
大数据技术之HBase原理与实战归纳分享-中
上一篇我们了解HBase基础知识,本篇则针对Hbase底层原理深入了解Master和RegionServer的架构,剖析Hbase的读写流程以及非常重要的写缓存刷写和文件合并机制,掌握预定义分区和系统拆分,最后通过封装Java API编程连接类、DDL操作类、DML操作类及其演示的示例代码结果结尾。
底层原理
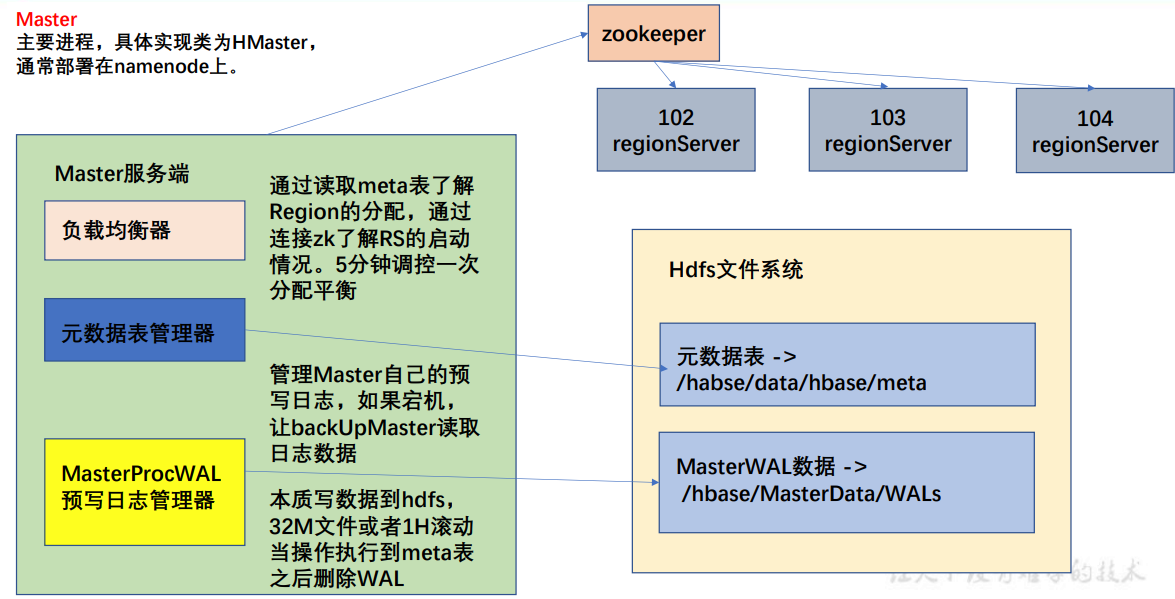
Master架构
- Meta 表格介绍:全称 hbase:meta,只是在 list 命令中被过滤掉了,本质上和 HBase 的其他表格一样,不要去改这个表。
- RowKey:([table],[region start key],[region id]) 即 表名,region 起始位置和 regionID。
- 列:
- 注意:在客户端对元数据进行操作的时候才会连接 master,如果对数据进行读写,直接连接zookeeper 读取目录/hbase/meta-region-server 节点信息,会记录 meta 表格的位置。直接读取即可,不需要访问 master,这样可以减轻 master 的压力,相当于 master 专注 meta 表的写操作,客户端可直接读取 meta 表。
- 在 HBase 的 2.3 版本更新了一种新模式:Master Registry。客户端可以访问 master 来读取meta 表信息。加大了 master 的压力,减轻了 zookeeper 的压力。
- HMaster通常部署在NameNode上,HMaster中主要有负载均衡器,元数据表管理器,预写日志管理器(MasterProcWAL)。
RegionServer架构
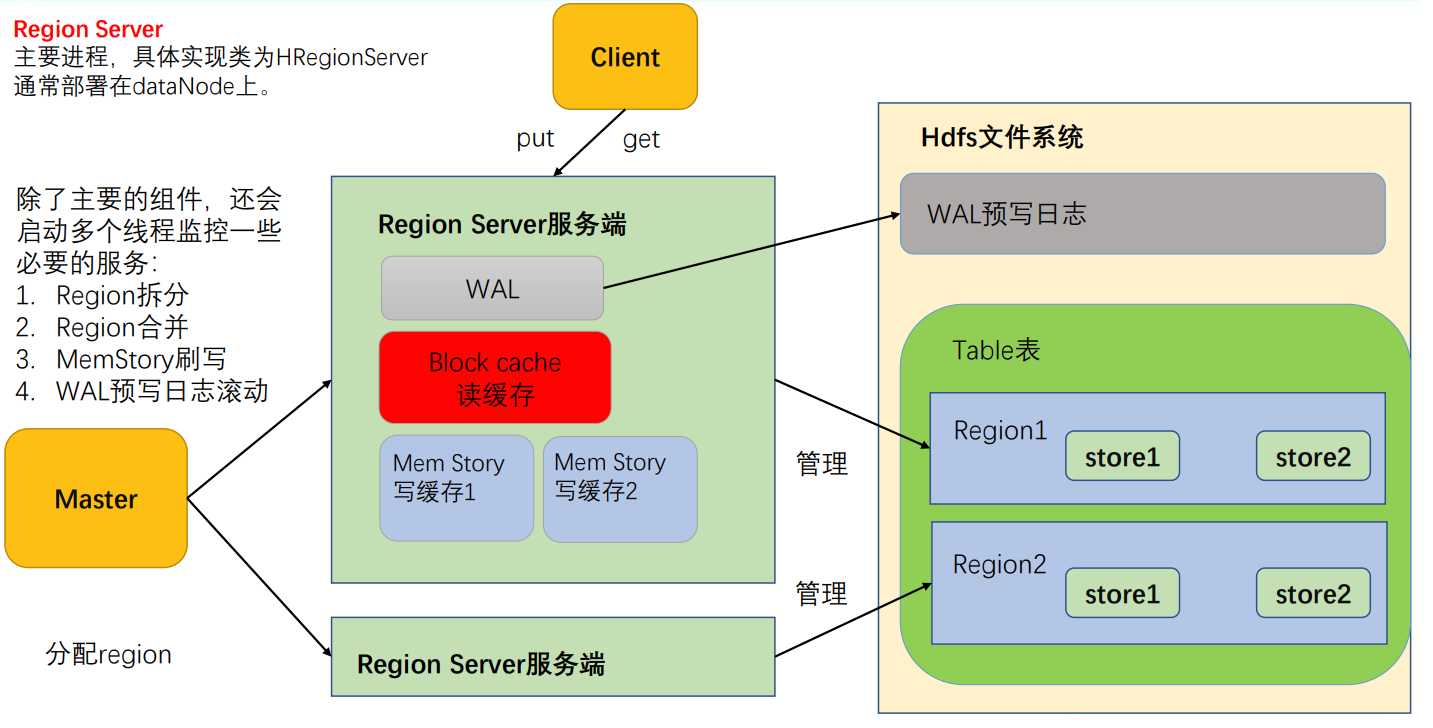
- MemStore:写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile,写入到对应的文件夹 store 中。
- WAL:由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
- BlockCache:读缓存,每次查询出的数据会缓存在 BlockCache 中,方便下次查询。
Region/Store/StoreFile/Hfile之间的关系
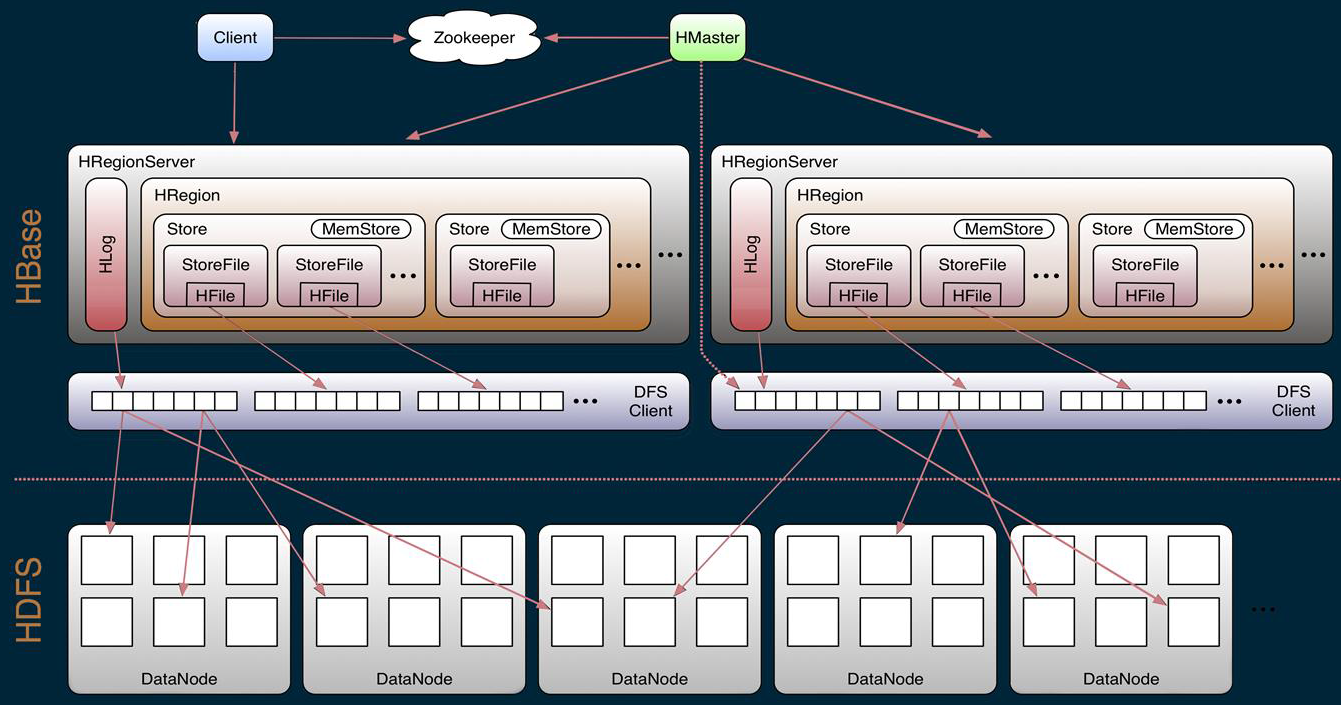
- Region
- table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
- Region按大小分隔,表中每一行只能属于一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
- Store
- 每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store(即有几个ColumnFamily,也就有几个Store)。一个Store由一个memStore和0或多个StoreFile组成。
- HBase以store的大小来判断是否需要切分region。
- MemStore
- memStore 是放在内存里的。保存修改的数据即keyValues。当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,即生成一个快照。目前hbase 会有一个线程来负责memStore的flush操作。
- StoreFile
- memStore内存中的数据写到文件后就是StoreFile(即memstore的每次flush操作都会生成一个新的StoreFile),StoreFile底层是以HFile的格式保存。
- HFile
- HFile是HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。一个StoreFile对应着一个HFile。而HFile是存储在HDFS之上的。HFile文件格式是基于Google Bigtable中的SSTable,如下图所示:
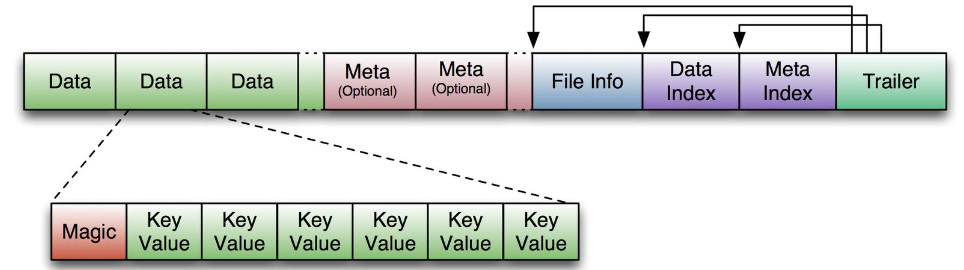
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中又指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。
写流程
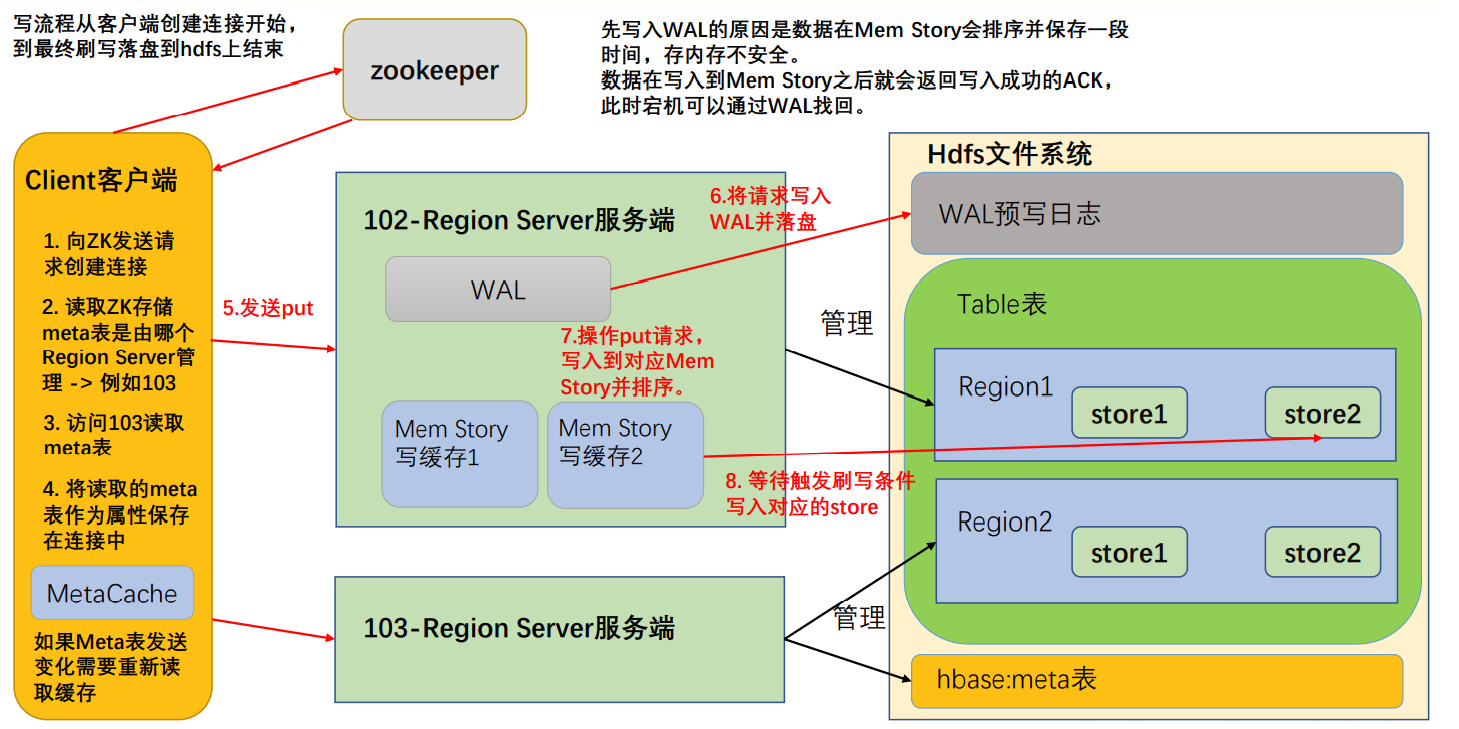
- 首先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server;
- 访问对应的 Region Server,获取 hbase:meta 表,将其缓存到连接中,作为连接属性 MetaCache,由于 Meta 表格具有一定的数据量,导致了创建连接比较慢; 之后使用创建的连接获取 Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问 RegionServer,之后在获取 Table 时不会访问 RegionServer;
- 调用Table的put方法写入数据,此时还需要解析RowKey,对照缓存的MetaCache,查看具体写入的位置有哪个 RegionServer;
- 将数据顺序写入(追加)到 WAL,此处写入是直接落盘的,并设置专门的线程控制 WAL 预写日志的滚动(类似 Flume);
