ElasticSearch学习(一)CentOS 搭建 ElasticSearch 环境
一、安装包下载下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.4.tar.gz二、安装Elasticsearch1、创建目录,一般情况我都安装在opt目录下# mkdir elasticsearch2、进入elasticsearch,上传刚才下载的安装包,接着解压# ......
一 简介
1.1 基础概念
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
1.2 分布式数据库
布式数据库系统通常使用较小的计算机系统,每台计算机可单独放在一个地方,每台计算机中都可能有DBMS的一份完整拷贝副本,或者部分拷贝副本,并具有自己局部的数据库,位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的逻辑上集中、物理上分布的大型数据库。
1.3 核心角色
1.3.1 集群和节点
cluster代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
1.3.2 Shards分片
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
1.3.3 Document文档
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示。
1.3.4 Index索引
Elastic 会索引所有字段,查找数据的时候,直接查找该索引。每个 Index (即理解为数据库名称)的名字必须是小写。
1.3.5 Type类型
Document 可以根据Type进行虚拟的逻辑分组,用来过滤 Document。
二 安装包下载
下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.4.tar.gz
三 安装单机版 Elasticsearch
3.1 创建目录,一般情况我都安装在opt目录下
# mkdir elasticsearch3.2 进入elasticsearch,上传刚才下载的安装包,接着解压
# cd elasticsearch
# tar -zxvf elasticsearch-6.5.4.tar.gz3.3 进入elasticsearch-6.5.4目录,创建两个data和logs文件夹
# cd elasticsearch-6.5.4
# mkdir data
# mkdir logs3.4 用pwd命令查看目录,进入config,然后vi进入elasticsearch.yml,进行配置
# pwd
# /opt/elasticsearch/elasticsearch-6.5.4/config
# vi elasticsearch.yml3.5 修改elasticsearch.yml配置项
# ---------------------------------- Cluster -----------------------------------
cluster.name: my-application
# ------------------------------------ Node ------------------------------------
node.name: node-1
# ----------------------------------- Paths ------------------------------------
path.data: /opt/elasticsearch/elasticsearch-6.5.4/data
path.logs: /opt/elasticsearch/elasticsearch-5.5.4/logs
# ----------------------------------- Memory -----------------------------------
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# ---------------------------------- Network -----------------------------------
network.host: 192.168.1.102
# --------------------------------- Discovery ----------------------------------
discovery.zen.ping.unicast.hosts: ["192.168.1.102"]
