ES集群启动流程
本文主要记录了ES 集群启动过程及简单原理,理解它有助于解决或避免集群维护过程中可能遇到的脑裂、无主、恢复慢、丢数据等问题。
本文主要记录了ES 集群启动过程及简单原理,理解它有助于解决或避免集群维护过程中可能遇到的脑裂、无主、恢复慢、丢数据等问题
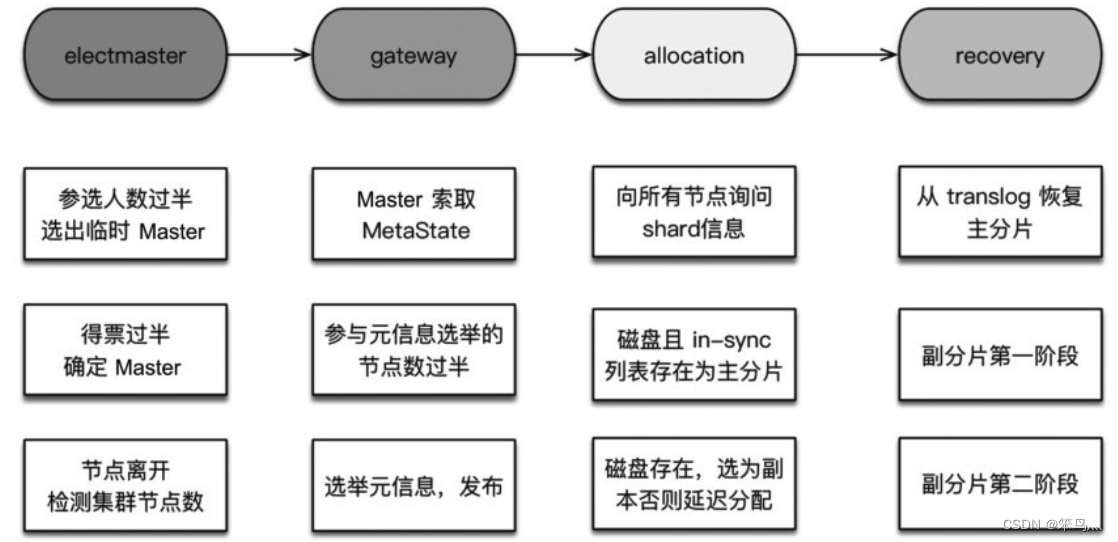
ES 集群启动主要分为以下步骤:
- 选举主节点
- 选举集群元信息
- allocation 过程(分片)
- index recovery(数据恢复)
一、选举主节点
集群启动的第一件事就是选举主节点,因为选举后后续的流程需要由主节点触发。
ES 的选主算法是基于Bully 算法的改进,主要思路是对节点ID 排序,取ID 最大的节点作为Master,每个节点都运行这个流程。
除此之外选举Master 还遵循以下三点:
- 参选人数需要过半,到达多数(quorum)后选出临时的主
- 得票数需要过半
- 当探测到节点离开事件时,必须判断当前节点是否过半。如果达不到quorum,则放弃Master 身份,重新加入集群
为什么需要参选人数过半且得票数过半?
:因为每个节点运行Bully 算法,结果不一定相同。eg.集群有5 台机器,节点ID 分别是1、2、3、4、5。当产生网略分区或者节点启动速度有差异,节点1 看到的节点有1、2、3、4,选出4;节点2 看到的节点有1,2,3,4,5,选出5。
为什么节点离开时,需要重新判断?
:防止出现脑裂。eg. 集群5 个节点出现网络分区,2 台一组,3 台一组,产生分区前,Master 位于2 台中的一个,此时3 台一组的节点会重新选举Master。
二、选举集群元信息
介绍Master 选举算法,可以发现被选出的Master 和集群的元信息新旧程度毫不相关。
因此Master 的第一个任务就是选举元信息:
收集获取最新元信息。Master 会让各个节点把各自存储的元信息发过来,根据版本号获取最新的元信息,然后广播元信息,这样集群的所有节点都有了最新的元信息
选举元信息期间不允许新节点加入
三、allocation 过程
在初始阶段,所有的分片(shard)都处于未分配状态。ES 通过分配过程(allocation)决定那个分片位于那个主节点,重构路由表。
1. 选主分片
在分配之前,Master 并不知道主分片在哪,所以需要先收集节点分片信息。这个询问量 = 分片数 * 节点数,效率略低,所以我们最好控制一下总分片的数量。
选举算法:
- 5.x 以下的版本:通过对比节点分片元信息的版本号。但这种方式不一定能选到最新的数据,比如高版本的接点还未启动的时候
- 5.x 及以上的版本:给每个分片都设置一个UUID,在集群元信息里面标识那个是最新的
2. 选副分片
主分片选举完成后,从收集分片信息中选择一个副本作为副分片。
四、index recovery
分片分配成功后就进入数据恢复阶段。为什么需要recovery?
- 对于主分片来说,可能一些数据没来得及刷盘
- 对于副分片来说,除了没来及刷盘,也可能是写了主分片,还没来得及写副分片
1. 主分片recovery
由于每次写操作都会记录事务(translog),事务日志中记录了那种操作,以及相关的数据。因此将最后一次提交之后的translog 中进行重放,建立Lucene 索引,如此完成主分片的recovery。
2. 副分片recovery
副分片的恢复需要与主分片一致,同时,恢复期间允许新的索引操作。在6.x 版中分为两个阶段:
- 阶段一:在主分片所在节点,获取translog 保留锁(保留translog 不受刷盘清空影响)。然后调用Lucene 接口把shard做成快照进行复制。在阶段二之前,副分片就可以正常处理写请求了
- 阶段二:重放新数据。对trannslog 做快照,这个快照包含从阶段一开始到阶段二快照期间对新增索引
分片完整性保障
如何做到副分片数据不丢?第二阶段的translog 快照包括第一阶段所有的新增操作。如歌第一阶段发生lucene commit(将文件系统写入缓存的数据刷盘,并清空translog)。
- 2.0之前:阻止刷新操作,让tangslog 都保留下来。这种做法会使 tangslog 过大
- 2.0 开始:引入translog.view 概念,创建view 可以后续的所有操作
- 6.x 开始:引入TranslogDeletionPolicy,它将translog 进行快照来保持translog 不被清理
数据一致性保障
通过写版本号来过滤到过期的操作

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)