- 根据写入命令的 RowKey 和 ColumnFamily 查看具体写入到哪个 MemStory,并且在 MemStory 中排序;
- 向客户端发送 ack;
- 等达到 MemStore 的刷写时机后,将数据刷写到对应的 story 中。
写缓存刷写
MemStore Flush也即是写缓存刷写,MemStore 刷写由多个线程控制,条件互相独立:主要的刷写规则是控制刷写文件的大小,在每一个刷写线程中都会进行监控
- 当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M),其所在 region 的所有 memstore 都会刷写。当 memstore 的大小达到了hbase.hregion.memstore.flush.size(默认值 128M)* hbase.hregion.memstore.block.multiplier(默认值 4)时,会刷写同时阻止继续往该 memstore 写数据(由于线程监控是周期性的,所有有可能面对数据洪峰,尽管可能性比较小)
- 由 HRegionServer 中的属性 MemStoreFlusher 内部线程 FlushHandler 控制。标准为LOWER_MARK(低水位线)和 HIGH_MARK(高水位线),意义在于避免写缓存使用过多的内存造成 OOM。当 region server 中 memstore 的总大小达到低水位线java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.4) * hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server 中所有 memstore 的总大小减小到上述值以下。当 region server 中 memstore 的总大小达到高水位线java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.4)时,会同时阻止继续往所有的 memstore 写数据。
- 为了避免数据过长时间处于内存之中,到达自动刷写的时间,也会触发 memstore flush。由 HRegionServer 的属性 PeriodicMemStoreFlusher 控制进行,由于重要性比较低,5min才会执行一次。自动刷新的时间间隔由该属性进行配置 hbase.regionserver.optionalcacheflushinterval(默认1 小时)。
- 当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃,现无需手动设置,最大值为 32)。
读流程
在了解读流程之前,需要先知道读取的数据,这就需要了解HFile ;HFile 是存储在 HDFS 上面每一个 store 文件夹下实际存储数据的文件。里面存储多种内容。包括数据本身(keyValue 键值对)、元数据记录、文件信息、数据索引、元数据索引和一个固定长度的尾部信息(记录文件的修改情况)。
键值对按照块大小(默认 64K)保存在文件中,数据索引按照块创建,块越多,索引越大。每一个 HFile 还会维护一个布隆过滤器(就像是一个很大的地图,文件中每有一种 key,就在对应的位置标记,读取时可以大致判断要 get 的 key 是否存在 HFile 中)。KeyValue 内容如下:
- rowlength -----------→ key 的长度
- row -----------------→ key 的值
- columnfamilylength --→ 列族长度
- columnfamily --------→ 列族
- columnqualifier -----→ 列名
- timestamp -----------→ 时间戳(默认系统时间)
- keytype -------------→ Put
由于 HFile 存储经过序列化,所以无法直接查看。可以通过 HBase 提供的命令来查看存储在 HDFS 上面的 HFile 元数据内容。
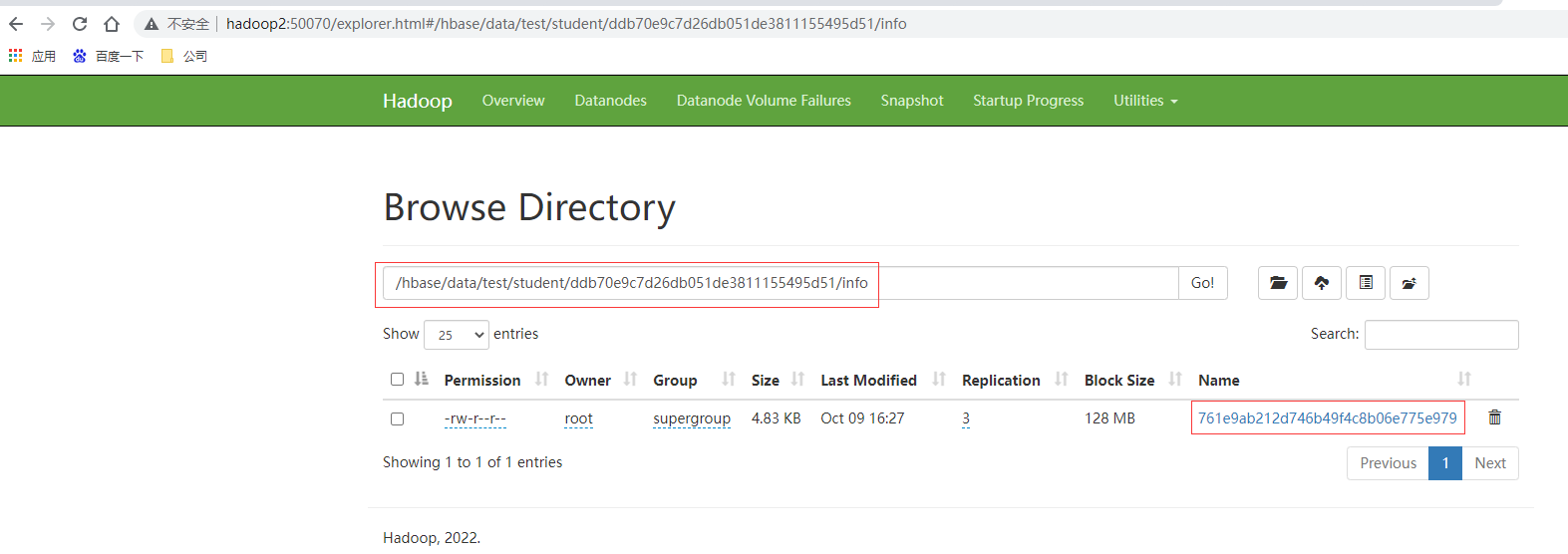
# hbase hfile -m -f /hbase/data/命名空间/表名/regionID/列族/HFile 名
hbase hfile -m -f /hbase/data/test/student/ddb70e9c7d26db051de3811155495d51/info/761e9ab212d746b49f4c8b06e775e979
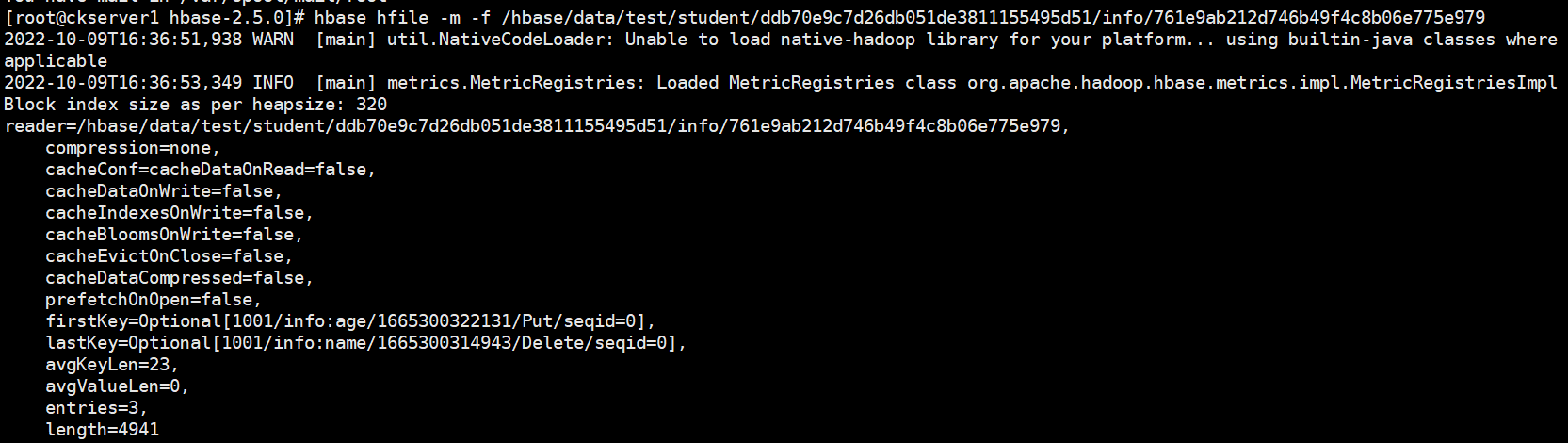
读流程如下
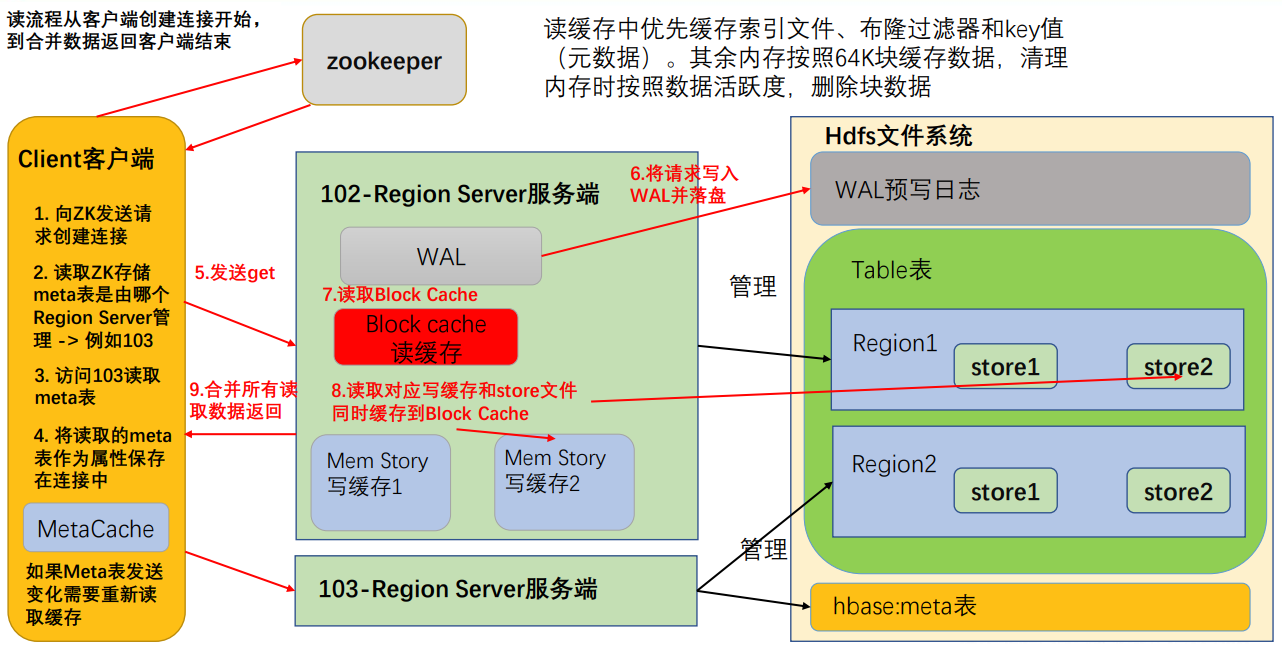
- 首先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server;
- 访问对应的 Region Server,获取 hbase:meta 表,将其缓存到连接中,作为连接属性 MetaCache,由于 Meta 表格具有一定的数据量,导致了创建连接比较慢; 之后使用创建的连接获取 Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问 RegionServer,之后在获取 Table 时不会访问 RegionServer;
- 创建 Table 对象发送 get 请求。
- 优先访问 Block Cache,查找是否之前读取过,并且可以读取 HFile 的索引信息和布隆过滤器。
