Elasticsearch7.17 五 :ES读写原理、分片设计和性能优化
单个分片7.0开始,新创建一个索引时,默认只有一个主分片。单个分片,查询算分,聚合不准的问题都可以得以避免单个索引,单个分片时候,集群无法实现水平扩展。即使增加新的节点,无法实现水平扩展两个分片集群增加一个节点后,Elasticsearch 会自动进行分片的移动,也叫 Shard Rebalancing如何设计分片数当分片数>节点数时,一旦集群中有新的数据节点加入,分片就可以自动进行分配,分片在重
ES读写原理、分片设计和性能优化
分片设计和管理
单个分片
7.0开始,新创建一个索引时,默认只有一个主分片。单个分片,查询算分,聚合不准的问题都可以得以避免
单个索引,单个分片时候,集群无法实现水平扩展。即使增加新的节点,无法实现水平扩展
两个分片
集群增加一个节点后,Elasticsearch 会自动进行分片的移动,也叫 Shard Rebalancing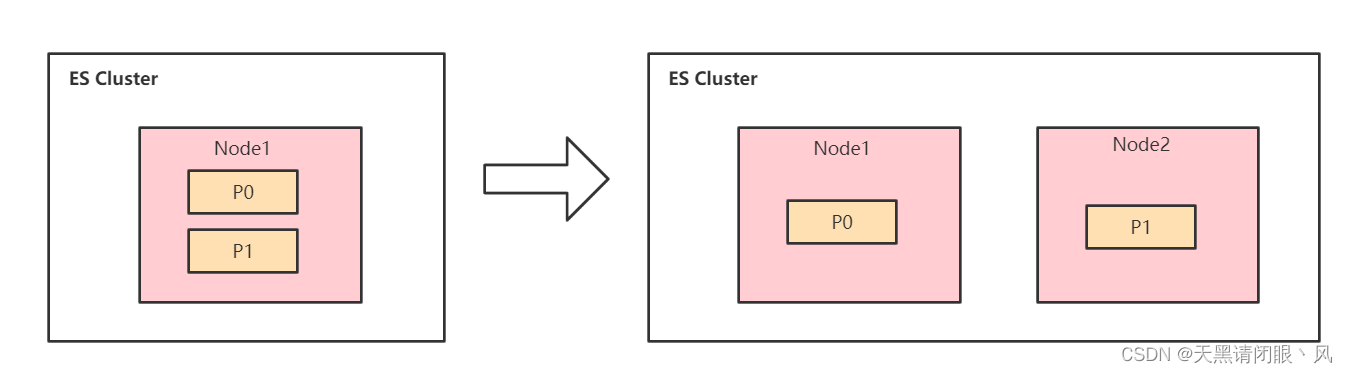
如何设计分片数
当分片数>节点数时,一旦集群中有新的数据节点加入,分片就可以自动进行分配,分片在重新分配时,系统不会有downtime
多分片的好处: 一个索引如果分布在不同的节点,多个节点可以并行执行;查询可以并行执行,数据写入可以分散到多个机器
分片过多所带来的副作用
Shard是Elasticsearch 实现集群水平扩展的最小单位。过多设置分片数会带来一些潜在的问题:
- 每个分片是一个Lucene的索引,会使用机器的资源。过多的分片会导致额外的性能开销。
- 每次搜索的请求,需要从每个分片上获取数据
- 分片的Meta 信息由Master节点维护。过多,会增加管理的负担。经验值,控制分片总数在10W以内
如何确定主分片数
从存储的物理角度看:
搜索类应用,单个分片不要超过20 GB
日志类应用,单个分片不要大于50 GB
为什么要控制分片存储大小:
提高Update 的性能
进行Merge 时,减少所需的资源
丢失节点后,具备更快的恢复速度
便于分片在集群内 Rebalancing
如何确定副本分片数
副本是主分片的拷贝:
- 提高系统可用性︰响应查询请求,防止数据丢失
- 需要占用和主分片一样的资源
对性能的影响:
- 副本会降低数据的索引速度: 有几份副本就会有几倍的CPU资源消耗在索引上
- 会减缓对主分片的查询压力,但是会消耗同样的内存资源。如果机器资源充分,提高副本数,可以提高整体的查询QPS
ES的分片策略会尽量保证节点上的分片数大致相同,但是有些场景下会导致分配不均匀:
- 扩容的新节点没有数据,导致新索引集中在新的节点
- 热点数据过于集中,可能会产生性能问题
可以通过调整分片总数,避免分配不均衡
“index.routing.allocation.total_shards_per_node”,index级别的,表示这个index每个Node总共允许存在多少个shard,默认值是-1表示无穷多个;
“cluster.routing.allocation.total_shards_per_node”,cluster级别,表示集群范围内每个Node允许存在有多少个shard。默认值是-1表示无穷多个。
如果目标Node的Shard数超过了配置的上限,则不允许分配Shard到该Node上。注意:index级别的配置会覆盖cluster级别的配置。
生产环境中要适当调大这个index.routing.allocation.total_shards_per_node,避免有节点下线时,分片无法正常迁移
ES底层读写工作原理
