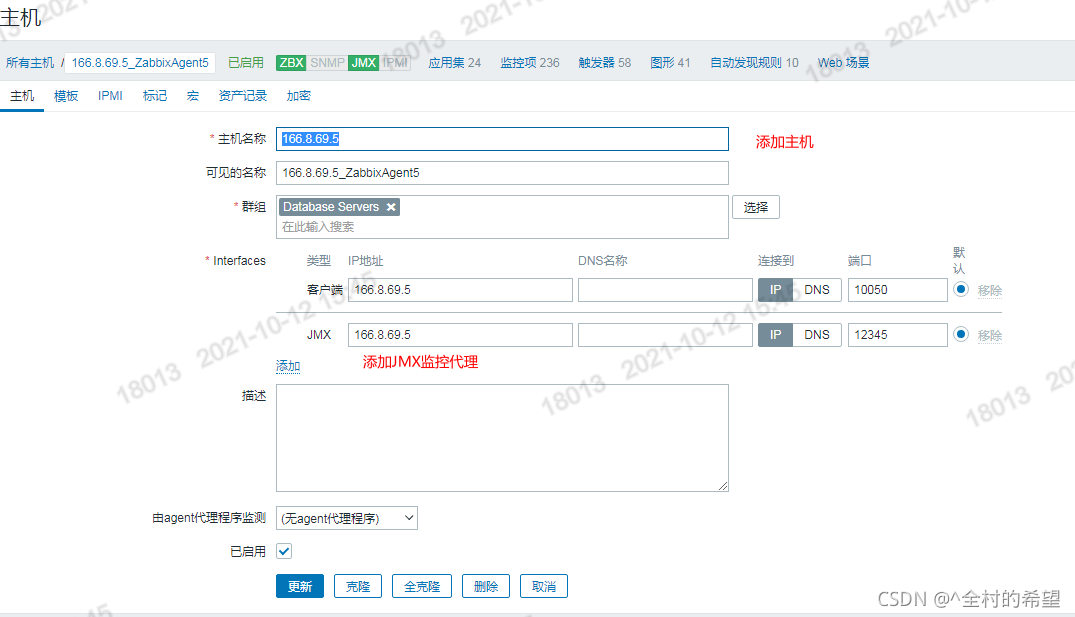
5.4 添加主机和JMX代理
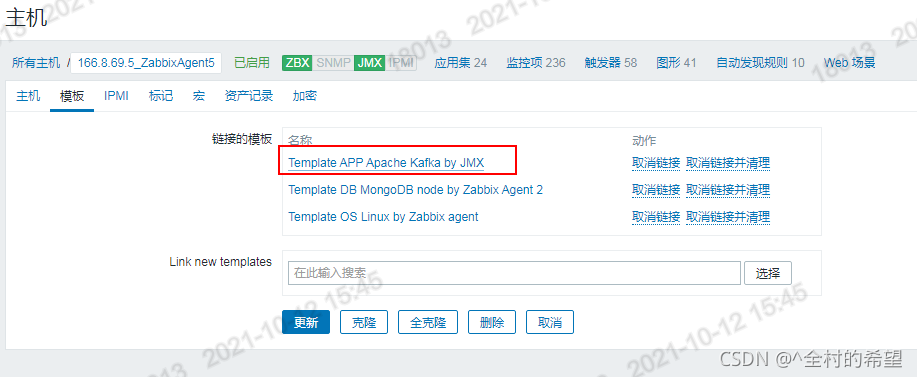
5.5 关联模板
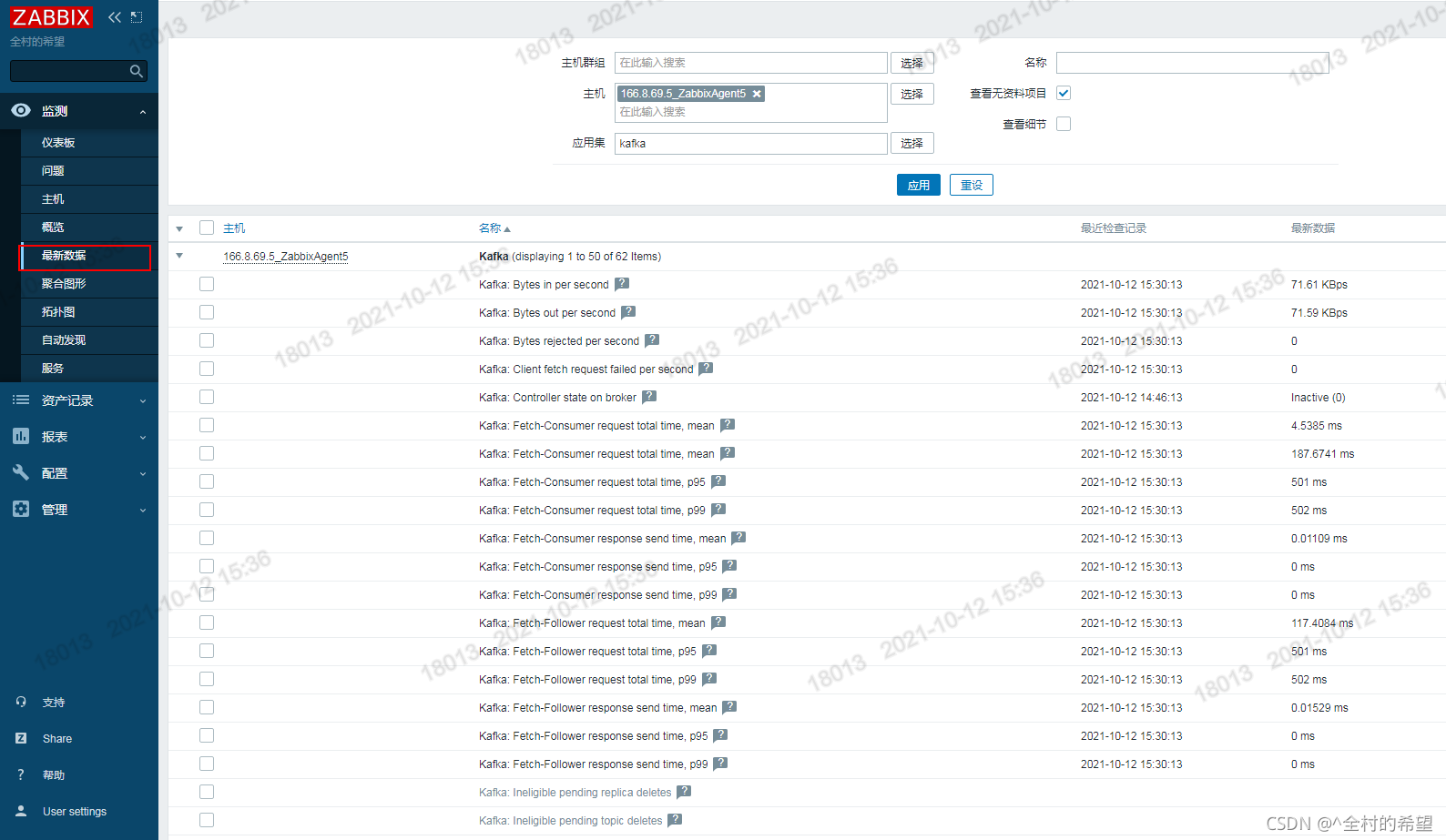
5.5 验证监控数据


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)