- 不管读缓存中是否已经有数据了(可能已经过期了),都需要再次读取写缓存和store 中的文件。
- 最终将所有读取到的数据合并版本,按照 get 的要求返回即可。
合并读取数据优化,每次读取数据都需要读取三个位置,最后进行版本的合并。效率会非常低,所有系统需要对此优化。
- HFile 带有索引文件,读取对应 RowKey 数据会比较快。
- Block Cache 会缓存之前读取的内容和元数据信息,如果 HFile 没有发生变化(记录在 HFile 尾信息中),则不需要再次读取。
- 使用布隆过滤器能够快速过滤当前 HFile 不存在需要读取的 RowKey,从而避免读取文件。(布隆过滤器使用 HASH 算法,不是绝对准确的,出错会造成多扫描一个文件,对读取数据结果没有影响)
文件合并
StoreFile Compaction也即是文件合并,由于 memstore 每次刷写都会生成一个新的 HFile,文件过多读取不方便,所以会进行文件的合并,清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。MinorCompaction会将临近的若干个较小的 HFile 合并成一个较大的 HFile,并清理掉部分过期和删除的数据,有系统使用一组参数自动控制,Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉所有过期和删除的数据,由参数 hbase.hregion.majorcompaction控制,默认 7 天。
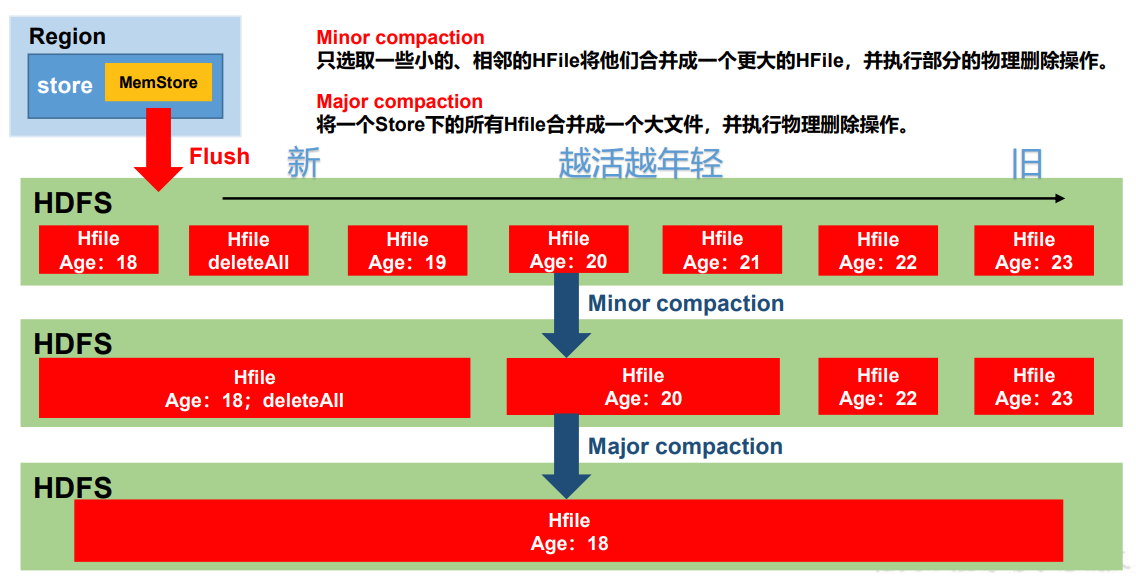
- Minor Compaction 控制机制:参与到小合并的文件需要通过参数计算得到,有效的参数有 5 个
- hbase.hstore.compaction.ratio(默认 1.2F)合并文件选择算法中使用的比率。
- hbase.hstore.compaction.min(默认 3) 为 Minor Compaction 的最少文件个数。
- hbase.hstore.compaction.max(默认 10) 为 Minor Compaction 最大文件个数。
- hbase.hstore.compaction.min.size(默认 128M)为单个 Hfile 文件大小最小值,小于这个数会被合并。
- hbase.hstore.compaction.max.size(默认 Long.MAX_VALUE)为单个 Hfile 文件大小最大值,高于这个数不会被合并。小合并机制为拉取整个 store 中的所有文件,做成一个集合。之后按照从旧到新的顺序遍历。
- 判断条件为:
- 过小合并,过大不合并。
- 文件大小/ hbase.hstore.compaction.ratio < (剩余文件大小和) 则参与压缩。所有把比值设置过大,如 10 会最终合并为 1 个特别大的文件,相反设置为 0.4,会最终产生 4 个 storeFile。不建议修改默认值。
- 满足压缩条件的文件个数达不到个数要求(3 <= count <= 10)则不压缩。
分区
Region Split也即是分区,Region 切分分为两种,创建表格时候的预分区即自定义分区,同时系统默认还会启动一个切分规则,避免单个 Region 中的数据量太大。
- 自定义分区:每一个 region 维护着 startRow 与 endRowKey,如果加入的数据符合某个 region 维护的rowKey 范围,则该数据交给这个 region 维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高 HBase 性能。
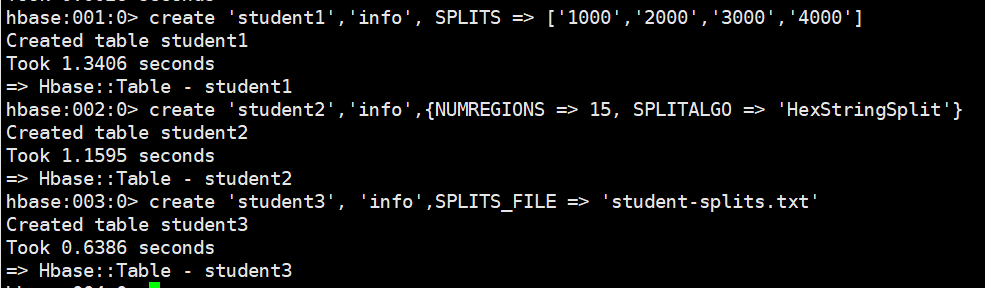
# 手动设定预分区
create 'student1','info', SPLITS => ['1000','2000','3000','4000']
# 生成 16 进制序列预分区
create 'student2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
# 按照文件中设置的规则预分区,创建 student-splits.txt 文件内容如下:
aaaa
bbbb
cccc
dddd
# 然后执行:
create 'student3', 'info',SPLITS_FILE => 'student-splits.txt'
- 系统拆分:Region 的拆分是由 HRegionServer 完成的,在操作之前需要通过 ZK 汇报 master,修改对应的 Meta 表信息添加两列 info:splitA 和 info:splitB 信息。之后需要操作 HDFS 上面对应的文件,按照拆分后的 Region 范围进行标记区分,实际操作为创建文件引用,不会挪动数据。刚完成拆分的时候,两个 Region 都由原先的 RegionServer 管理。之后汇报给 Master,由Master将修改后的信息写入到Meta表中。等待下一次触发负载均衡机制,才会修改Region的管理服务者,而数据要等到下一次压缩时,才会实际进行移动。不管是否使用预分区,系统都会默认启动一套 Region 拆分规则。
- 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过hbase.hregion.max.filesize (10G),该 Region 就会进行拆分。0.94 版本之后,2.0 版本之前 => IncreasingToUpperBoundRegionSplitPolicy
