SpringBoot-Kafka(生产者事务、手动提交offset、定时消费、消息转发、过滤消息内容、自定义分区器、提高吞吐量)
pom.xml<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.6.0</version></dependency>
代码已上传码云
pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.0</version>
</dependency>
yml
server:
port: 8999
servlet:
context-path: /hello
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
# 发生错误后,消息重发的次数 ,0为不启用重试机制,默认int最大值
retries: 3
# 当有多个消息需要被发送到统一分区时,生产者会把他们放在同一批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算
batch-size: 16384
# 生产者可以使用的总内存字节来缓冲等待发送到服务器的记录
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks 应答机制
# acks=0 : 生产者发送过来的数据,不需要等数据落盘应答。
# acks=1 : 生产者发送过来的数据,Leader 收到数据后应答。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: -1
properties:
# 批量发送,延迟为1毫秒,启用该功能能有效减少生产者发送消息次数,从而提高并发量
linger.ms: 1
# 对发送的数据进行压缩 支持压缩类型:none、gzip、snappy、lz4 和 zstd。
partitioner.class: com.yh.kafka.config.CustomizePartitioner
compression-type: "snappy"
# 开启事务
transaction-id-prefix: myapp
consumer:
group-id: mykafka1
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 自动提交的时间间隔 在Spring Boot 2.x 版本中这里采用的值的类型Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1s
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
# none(如果无offset就抛出异常)
auto-offset-reset: earliest
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 这个参数允许消费者指定从broker读取消息时最小的Payload的字节数。当消费者从broker读取消息时,如果数据字节数小于这个阈值,broker会等待直到有足够的数据,然后才返回给消费者。对于写入量不高的主题来说,这个参数可以减少broker和消费者的压力,因为减少了往返的时间。而对于有大量消费者的主题来说,则可以明显减轻broker压力。
fetch-min-size: 1 #默认值: 1
#上面的fetch.min.bytes参数指定了消费者读取的最小数据量,而这个参数则指定了消费者读取时最长等待时间,从而避免长时间阻塞。这个参数默认为500ms。
fetch-max-wait: 500