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
ES写入数据的过程
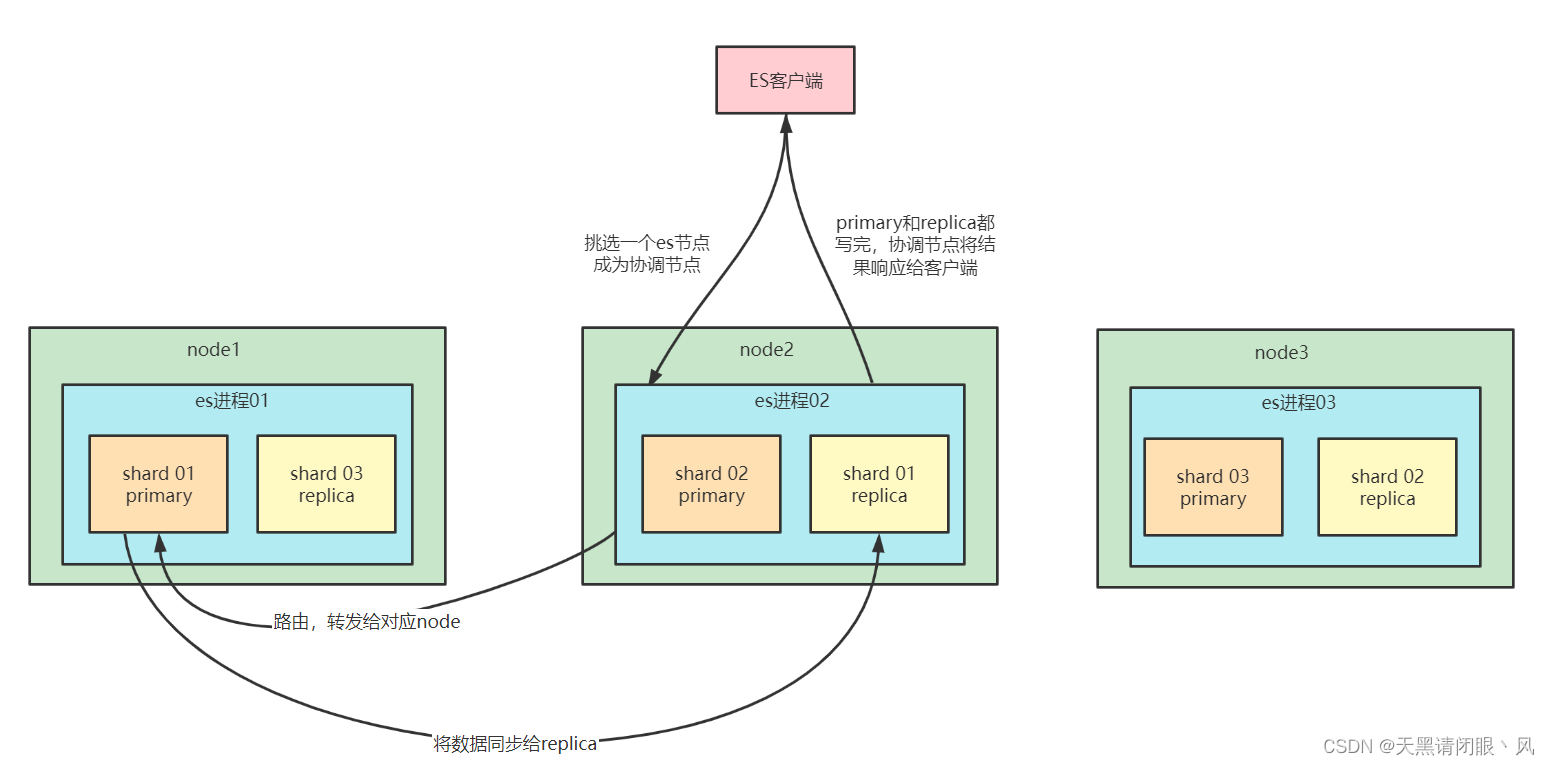
- 客户端选择一个node发送请求过去,这个node就是coordinating node (协调节点)
- coordinating node,对document进行路由,将请求转发给对应的node
- node上的primary shard处理请求,然后将数据同步到replica node
- coordinating node如果发现primary node和所有的replica node都搞定之后,就会返回请求到客户端
ES读取数据的过程
根据id查询数据的过程
根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。 - 客户端发送请求到任意一个 node,成为 coordinate node 。
- coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
- 接收请求的 node 返回 document 给 coordinate node 。
- coordinate node 返回 document 给客户端。
根据关键词查询数据的过程
- 客户端发送请求到一个 coordinate node 。
- 协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard ,都可以。
- query phase:每个 shard 将自己的搜索结果返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
- fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
写数据底层原理
核心概念:segment file: 存储倒排索引的文件,每个segment本质上就是一个倒排索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除。commit point: 记录当前所有可用的segment,每个commit point都会维护一个.del文件,即每个.del文件都有一个commit point文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉translog日志文件: 为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中。os cache:操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去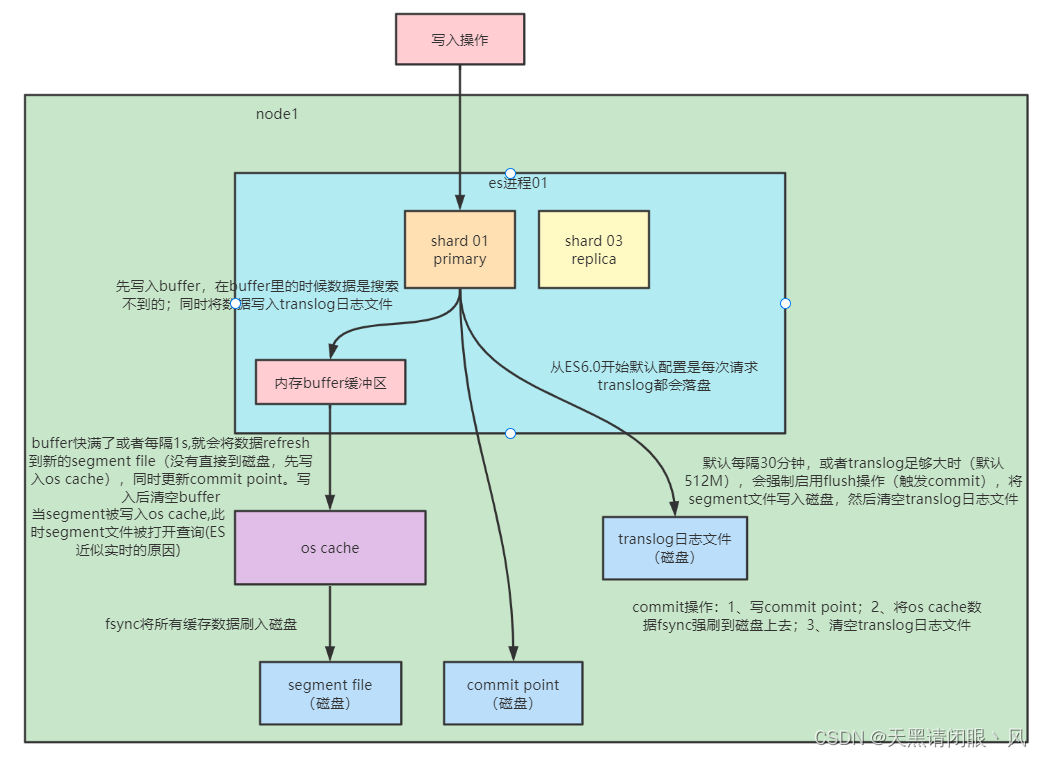
Refresh:将文档先保存在Index buffer中,以refresh_interval为间隔时间,定期清空buffer,生成 segment,借助文件系统缓存的特性,先将segment放在文件系统缓存中,并开放查询,以提升搜索的实时性Translog:Segment没有写入磁盘,即便发生了当机,重启后,数据也能恢复,从ES6.0开始默认配置是每次请求都会落盘Flush删除旧的translog 文件,生成Segment并写入磁盘│更新commit point并写入磁盘。ES自动完成,可优化点不多
性能提升
提升集群的读写性能
提升集群读取性能