- 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过Min(initialSize*R^3 ,hbase.hregion.max.filesize"),该 Region 就会进行拆分。其中 initialSize 的默认值为 2 * hbase.hregion.memstore.flush.size,R 为当前 Region Server 中属于该 Table 的Region 个数(0.94 版本之后)。
具体的切分策略为:- 第一次 split:1^3 * 256 = 256MB
- 第二次 split:2^3 * 256 = 2048MB
- 第三次 split:3^3 * 256 = 6912MB
- 第四次 split:4^3 * 256 = 16384MB > 10GB,因此取较小的值 10GB
- 后面每次 split 的 size 都是 10GB 了。2.0 版本之后 => SteppingSplitPolicy
- Hbase 2.0 引入了新的 split 策略:如果当前 RegionServer 上该表只有一个 Region,按照 2 * hbase.hregion.memstore.flush.size 分裂,否则按照 hbase.hregion.max.filesize 分裂。
JAVA API编程
准备
新建项目后在 pom.xml 中添加下面依赖,注意:会报错 javax.el 包不存在,是一个测试用的依赖,不影响使用。
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.5.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.1-b12</version>
</dependency>
在 resources 文件夹中创建配置文件 hbase-site.xml,添加以下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
<description>The directory shared by RegionServers.</description>
</property>
</configuration>
示例
根据官方 API 介绍,HBase 的客户端连接由 ConnectionFactory 类来创建,用户使用完成 之后需要手动关闭连接。同时连接是一个重量级的,推荐一个进程使用一个连接,对 HBase 的命令通过连接中的两个属性 Admin 和 Table 来实现。
封装连接类HBaseConnection.java,使用类单例模式,确保使用一个连接,可以同时用于多个线程。
package cn.itxs.hbasedemo;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
public class HBaseConnection {
//声明一个静态属性
public static Connection connection = null;
static{
//1.创建连接配置对象
//Configuration conf = new Configuration();
//2.添加配置参数
//conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");
//因为已经把配置参数写到hbase-site.xml中,所以直接连接
//3.创建连接
//默认使用同步连接
try {
connection = ConnectionFactory.createConnection();
} catch (IOException e) {
System.out.println("连接失败");
e.printStackTrace();
}
}
/**
* 关闭连接方法
* @throws IOException
*/
public static void closeConnection() throws IOException {
if (connection != null){
// 关闭
connection.close();
}
}
public static void main(String[] args) throws IOException {
//可以使用异步连接
//CompletableFuture<AsyncConnection> asyncConnection = ConnectionFactory.createAsyncConnection();
//4.使用连接
System.out.println(connection);
//在main最后关闭连接
HBaseConnection.closeConnection();
}
}
封装DDL操作类HBaseDDL.java
package cn.itxs.hbasedemo;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseDDL {
// 添加静态属性 connection 指向单例连接
public static Connection connection= HBaseConnection.connection;
/**
* 创建命名空间
* @param namespace 命名空间名称
*/
public static void createNamespace(String namespace) throws IOException {