# 这个参数控制一个poll()调用返回的记录数,即consumer每次批量拉多少条数据。
max-poll-records: 500
listener:
# 在监听器容器中运行的线程数,创建多少个consumer,值必须小于等于Kafk Topic的分区数。
concurrency: 1 # 推荐设置为topic的分区数
# 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
# RECORD
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# BATCH
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT
# TIME | COUNT 有一个条件满足时提交
# COUNT_TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
# 消费监听接口监听的主题不存在时,默认会报错
missing-topics-fatal: false
# 使用批量消费需要将listener的type设置为batch,该值默认为single
#type: batch
简单生产消费示例
生产者
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
// 发送消息
@GetMapping("/send")
public void sendMessage1(String msg) {
kafkaTemplate.send("first", msg);
// kafkaTemplate.send(topic, 1, "2" , msg);
}
消费者
@Component
public class consumer {
@KafkaListener(topics = {"first"})
public void listen(ConsumerRecord<?, ?> record){
// 消费的哪个topic、partition的消息,打印出消息内容
System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}
生产者
带回调的生产者
@RequestMapping("/send")
public void send(String msg) {
kafkaTemplate.send(topic, msg).addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送消息失败:" + ex.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("发送消息成功:" + result.getRecordMetadata().topic() + "-"
+ result.getRecordMetadata().partition() + "-" + result.getRecordMetadata().offset());
}
});
}
生产者事务
/**
* 生产者事务发送:需配置transaction-id-prefix开启事务
*
* @param msg 消息内容
* @author yh
* @date 2022/5/11
*/
@Transactional
@RequestMapping("/transaction")
public void transaction(String msg) {
kafkaTemplate.send(topic, msg);
int a = 1 / 0;
kafkaTemplate.send(topic, "_____" + msg);
}
不配置transaction-id-prefix,接收到一条消息