discovery.zen.minimum_master_nodes: 1 #注意,因为本人目前是单节点,这里必须为1
transport.tcp.port: 9300
transport.tcp.compress: true
3.6 配置linux系统环境,命令:vi /etc/security/limits.conf
在末尾添加如下:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
3.7 修改配置sysctl.conf,命令:vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360并执行命令:sysctl -p
注意:elasticsearch不能用root用户启动,需要创建一个普通用户去启动
3.8 创建普通用户,给es用户授权,以便访问elasticsearch目录
# 创建用户
adduser es 或者 useradd es
# 给用户设置密码
passwd es
# 文件件所有者
chown -R es:es /opt/elasticsearch
# 如果错了,可以删除在加
userdel -r es
注意:修改密码会有复杂性检查,不必理会,输入两遍密码就会成功
3.9 切换到es用户,启动elasticsearch
# su es
# bin/elasticsearch -d注意:切换到es用户,需要属于密码,属于刚才创建的es密码,然后执行启动命令:bin/elasticsearch,看到如下启动成功
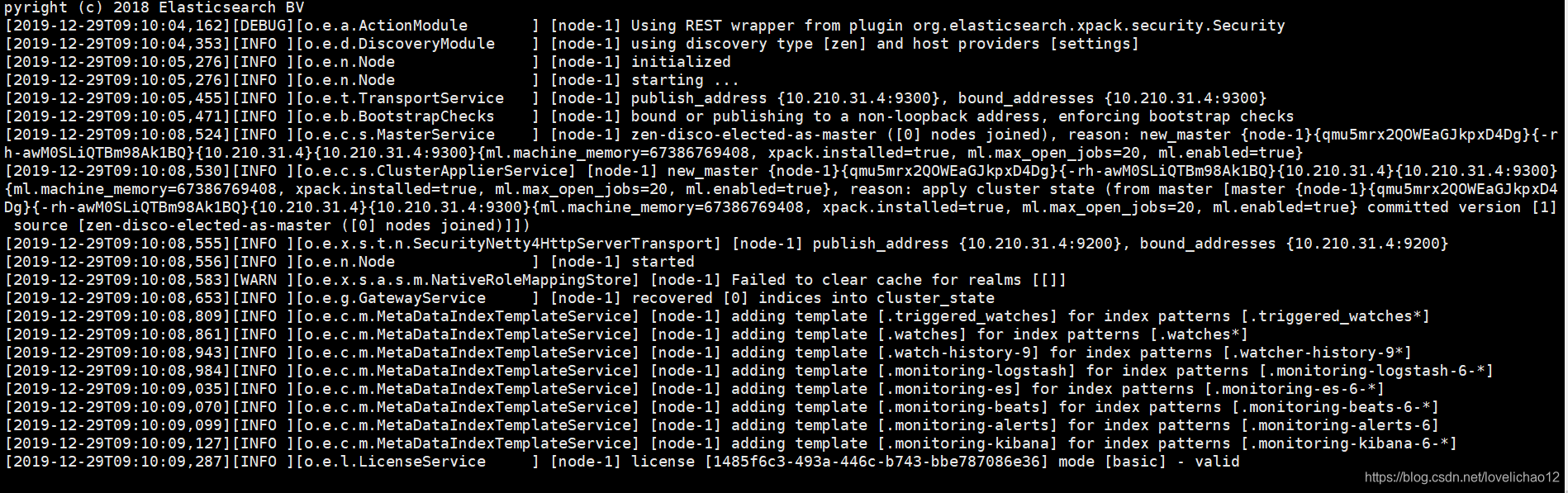
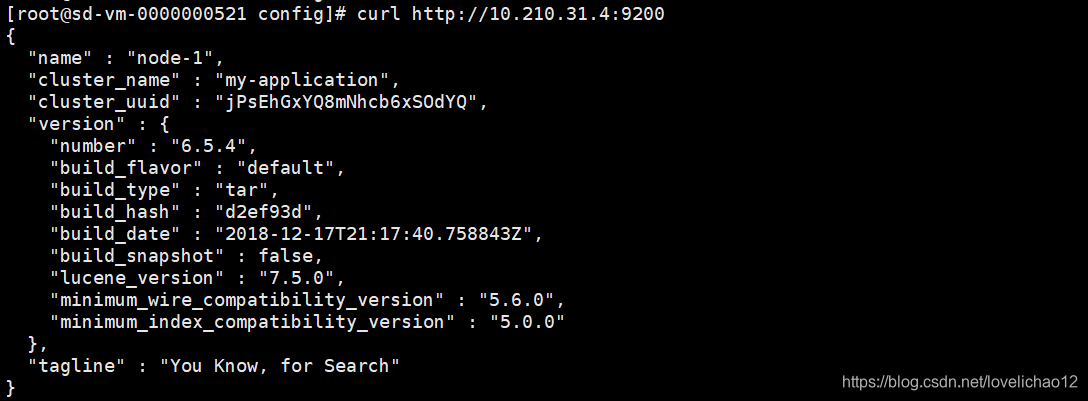
3.10 测试elasticsearch
四 安装集群 Elasticsearch
搭建集群elasticsearch也是比较简单,就是配置文件比较复杂一点,一般情况3台以上称之为集群,所以准备3个节点,按照如上单机版步骤完成安装,然后分别进入3个节点,修改3台 elasticsearch.yml 配置文件,如下:
4.1 修改 elasticsearch.yml 配置文件
节点1
## 集群名称,各节点统一
cluster.name: cluster-es
## 节点名称,每个节点名称不能重复
node.name: node-1
## 数据和日志存放路径
path.data: /data/elasticsearch/esdata/
path.logs: /data/elasticsearch/eslogs/
## 锁定物理内存地址,防止es内存被交换出去 ,需要配置ulimit参数参考前一篇安装文档
bootstrap.memory_lock: true
## 启动进行系统检测
bootstrap.system_call_filter: false
## 绑定IP地址,每个地址不能重复
network.host: 172.20.0.101
http.port: 9200
## 节点间交互的tcp 端口
transport.tcp.port: 9300
## 是不是有资格主节点
node.master : true
node.data : true
## 集群节点
discovery.zen.ping.unicast.hosts: ["172.20.0.101:9300", "172.20.0.102:9300", "172.20.0.103:9300"]
## 集群节点quorum数量,建议设置为(候选主节点数 / 2) + 1
discovery.zen.minimum_master_nodes: 2
## 是否支持跨域 和允许的域范围,默认为* 所有,可用正则匹配
http.cors.enabled: true
http.cors.allow-origin: "*"
## 禁用xpack安全机制
xpack.security.enabled: false
## 是否开启监控
xpack.monitoring.enabled: true
## 收集集群统计信息的超时。默认为10s
xpack.monitoring.collection.cluster.stats.timeout: 10s
## index 缓冲区大小
indices.memory.index_buffer_size: 20%
## 传输流量最大值
indices.recovery.max_bytes_per_sec: 10000mb
## 节点fielddata 的最大内存,达到则交换旧数据,建议设置小一点
indices.fielddata.cache.size: 10%
