【PySpark】Spark Streaming:Spark的实时流计算API
Spark SQL API可以像查询关系型数据库一样查询 Spark 的数据,并且对原生数据做相应的转换和动作。但是,无论是 DataFrame API 还是 DataSet API,都是基于批处理模式对静态数据进行处理的。比如,在每天某个特定的时间对一天的日志进行处理分析。批处理和流处理是大数据处理最常见的两个场景。那么作为当下最流行的大数据处理平台之一,Spark 是否支持流处理呢?答案是肯定
Spark SQL API可以像查询关系型数据库一样查询 Spark 的数据,并且对原生数据做相应的转换和动作。
但是,无论是 DataFrame API 还是 DataSet API,都是基于批处理模式对静态数据进行处理的。比如,在每天某个特定的时间对一天的日志进行处理分析。
批处理和流处理是大数据处理最常见的两个场景。那么作为当下最流行的大数据处理平台之一,Spark 是否支持流处理呢?答案是肯定的。早在 2013 年,Spark 的流处理组件 Spark Streaming 就发布了。之后经过好几年的迭代与改进,现在的 Spark Streaming 已经非常成熟,在业界应用十分广泛。
一、Spark Streaming 的原理
流处理的数据是一系列连续不断变化,且无边界的。我们永远无法预测下一秒的数据是什么样。Spark Streaming 用时间片拆分了无限的数据流,然后对每一个数据片用类似于批处理的方法进行处理,输出的数据也是一块一块的。如下图所示。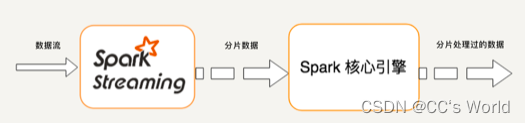
Spark Streaming 提供一个对于流数据的抽象 DStream。DStream 可以由来自 Apache Kafka、Flume 或者 HDFS 的流数据生成,也可以由别的 DStream 经过各种转换操作得来。
底层 DStream 也是由很多个序列化的 RDD 构成,按时间片(比如一秒)切分成的每个数据单位都是一个 RDD。 然后,Spark 核心引擎将对 DStream 的 Transformation 操作变为针对 Spark 中对 RDD 的 Transformation 操作,将 RDD 经过操作变成中间结果保存在内存中。
之前的 DataFrame 和 DataSet 也是同样基于 RDD,所以说 RDD 是 Spark 最基本的数据抽象。就像 Java 里的基本数据类型(Primitive Type)一样,所有的数据都可以用基本数据类型描述。
也正是因为这样,无论是 DataFrame,还是 DStream,都具有 RDD 的不可变性、分区性和容错性等特质。
所以,Spark 是一个高度统一的平台,所有的高级 API 都有相同的性质,它们之间可以很容易地相互转化。Spark 的野心就是用这一套工具统一所有数据处理的场景。由于 Spark Streaming 将底层的细节封装起来了,所以对于开发者来说,只需要操作 DStream 就行。
二、DStream
下图就是 DStream 的内部形式,即一个连续的 RDD 序列,每一个 RDD 代表一个时间窗口的输入数据流。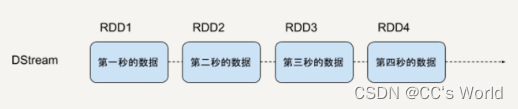
对 DStream 的转换操作,意味着对它包含的每一个 RDD 进行同样的转换操作。比如下边的例子。
sc = SparkContext(master, appName)
ssc = StreamingContext(sc, 1)
lines = sc.socketTextStream("localhost", 9999)
words = lines.flatMap(lambda line: line.split(" "))
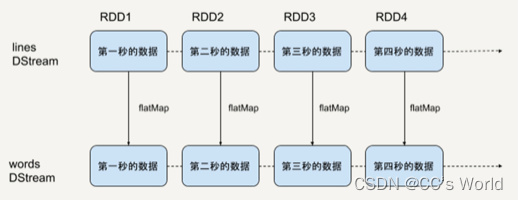
首先,我们创建了一个 lines 的 DStream,去监听来自本机 9999 端口的数据流,每一个数据代表一行文本。