- 尽量将数据进行业务处理,然后保存到Elasticsearch 中。尽量避免查询时的 Script计算
- 尽量使用Filter Context,利用缓存机制,减少不必要的算分
- 结合profile,explain API分析慢查询的问题,持续优化数据模型
- 避免使用*开头的通配符查询
优化分片
- 避免分片过多
一个查询需要访问每一个分片,分片过多,会导致不必要的查询开销 - 结合应用场景,控制单个分片的大小
Search: 20GB
Logging: 40GB - 使用基于时间序列的索引,将只读的索引进行force merge,减少segment数量
#手动force merge
POST /my_index/_forcemerge
提升写入性能
写性能优化的目标: 增大写吞吐量,越高越好
- 客户端: 多线程,批量写
可以通过性能测试,确定最佳文档数量
多线程: 需要观察是否有HTTP 429(Too Many Requests)返回,实现 Retry以及线程数量的自动调节 - 服务器端: 单个性能问题,往往是多个因素造成的。需要先分解问题,在单个节点上进行调整并且结合测试,尽可能压榨硬件资源,以达到最高吞吐量
使用更好的硬件。观察CPU / IO Block
线程切换│堆栈状况 - 降低IO操作
使用ES自动生成的文档ld
一些相关的ES 配置,如Refresh Interval - 降低 CPU 和存储开销
减少不必要分词
避免不需要字段
文档的字段尽量保证相同的顺予,可以提高文档的压缩率 - 尽可能做到写入和分片的均衡负载,实现水平扩展
- 调整Bulk 线程池和队列
`注意:ES 的默认设置,已经综合考虑了数据可靠性,搜索的实时性,写入速度,一般不要盲目修改。一切优化,都要基于高质量的数据建模。’
建模时的优化
- 只需要聚合不需要搜索,index设置成false
- 不要对字符串使用默认的dynamic mapping。字段数量过多,会对性能产生比较大的影响
- Index_options控制在创建倒排索引时,哪些内容会被添加到倒排索引中。
如果需要追求极致的写入速度,可以牺牲数据可靠性及搜索实时性以换取性能:
- 牺牲可靠性: 将副本分片设置为0,写入完毕再调整回去
- 牺牲搜索实时性︰增加Refresh Interval的时间
- 牺牲可靠性: 修改Translog的配置
降低 Refresh的频率
增加refresh_interval 的数值。默认为1s ,如果设置成-1,会禁止自动refresh。避免过于频繁的refresh,而生成过多的segment 文件。但是会降低搜索的实时性
PUT /my_index/_settings
{
"index" : {
"refresh_interval" : "10s"
}
}
增大静态配置参数indices.memory.index_buffer_size 默认是10%,会导致自动触发refresh
降低Translog写磁盘的频率,但是会降低容灾能力
- Index.translog.durability: 默认是request,每个请求都落盘。设置成async,异步写入
- lndex.translog.sync_interval:设置为60s,每分钟执行一次
- Index.translog.flush_threshod_size: 默认512 m,可以适当调大。当translog 超过该值,会触发flush
分片设定
- 副本在写入时设为0,完成后再增加
- 合理设置主分片数,确保均匀分配在所有数据节点上
- Index.routing.allocation.total_share_per_node:限定每个索引在每个节点上可分配的主分片