//1.获取admin
//admin 连接是轻量级的,不是线程安全的 不推荐池化,或者缓存这个连接
Admin admin = connection.getAdmin();
//2.调用方法,创建命名空间
/* 代码相对shel1更加底层 所以shel1能够实现的功能代码一定能实现
11所以需要填写完整的命名空间描述*/
//2.1 创建命名空间描述建造者 => 设计师
NamespaceDescriptor.Builder builder = NamespaceDescriptor.create(namespace);
//2.2 给命名空间添加需求
builder.addConfiguration("user","mazankang");
//2.3 使用builder构造出对应的NamespaceDescriptor添加完参数的对象
//完成创建
// 创建命名空间出现的问题 都属于本方法自身的问题 不应该抛出异常
try {
admin.createNamespace(builder.build());
} catch (IOException e) {
System.out.println("命名空间已经存在");
e.printStackTrace();
}
//3 关闭admin
admin.close();
}
/**
*判断表格是否存在
* @param namespace 命名空间名称
* @param tableName 表格名称
* @return true表示存在
*/
public static boolean isTableExists(String namespace,String tableName) throws IOException {
//1.获取admin
Admin admin = connection.getAdmin();
//2.使用对象的方法
boolean b = false;
try {
b = admin.tableExists(TableName.valueOf(namespace, tableName));
} catch (IOException e) {
e.printStackTrace();
}
admin.close();
return b;
}
/**
* 创建表格
* @param namespace 命名空间名称
* @param tableName 表格名称
* @param columnFamilys 列族名称 可以有多个
*/
public static void createTable(String namespace,String tableName,String... columnFamilys) throws IOException {
//判断至少有一个列族
if (columnFamilys.length ==0 ){
System.out.println("创建表格需要至少一个列族");
return;
}
//判断表格是否存在
if (isTableExists(namespace,tableName)){
System.out.println("表格已经存在");
return;
}
//获取admin
Admin admin = connection.getAdmin();
//2.调用方法创建表格
//2.1创建表格描述的建造者
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace, tableName));
//2.2添加参数
for (String columnFamily : columnFamilys) {
//2.3创建列族描述的建造者
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));
//2.4对应当前列族添加版本
//添加版本参数
columnFamilyDescriptorBuilder.setMaxVersions(5);//版本
// ------>>>>>>> 在这里可以加创造表属性所需要的所以方法
//2.5创建添加完参数的列族描述
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptorBuilder.build());
}
//2.6创建对应的表格描述
try {
admin.createTable(tableDescriptorBuilder.build());
} catch (IOException e) {
e.printStackTrace();
}
admin.close();
}
/**
* 修改表格中一个列族的版本
* @param namespace 命名空间名称
* @param tableName 表格名称
* @param columnFamily 列族名称
* @param version 版本号
*/
public static void modifyTable(String namespace,String tableName,String columnFamily,int version) throws IOException {
//判断表格是否存在
if (!isTableExists(namespace,tableName)){
System.out.println("表格不存在");
return;
}
//1.获取admin
Admin admin = connection.getAdmin();
//2.调用方法修改表格