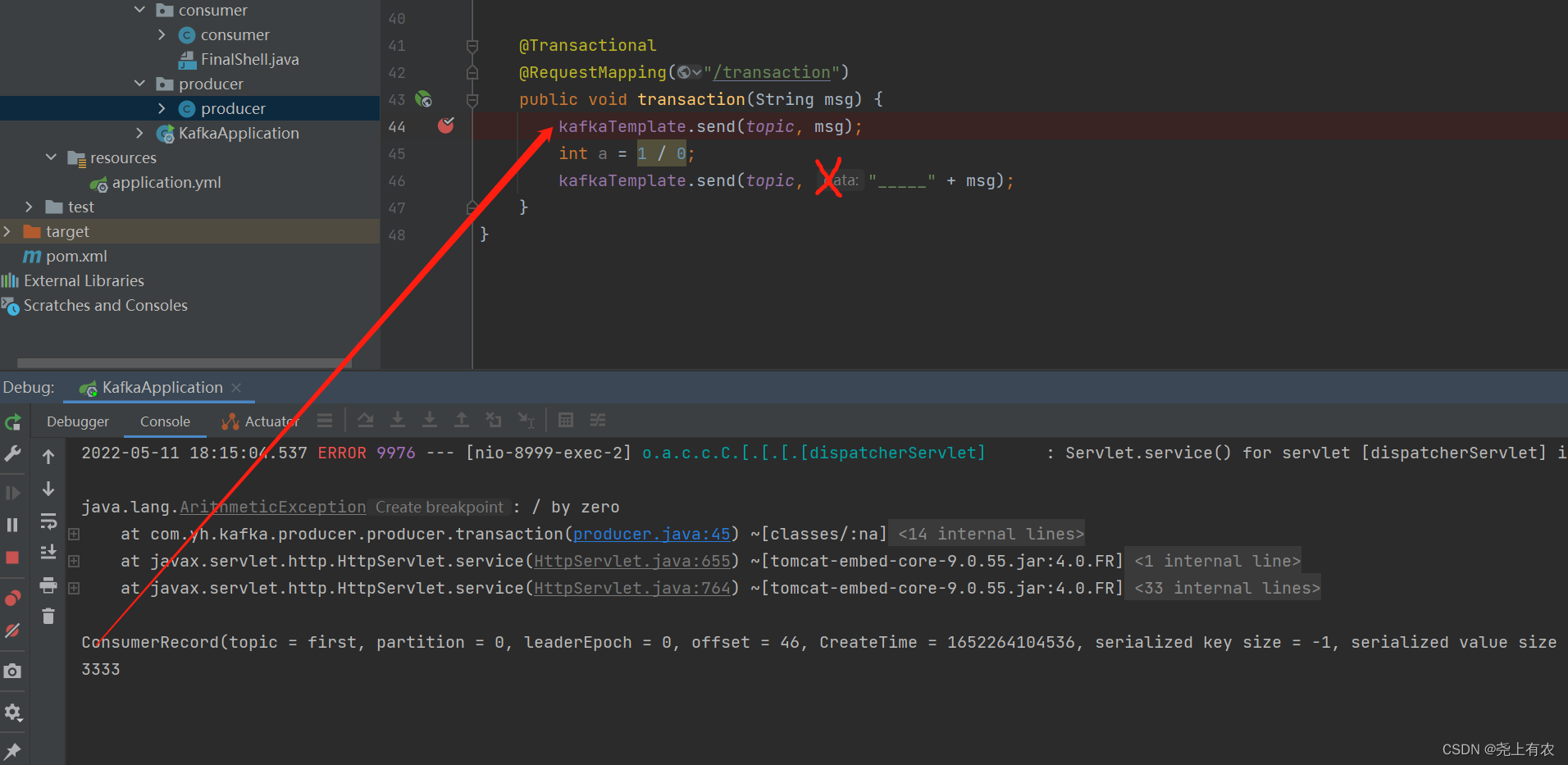
开启事务,一条也没收到
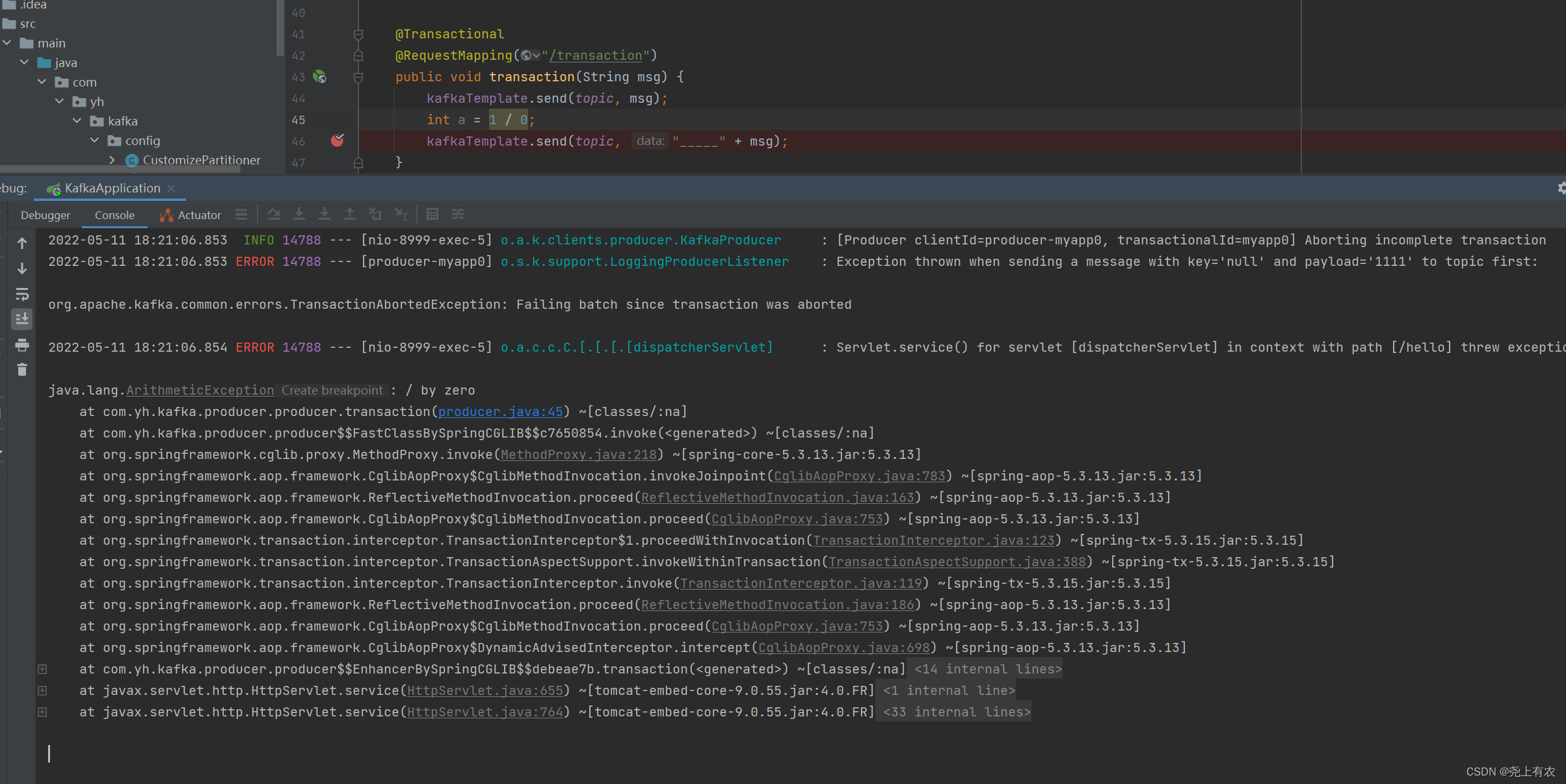
/**
* 第二种事务发送
*
* @param msg 消息内容
* @author yh
* @date 2022/5/11
*/
@RequestMapping("/transaction2")
public void transaction2(String msg) {
kafkaTemplate.executeInTransaction(new KafkaOperations.OperationsCallback() {
@Override
public Object doInOperations(KafkaOperations kafkaOperations) {
kafkaOperations.send(topic, msg);
int a = 1 / 0;
return true;
}
});
}
模拟消费异常,没有发送成功
自定义分区器
/**
* @description 自定义分区规则,需要在配置中指定当前类生效
* @auth yh
* @date 2022/5/11
*/
public class CustomizePartitioner implements Partitioner {
@Override
public int partition(String topic, Object o, byte[] bytes, Object value, byte[] bytes1, Cluster cluster) {
String msg = value.toString();
int partition = 0;
// 消息种包含hello,就发往1号分区
if(msg.contains("hello")){
partition = 1;
}
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
消费者
手动提交offset
/**
* 声明consumerID为demo,方便kafkaserver打印日志定位请求来源,监听topicName为topic.quick.demo的Topic
* clientIdPrefix设置clientId前缀, idIsGroup id为groupId:默认为true
* concurrency: 在监听器容器中运行的线程数,创建多少个consumer,值必须小于等于Kafk Topic的分区数。大于分区数时会有部分线程空闲
* topicPattern 匹配Topic进行监听(与topics、topicPartitions 三选一)
*
* @param record 消息内容
* @param ack 应答
* @author yh
* @date 2022/5/10
*/
@KafkaListener(id = "demo", topics = "first", groupId = "mykafka2", idIsGroup = false, clientIdPrefix = "myClient1", concurrency = "${listen.concurrency:3}")
public void listen(ConsumerRecord<String, String> record, Acknowledgment ack) {
System.out.println(record);
System.out.println(record.value());
// 消息处理下游绑定事务,成功消费后提交ack
// 手动提交offset
ack.acknowledge();