然后,对 lines 进行 flatMap 的转换操作,把每一个文本行拆分成词语。本质上,对一个 DStream 进行 flatMap 操作,就是对它里边的每一个 RDD 进行 flatMap 操作,生成了一系列新的 RDD,构成了一个新的代表词语的 DStream。
正因为 DStream 和 RDD 的关系,RDD 支持的所有转换操作,DStream 都支持,比如 map、flatMap、filter、union 等。此外,DStream 还有一些特有操作,如滑动窗口操作。
三、滑动窗口操作
任何 Spark Streaming 的程序都要首先创建一个 StreamingContext 的对象,它是所有 Streaming 操作的入口。
比如,我们可以通过 StreamingContext 来创建 DStream。前边提到的例子中,lines 这个 DStream 就是由名为 sc 的 StreamingContext 创建的。
StreamingContext 中最重要的参数是批处理的时间间隔,即把流数据细分成数据块的粒度。
这个时间间隔决定了流处理的延迟性,所以,需要我们根据需求和资源来权衡间隔的长度。上边的例子中,我们把输入的数据流以秒为单位划分,每一秒的数据会生成一个 RDD 进行运算。
有些场景中,我们需要每隔一段时间,统计过去某个时间段内的数据。比如,对热点搜索词语进行统计,每隔 10 秒钟输出过去 60 秒内排名前十位的热点词。这是流处理的一个基本应用场景,很多流处理框架如 Apache Flink 都有原生的支持。所以,Spark 也同样支持滑动窗口操作。
从统计热点词这个例子,你可以看出滑动窗口操作有两个基本参数:
- 窗口长度(window length):每次统计的数据的时间跨度,在例子中是 60 秒;
- 滑动间隔(sliding interval):每次统计的时间间隔,在例子中是 10 秒。
显然,由于 Spark Streaming 流处理的最小时间单位就是 StreamingContext 的时间间隔,所以这两个参数一定是它的整数倍。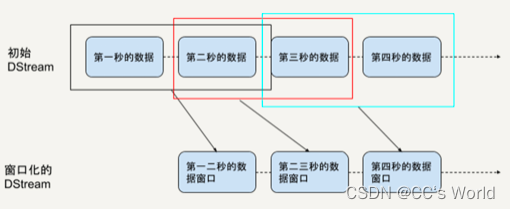
最基本的滑动窗口操作是 window,它可以返回一个新的 DStream,这个 DStream 中每个 RDD 代表一段时间窗口内的数据,如下例所示。
windowed_words = words.window(60, 10)
windowed_words 代表的就是热词统计例子中我们所需的 DStream,即它里边每一个数据块都包含过去 60 秒内的词语,而且这样的块每 10 秒钟就会生成一个。
此外,Spark Streaming 还支持一些“进阶”窗口操作。如 countByWindow、reduceByWindow、reduceByKeyAndWindow 和 countByValueAndWindow。
四、Spark Streaming 的优缺点
Spark Streaming 的优点很明显,由于它的底层是基于 RDD 实现的,所以 RDD 的优良特性在它这里都有体现。比如,数据容错性,如果 RDD 的某些分区丢失了,可以通过依赖信息重新计算恢复。再比如运行速度,DStream 同样也能通过 persist() 方法将数据流存放在内存中。这样做的好处是遇到需要多次迭代计算的程序时,速度优势十分明显。而且,Spark Streaming 是 Spark 生态的一部分。所以,它可以和 Spark 的核心引擎、Spark SQL、MLlib 等无缝衔接。换句话说,对实时处理出来的中间数据,我们可以立即在程序中无缝进行批处理、交互式查询等操作。这个特点大大增强了 Spark Streaming 的优势和功能,使得基于 Spark Streaming 的应用程序很容易扩展。
而 Spark Streaming 的主要缺点是实时计算延迟较高,一般在秒的级别。这是由于 Spark Streaming 不支持太小的批处理的时间间隔。我们讲过准实时和实时系统,无疑 Spark Streaming 是一个准实时系统。别的流处理框架,如 Storm 的延迟性就好很多,可以做到毫秒级。
参考资料

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)