//2.0 获取之前的表格描述
TableDescriptor descriptor = admin.getDescriptor(TableName.valueOf(namespace, tableName));
// 需要填写旧的列族描述
ColumnFamilyDescriptor columnFamily1 = descriptor.getColumnFamily(Bytes.toBytes(columnFamily));
//如果使用填写tableName的方法相当于创建了一个新的表格描述建造者没有之前的信息
//1如果想要修改之前的信息必须调用方法填写一个旧的表格描述
//2.1 创建一个表格描述建造者
//--------------------------
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(descriptor);
//2.2 对应建造者进行表格数据的修改
//创建列族描述建造者
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder =
ColumnFamilyDescriptorBuilder.newBuilder(columnFamily1);
//修改对应的版本
columnFamilyDescriptorBuilder.setMaxVersions(version);
//此处修改的时候 如果是新创建的 别的参数会初始化
tableDescriptorBuilder.modifyColumnFamily(columnFamilyDescriptorBuilder.build());
try {
admin.modifyTable(tableDescriptorBuilder.build());
} catch (IOException e) {
throw new RuntimeException(e);
}
//关闭
admin.close();
}
/**
* 删除表格
* @param namespace 命名空间名称
* @param tableName 表格名称
* @return true 表示删除成功
*/
public static boolean deleteTable(String namespace,String tableName) throws IOException {
//1判断表格是否存在
if (!isTableExists(namespace,tableName)) {
System.out.println("表格不存在");
return false;
}
//2.获取admin
Admin admin = connection.getAdmin();
// 3.调用 相关的方法删除表格
try {
//HBase删除表格之前 一定要标记表格为不可用disable
TableName tableName1 = TableName.valueOf(namespace, tableName);
admin.disableTable(tableName1);
admin.deleteTable(tableName1);
} catch (IOException e) {
throw new RuntimeException(e);
}
//关闭admin
admin.close();
return true;
}
}
封装DML读写数据类HBaseDML.java
package cn.itxs.hbasedemo;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.ColumnValueFilter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseDML {
//添加静态属性connection指向单例属性
public static Connection connection = HBaseConnection.connection;
/**
* 插入数据
* @param namespace 命名空间名称
* @param tableName 表名称
* @param rowKye 主键,
* @param columnFamily 列族
* @param columnName 列名
* @param value 值
*/
public static void putCell(String namespace,String tableName,String rowKye,String columnFamily,String columnName,String value) throws IOException {
//获取table
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
//2,调用相关的方法往里面插入数据
//创建put对象
Put put = new Put(Bytes.toBytes(rowKye));
//3,添加属性
put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName),Bytes.toBytes(value));
//4.添加对象将对象写入相关的方法
try {
table.put(put);
} catch (IOException e) {
throw new RuntimeException(e);
}
table.close();
}
/**
* 读取数据 读取对应的一行中的某一列