## fielddata限制大小,一定要大于cache 大小
indices.breaker.fielddata.limit: 60%
## request数量使用内存限制,默认为JVM堆的40%
indices.breaker.request.limit: 60%
所有breaker使用的内存值,默认值为 JVM 堆内存的70%,当内存达到最高值时会触发内存回收
indices.breaker.total.limit: 80%
## 动作自动创建索引
action.auto_create_index: true节点2
## 集群名称,各节点统一
cluster.name: cluster-es
## 节点名称,每个节点名称不能重复
node.name: node-2
## 数据和日志存放路径
path.data: /data/elasticsearch/esdata/
path.logs: /data/elasticsearch/eslogs/
## 锁定物理内存地址,防止es内存被交换出去 ,需要配置ulimit参数参考前一篇安装文档
bootstrap.memory_lock: true
## 启动进行系统检测
bootstrap.system_call_filter: false
## 绑定IP地址,每个地址不能重复
network.host: 172.20.0.102
http.port: 9200
## 节点间交互的tcp 端口
transport.tcp.port: 9300
## 是不是有资格主节点
node.master : true
node.data : true
## 集群节点
discovery.zen.ping.unicast.hosts: ["172.20.0.101:9300", "172.20.0.102;9300", "172.20.0.103:9300"]
## 集群节点quorum数量,建议设置为(候选主节点数 / 2) + 1
discovery.zen.minimum_master_nodes: 2
## 是否支持跨域 和允许的域范围,默认为* 所有,可用正则匹配
http.cors.enabled: true
http.cors.allow-origin: "*"
## 禁用xpack安全机制
xpack.security.enabled: false
## 是否开启监控
xpack.monitoring.enabled: true
## 收集集群统计信息的超时。默认为10s
xpack.monitoring.collection.cluster.stats.timeout: 10s
## index 缓冲区大小
indices.memory.index_buffer_size: 20%
## 传输流量最大值
indices.recovery.max_bytes_per_sec: 10000mb
## 节点fielddata 的最大内存,达到则交换旧数据,建议设置小一点
indices.fielddata.cache.size: 10%
## fielddata限制大小,一定要大于cache 大小
indices.breaker.fielddata.limit: 60%
## request数量使用内存限制,默认为JVM堆的40%
indices.breaker.request.limit: 60%
所有breaker使用的内存值,默认值为 JVM 堆内存的70%,当内存达到最高值时会触发内存回收
indices.breaker.total.limit: 80%
## 动作自动创建索引
action.auto_create_index: true节点3
## 集群名称,各节点统一
cluster.name: cluster-es
## 节点名称,每个节点名称不能重复
node.name: node-3
## 数据和日志存放路径
path.data: /data/elasticsearch/esdata/
path.logs: /data/elasticsearch/eslogs/
## 锁定物理内存地址,防止es内存被交换出去 ,需要配置ulimit参数参考前一篇安装文档
bootstrap.memory_lock: true
## 启动进行系统检测
bootstrap.system_call_filter: false
## 绑定IP地址,每个地址不能重复
network.host: 172.20.0.103
http.port: 9200
## 节点间交互的tcp 端口
transport.tcp.port: 9300
## 是不是有资格主节点
node.master : true
node.data : true