}
指定offset位置消费
/**
* 指定offset位置消费
* @param record
* @param ack
* @author yh
* @date 2022/5/11
*/
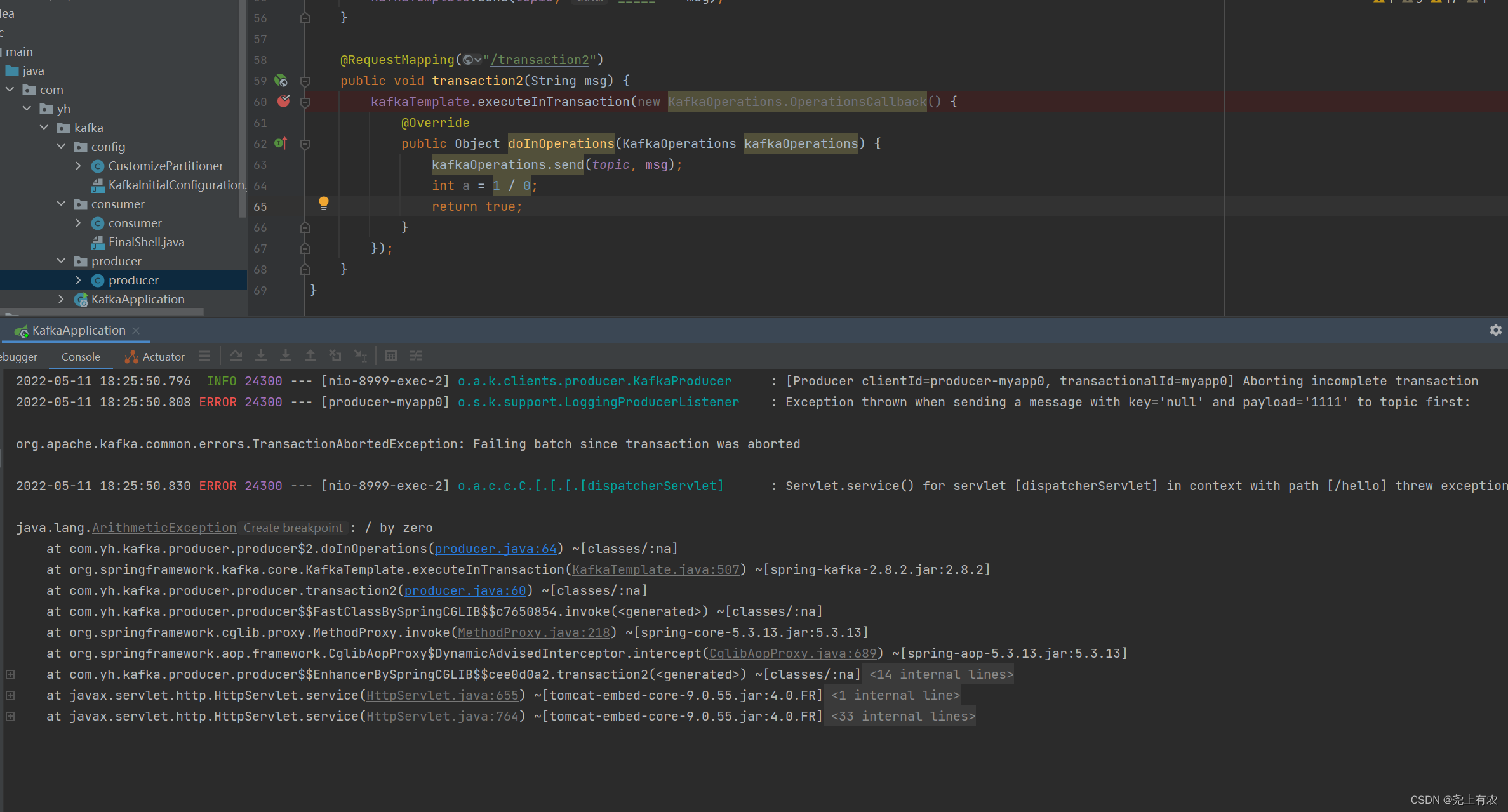
@KafkaListener(topicPartitions = {
@TopicPartition(topic = "first", partitionOffsets = {
@PartitionOffset(partition = "0", initialOffset = "0")
}),
})
public void listen2(ConsumerRecord<String, String> record, Acknowledgment ack) {
System.out.println(record.value());
ack.acknowledge();
}
批量消费
/**
* 指定offset位置消费
* 批量消费需配置 listener.type: batch
* @param record
* @param ack
* @author yh
* @date 2022/5/11
*/
@KafkaListener(topicPartitions = {
@TopicPartition(topic = "first", partitionOffsets = {
@PartitionOffset(partition = "0", initialOffset = "0")
}),
})
public void listen3(List<String> record, Acknowledgment ack) {
// public void listen3(List<ConsumerRecord<String, String>> record, Acknowledgment ack) {
System.out.println(record);
ack.acknowledge();
}

过滤消息内容再进行消费(消费异常处理器)
/**
* 通过 containerFactory过滤消息,批量消费
* 消费异常处理器
*
* @param record
* @param ack
* @author yh
* @date 2022/5/11
*/
@KafkaListener(topicPartitions = {
@TopicPartition(topic = "first", partitionOffsets = {
@PartitionOffset(partition = "0", initialOffset = "0")
}),
}, errorHandler = "myConsumerAwareErrorHandler", containerFactory = "filterContainerFactory2")
public void listen3(List<ConsumerRecord<String, String>> record, Acknowledgment ack) {
System.out.println(record);
ack.acknowledge();
}
通过异常处理器,处理consumer在消费时发生的异常。
新建一个 ConsumerAwareListenerErrorHandler 类型的异常处理方法,用@Bean注入,BeanName默认就是方法名,然后我们将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面,当监听抛出异常的时候,则会自动调用异常处理器,
myConsumerAwareErrorHandler.java