* @param namespace 命名空间名称
* @param tableName 表名称
* @param rowKye 主键
* @param columnFamily 列族
* @param columnName 列名
*/
public static void getCells(String namespace,String tableName,String rowKye,String columnFamily,String columnName) throws IOException {
//获取table
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
//2.创建get的对象
Get get = new Get(Bytes.toBytes(rowKye));
//如果现在调用get方法读取数据,此时读一整行数据
get.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName));
//设置读取数据的版本
get.readAllVersions();
//读取数据得到result对象
Result result = null;
try {
result = table.get(get);
} catch (IOException e) {
throw new RuntimeException(e);
}
//处理数据
///1测试方法:直接把读取的数据打印到空制台
//||如果是实际开发需要再额外写方法对应处理数据
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
//ce11存储数据比较底层
String value = new String(CellUtil.cloneValue(cell));
System.out.println(value);
}
//关闭
table.close();
}
/**
* 扫描数据
* @param namespace 命名空间名称
* @param tableName 表格名称
* @param startRow 开始的row
* @param stopRow 结束的Row 左闭右开
*/
public static void scanRows(String namespace,String tableName,String startRow,String stopRow) throws IOException {
//获取table
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
//2.创建scan 对象
Scan scan = new Scan();
//如果此时直接调用,会直接扫描整张表
//添加参数 来控制扫描的数据
scan.withStartRow(Bytes.toBytes(startRow));
scan.withStopRow(Bytes.toBytes(stopRow));
//读取多行数据 获得scanner
ResultScanner scanner = null;
try {
scanner = table.getScanner(scan);
} catch (IOException e) {
throw new RuntimeException(e);
}
//ResultScanner来记录多行 result的数组
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.print(new String(CellUtil.cloneRow(cell))+"---"+
new String(CellUtil.cloneFamily(cell))+"---"+
new String(CellUtil.cloneQualifier(cell))+"---"+
new String(CellUtil.cloneValue(cell))+"\t");
}
System.out.println();
}
table.close();
}
/**
* 带过滤的扫描
* @param namespace 命名空间名称
* @param tableName 表名称
* @param startRow 开始row
* @param stopRow 结束row
* @param columnFamily 列族
* @param columnName 列名
* @param value 值
* @throws IOException 异常
*/
public static void filterScan(String namespace,String tableName,String startRow,String stopRow
,String columnFamily,String columnName,String value) throws IOException {
//获取table
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
//2.创建scan 对象
Scan scan = new Scan();
//如果此时直接调用,会直接扫描整张表
//添加参数 来控制扫描的数据
scan.withStartRow(Bytes.toBytes(startRow));
scan.withStopRow(Bytes.toBytes(stopRow));
//------>>>>>>
//可以添加多个过滤