PUT myindex
{
"settings": {
"index": {
"refresh_interval": "30s", #30s一次refresh
"number_of_shards": "2"
},
"routing": {
"allocation": {
"total_shards_per_node": "3" #控制分片,避免数据热点
}
},
"translog": {
"sync_interval": "30s",
"durability": "async" #降低translog落盘频率
},
"number_of_replicas": 0
},
"mappings": {
"dynamic": false, #避免不必要的字段索引,必要时可以通过update by query
索引必要的字段
"properties": {}
}
}
Elasticsearch 聚合性能优化
启用 eager global ordinals 提升高基数聚合性能。适用场景:高基数聚合 。高基数聚合场景中的高基数含义:一个字段包含很大比例的唯一值。
global ordinals 中文翻译成全局序号,是一种数据结构,应用场景如下:
- 基于 keyword,ip 等字段的分桶聚合,包含:terms聚合、composite 聚合 等。
- 基于text 字段的分桶聚合(前提条件是:fielddata 开启)。
- 基于父子文档 Join 类型的 has_child 查询和 父聚合。
global ordinals 使用一个数值代表字段中的字符串值,然后为每一个数值分配一个 bucket(分桶)。global ordinals 的本质是:启用 eager_global_ordinals 时,会在刷新(refresh)分片时 构建全局序号。这将构建全局序号的成本从搜索阶段转移到了数据索引化(写入)阶段。
创建索引的同时开启:eager_global_ordinals
PUT /my‐index
{
"mappings": {
"properties": {
"tags": {
"type": "keyword",
"eager_global_ordinals": true
}
}
}
注意:开启 eager_global_ordinals 会影响写入性能,因为每次刷新时都会创建新的全局序 号。为了最大程度地减少由于频繁刷新建立全局序号而导致的额外开销,请调大刷新间隔refresh_interval。该招数的本质是:以空间换时间。
插入数据时对索引进行预排序
- Index sorting (索引排序)可用于在插入时对索引进行预排序,而不是在查询 时再对索引进行排序,这将提高范围查询(range query)和排序操作的性能。
- 在 Elasticsearch 中创建新索引时,可以配置如何对每个分片内的段进行排序。 这是 Elasticsearch 6.X 之后版本才有的特性。
PUT /my_index
{
"settings": {
"index":{
"sort.field": "create_time",
"sort.order": "desc"
}
},
"mappings": {
"properties": {
"create_time":{
"type": "date"
}
}
}
}
注意:预排序将增加 Elasticsearch 写入的成本。在某些用户特定场景下,开启索引预排序会导致大约 40%-50% 的写性能下降。也就是说,如果用户场景更关注写性能的业务,开启索引预排序不是一个很好的选择。