/**
* @description 消费异常处理器
* @auth yh
* @date 2022/5/11
*/
@Component
public class ListenerErrorHandler {
/**
* 异常处理器
* @author yh
* @date 2022/5/11
*/
@Bean
public ConsumerAwareListenerErrorHandler myConsumerAwareErrorHandler() {
return new ConsumerAwareListenerErrorHandler() {
@Override
public Object handleError(Message<?> message, ListenerExecutionFailedException exception,
Consumer<?, ?> consumer) {
System.out.println("--- 发生消费异常 ---");
System.out.println(message.getPayload());
System.out.println(exception);
return null;
}
};
}
}
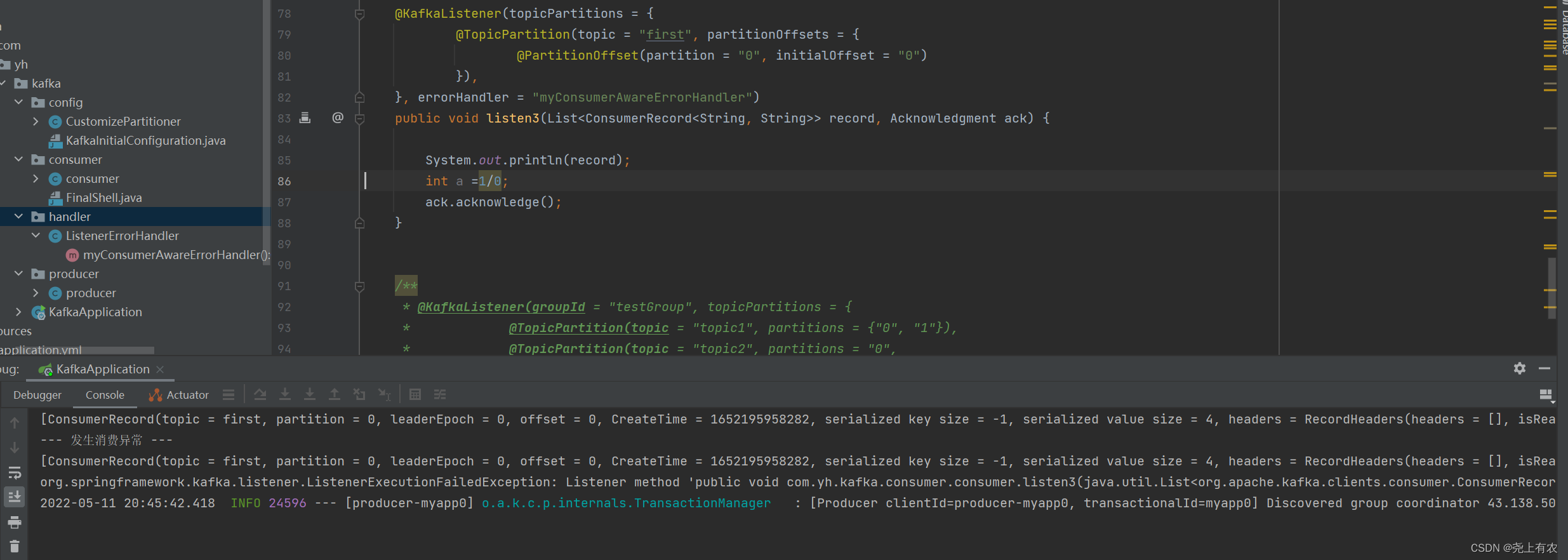
消息过滤器
/**
* @description 消息过滤器
* @auth yh
* @date 2022/5/11
*/
@Component
public class KafkaConsumerFilter {
@Autowired
ConsumerFactory consumerFactory;
/**
* 手动提交的监听器工厂 (使用的消费组工厂必须 kafka.consumer.enable-auto-commit = false)
*/
@Bean("filterContainerFactory2")
public ConcurrentKafkaListenerContainerFactory filterContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
factory.setConsumerFactory(consumerFactory);
//设置提交偏移量的方式 当Acknowledgment.acknowledge()侦听器调用该方法时,立即提交偏移量
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
// 被过滤的消息将被丢弃
factory.setAckDiscarded(true);
factory.setBatchListener(true);
// 消息过滤策略
factory.setRecordFilterStrategy(consumerRecord -> {
if (consumerRecord.value().toString().hashCode() % 2 == 0) {
return false;
}
//返回true消息则被过滤
return true;
});
return factory;
}
/**
* 监听器工厂 批量消费
* @return
*/
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
factory.setBatchListener(true);
return factory;
}
}
消息转发
/**
* 消息处理后转发到另一个topic
* @author yh
* @date 2022/5/11
* @return
*/
@KafkaListener(topicPartitions = {