FilterList filterList = new FilterList();
//创建过滤器
//(1)结果值保留当前列的数据
ColumnValueFilter columnValueFilter = new ColumnValueFilter(
//列族名称
Bytes.toBytes(columnFamily),
//列名
Bytes.toBytes(columnName),
// 比较关系
CompareOperator.EQUAL,
// 值
Bytes.toBytes(value)
);
//(2)结果保留整行数据
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
//列族名称
Bytes.toBytes(columnFamily),
//列名
Bytes.toBytes(columnName),
// 比较关系
CompareOperator.EQUAL,
// 值
Bytes.toBytes(value)
);
//filterList.addFilter(columnValueFilter);
filterList.addFilter(singleColumnValueFilter);
//添加过滤
scan.setFilter(filterList);
//读取多行数据 获得scanner
ResultScanner scanner = null;
try {
scanner = table.getScanner(scan);
} catch (IOException e) {
throw new RuntimeException(e);
}
//ResultScanner来记录多行 result的数组
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.print(new String(CellUtil.cloneRow(cell))+"---"+
new String(CellUtil.cloneFamily(cell))+"---"+
new String(CellUtil.cloneQualifier(cell))+"---"+
new String(CellUtil.cloneValue(cell))+"\t");
}
System.out.println();
}
table.close();
}
/**
* 删除一行中的一列数据
* @param namespace 命名空间名称
* @param tableName 表格名字
* @param rowKey 主键
* @param columnFamily 列族
* @param columnName 列名
*/
public static void deleteColumn(String namespace,String tableName,String rowKey,String columnFamily,String columnName) throws IOException {
//获取table
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
//创建delete对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
//添加列信息
//addColumn删除一个版本的数据
//addColumns删除多个版本的数据
delete.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName));
delete.addColumns(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName));
try {
table.delete(delete);
} catch (IOException e) {
throw new RuntimeException(e);
}
//关闭
table.close();
}
}
创建测试类
package cn.itxs.hbasedemo;
import java.io.IOException;
public class HBaseDemo {
public static void main(String[] args) throws IOException {
// 创建命名空间
HBaseDDL.createNamespace("apitest");
// 判断表是否存在
System.out.println(HBaseDDL.isTableExists("apitest", "student"));
// 创建表
//HBaseDDL.createTable("apitest","student","info","msg");
// 写入数据
HBaseDML.putCell("apitest","student","3001","info","name","hanmeimei");
HBaseDML.getCells("apitest","student","3001","info","name");
HBaseConnection.closeConnection();
}
}
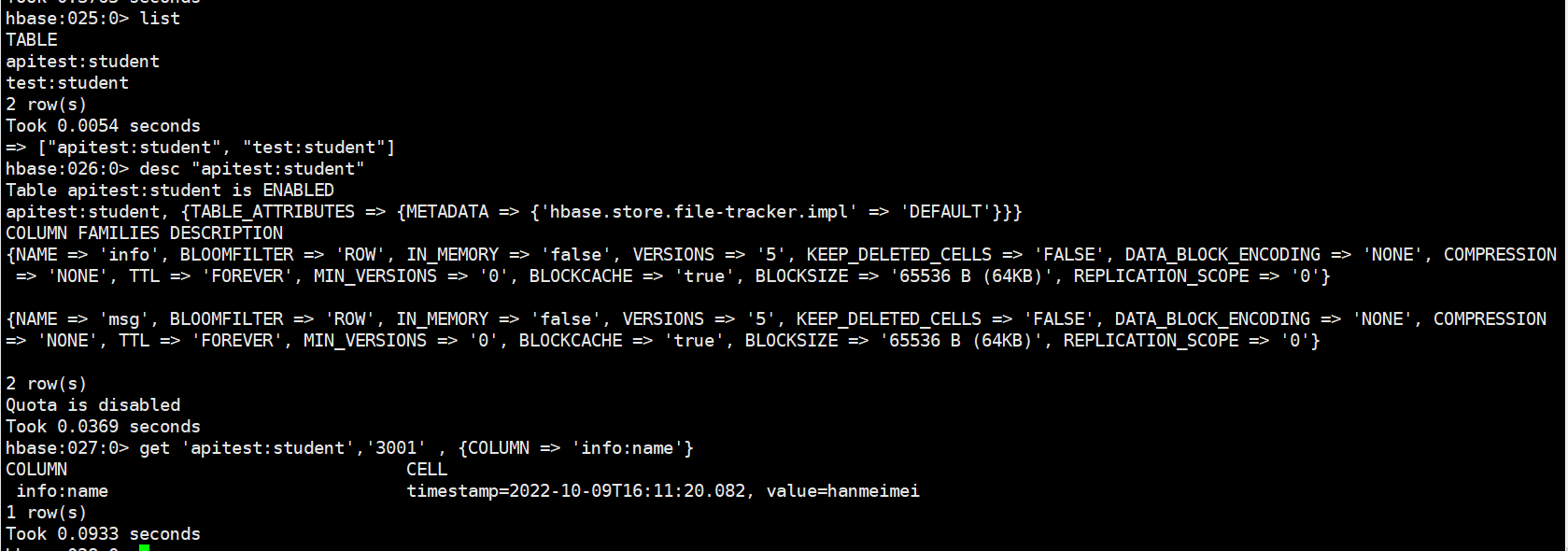
运行测试程序后查看HBase中的数据
**本人博客网站 **IT小神 www.itxiaoshen.com

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)