使用节点查询缓存
节点查询缓存(Node query cache)可用于有效缓存过滤器(filter)操作的结果。如果多次执行同一 filter 操作,这将很有效,但是即便更改过滤器中的某一个值,也将意味着需要计算新的过滤器结果。
例如,由于 “now” 值一直在变化,因此无法缓存在过滤器上下文中使用 “now” 的查询。
那怎么使用缓存呢?通过在 now 字段上应用 datemath 格式将其四舍五入到最接近的分钟/小时等,可以使此类请求更具可缓存性,以便可以对筛选结果进行缓存。
PUT /my_index/_doc/1
{
"create_time":"2022-05-11T16:30:55.328Z"
}
#下面的示例无法使用缓存
GET /my_index/_search
{
"query":{
"constant_score": {
"filter": {
"range": {
"create_time": {
"gte": "now-1h",
"lte": "now"
}
}
}
}
}
}
# 下面的示例就可以使用节点查询缓存。
GET /my_index/_search
{
"query":{
"constant_score": {
"filter": {
"range": {
"create_time": {
"gte": "now-1h/m",
"lte": "now/m"
}
}
}
}
}
}
如果当前时间 now 是:16:31:29,那么range query 将匹配 my_date 介于:15:31:00 和 15:31:59 之间的时间数据。同理,聚合的前半部分 query 中如果有基于时间查询,或者后半部分 aggs 部分中有基于时间聚合的,建议都使用 datemath 方式做缓存处理以优化性能。
使用分片请求缓存
聚合语句中,设置:size:0,就会使用分片请求缓存缓存结果。size = 0 的含义是:只返回聚合结果,不返回查询结果。
GET /es_db/_search
{
"size": 0,
"aggs": {
"remark_agg": {
"terms": {
"field": "remark.keyword"
}
}
}
}
拆分聚合,使聚合并行化
Elasticsearch 查询条件中同时有多个条件聚合,默认情况下聚合不是并行运行的。当为每个聚合提供自己的查询并执行 msearch 时,性能会有显著提升。因此,在 CPU 资源不是瓶颈的前提下,如果想缩短响应时间,可以将多个聚合拆分为多个查询,借助:msearch 实现并行聚合。
#常规的多条件聚合实现
GET /employees/_search
{
"size": 0,
"aggs": {
"job_agg": {
"terms": {
"field": "job.keyword"
}
},
"max_salary":{
"max": {
"field": "salary"
}
}
}
}
# msearch 拆分多个语句的聚合实现
GET _msearch
{"index":"employees"}
{"size":0,"aggs":{"job_agg":{"terms":{"field": "job.keyword"}}}}
{"index":"employees"}
{"size":0,"aggs":{"max_salary":{"max":{"field": "salary"}}}}

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)