@TopicPartition(topic = "first", partitionOffsets = {
@PartitionOffset(partition = "0", initialOffset = "0")
}),
})
@SendTo("two")
public String listen4(ConsumerRecord<String, String> record, Acknowledgment ack) {
System.out.println("topic--first:" + record.value());
// int a =1/0;
ack.acknowledge();
return record.value();
}
@KafkaListener(topics = "two")
public void listentwo(ConsumerRecord<String, String> record, Acknowledgment ack){
System.out.println("topic--two接收消息" + record.value());
ack.acknowledge();
}
定时启动、停止监听器
新建一个定时任务类,用注解@EnableScheduling声明,KafkaListenerEndpointRegistry 在SpringIO中已经被注册为Bean,直接注入,设置禁止KafkaListener自启动
/**
* @description
* @auth yh
* @date 2022/5/11
*/
@EnableScheduling
@Component
public class CronTimer {
/**
* @KafkaListener注解所标注的方法并不会在IOC容器中被注册为Bean,
* 而是会被注册在KafkaListenerEndpointRegistry中,
* 而KafkaListenerEndpointRegistry在SpringIOC中已经被注册为Bean
**/
@Autowired
private KafkaListenerEndpointRegistry registry;
@Autowired
private ConsumerFactory consumerFactory;
// 监听器容器工厂(设置禁止KafkaListener自启动)
@Bean
public ConcurrentKafkaListenerContainerFactory delayContainerFactory() {
ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory();
container.setConsumerFactory(consumerFactory);
//禁止KafkaListener自启动
container.setAutoStartup(false);
return container;
}
/**
* 定时启动监听器
* @param
* @author yh
* @date 2022/5/11
* @return
*/
@Scheduled(cron = "*/10 * * * * ?")
public void startListener() {
System.out.println("启动监听器..." + DateUtil.date());
// "timingConsumer"是@KafkaListener注解后面设置的监听器ID,标识这个监听器
if (!registry.getListenerContainer("timingConsumer").isRunning()) {