## 集群节点
discovery.zen.ping.unicast.hosts: ["172.20.0.101:9300", "172.20.0.102:9300", "172.20.0.103:9300"]
## 集群节点quorum数量,建议设置为(候选主节点数 / 2) + 1
discovery.zen.minimum_master_nodes: 2
## 是否支持跨域 和允许的域范围,默认为* 所有,可用正则匹配
http.cors.enabled: true
http.cors.allow-origin: "*"
## 禁用xpack安全机制
xpack.security.enabled: false
## 是否开启监控
xpack.monitoring.enabled: true
## 收集集群统计信息的超时。默认为10s
xpack.monitoring.collection.cluster.stats.timeout: 10s
## index 缓冲区大小
indices.memory.index_buffer_size: 20%
## 传输流量最大值
indices.recovery.max_bytes_per_sec: 10000mb
## 节点fielddata 的最大内存,达到则交换旧数据,建议设置小一点
indices.fielddata.cache.size: 10%
## fielddata限制大小,一定要大于cache 大小
indices.breaker.fielddata.limit: 60%
## request数量使用内存限制,默认为JVM堆的40%
indices.breaker.request.limit: 60%
所有breaker使用的内存值,默认值为 JVM 堆内存的70%,当内存达到最高值时会触发内存回收
indices.breaker.total.limit: 80%
## 动作自动创建索引
action.auto_create_index: true4.2 主节点
一个节点启动后,就会使用Zen Discovery机制去寻找集群中的其他节点,并与之建立连接。集群中会从候选主节点中选举出一个主节点,主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch中的主节点的工作量相对较轻,用户的请求可以发往任何一个节点,由该节点负责分发和返回结果,而不需要经过主节点转发。
正常情况下,集群中的所有节点,应该对主节点的选择是一致的,即一个集群中只有一个选举出来的主节点。然而,在某些情况下,比如网络通信出现问题、主节点因为负载过大停止响应等等,就会导致重新选举主节点,此时可能会出现集群中有多个主节点的现象,即节点对集群状态的认知不一致,称之为脑裂现象。为了尽量避免此种情况的出现,可以通过discovery.zen.minimum_master_nodes来设置最少可工作的候选主节点个数,建议设置为(候选主节点数 / 2) + 1, 比如,当有三个候选主节点时,该配置项的值为(3/2)+1=2,也就是保证集群中有半数以上的候选主节点。 候选主节点的设置方法是设置node.mater为true,默认情况下,node.mater和node.data的值都为true,即该节点既可以做候选主节点也可以做数据节点。由于数据节点承载了数据的操作,负载通常都很高,所以随着集群的扩大,建议将二者分离,设置专用的候选主节点。当我们设置node.data为false,就将节点设置为专用的候选主节点了。
主节点配置:node.mater:true node.data=false
从节点配置:node.mater:false node.data=true
4.3 查看节点
地址:http://ip地址:9200/_cat/nodes
五 kibana搭建
5.1 下载kibana安装包
下载地址:https://artifacts.elastic.co/downloads/kibana/kibana-6.5.4-linux-x86_64.tar.gz
5.2 新建目录,上传安装包,然后解压
# cd /opt
# mkdir kibana
# tar -zxvf kibana-6.5.4-linux-x86_64.tar.gz5.3 修改kibana中的config/ kibana.yml文件
# server.host: "10.210.31.4"
# server.port: 5601
# elasticsearch.url: "http://10.210.31.4:9200"
# kibana.index: ".kibana"
5.4 启动kibana
# bin/kibana &5.5 退出kibana
exit;
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)