registry.getListenerContainer("timingConsumer").start();
}
//registry.getListenerContainer("timingConsumer").resume();
}
/**
* 定时停止监听器
* @param
* @author yh
* @date 2022/5/11
* @return
*/
@Scheduled(cron = "* 1 * * * ?")
public void shutDownListener() {
System.out.println("关闭监听器..." + DateUtil.date());
registry.getListenerContainer("timingConsumer").pause();
}
}
消费者
/**
* 定时监听器消费
* @param record
* @author yh
* @date 2022/5/11
* @return
*/
@KafkaListener(id = "timingConsumer", topicPartitions = {
@TopicPartition(topic = "first", partitionOffsets = {
@PartitionOffset(partition = "0", initialOffset = "0")
}),
},containerFactory = "delayContainerFactory")
public void onMessage1(ConsumerRecord<?, ?> record){
System.out.println("消费成功:"+record.topic()+"-"+record.partition()+"-"+record.value() + "__" + DateUtil.date());
}
生产者如何提高吞吐量
增加分区
# 批次大小,默认 16K
batch-size: 16384
# 等待时间,默认 0
linger.ms: 5
# 缓冲区大小,默认 32M
buffer-memory: 33554432
# 压缩,默认 none,可配置值 gzip、snappy、lz4 和 zstd
compression-type: "snappy"
生产者数据可靠
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
幂等性(参数 enable.idempotence 默认为 true)、事务
消费者如何提高吞吐量
增加分区消费,消费者数 = 分区数。同一个消费组下一个分区只能由一个消费者消费
提高每批次拉取的数量,批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压。
重复消费和漏消费
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset(手动提交)过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质(比如MySQL)
https://blog.csdn.net/weixin_43847283/article/details/124530624
https://www.jianshu.com/c/0c9d83802b0c
https://blog.csdn.net/yuanlong122716/article/details/105160545
https://blog.csdn.net/dapeng1995/article/details/81536862

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)