谷粒学院学习总结
谷粒学院项目总结
目录
项目模块说明
| Service_edu | 后台管理模块/8001 |
|---|---|
| Service_cms | 首页数据Banner显示模块/8004 |
| Service_msm | 阿里云短信服务模块/8005 |
| Service_oss | 阿里云图片云存储服务模块/8002 |
| Service_vod | 阿里云视频点播服务/8003 |
| Service_ucenter | 登录和注册模块(8160端口 => 不能改) |
| Service_order | 微信支付模块/8007 |
| Service_statistics | 统计分析模块/8008 |
| canal-client | 数据同步模块/8009 |
| Api_gateway | 网关模块/8010 |
| Service-acl | 权限管理模块/8011 |
| Guli_parent | 后端代码(前后台) |
|---|---|
| Guli_vue | 后台前端代码 |
| Guli_ftont | 前台前端代码 |
项目功能点
一、后台管理系统功能
1、登录注册功能
- 整合SpringSecurity框架
2、权限管理功能
- 菜单管理:CRUD
- 角色管理:CRUD、批量删除、为角色分配菜单
- 用户管理:CRUD、为用户分配角色
- 表和表的关系:使用五张表【用户表、角色表、菜单表、用户角色中间表、角色菜单中间表】
3、讲师管理模块
- 多条件分页查询(将条件值封装进对象,将对象传递到接口中)
- 讲师列表的CRUD
- 讲师头像上传(阿里云OSS)
4、课程分类模块
-
添加课程分类(读取Excel里的课程数据,添加到数据库中,通过EasyExcel)
-
课程分类列表(使用树形结构显示课程分类列表)
5、课程管理模块
-
课程列表功能(查询所有课程并分页显示)
-
多条件分页查询(将条件值封装进对象,将对象传递到接口中)
-
课程列表的CRUD
-
添加课程(课程发布的流程:填写课程基本信息、添加课程大纲(章节和小节)、课程信息确认、最终发布)
-
添加小节时,可以上传课程视频(阿里云视频点播功能)
-
课程如何判断是否已经发布?
通过给数据库设置字段status来判断他现在的状态(前端返回的课程 id 来修改课程的 status 并在前端显示)
- 课程添加过程中,中途把课程停止添加,重新去添加新的课程,如何找到之前没有发布完成的课程,继续发布呢?
到课程列表中选择未发布的课程状态,来查询,里面会有编辑看课程信息,然后去继续编辑发布完成
6、统计分析模块
生成统计数据(选择指定日期生成当天的数据)
统计数据的图标显示(Echart)
整合定时任务
7、Canal数据同步
Canal是阿里巴巴旗下的一款开源项目,纯java开发,支持MySql数据库
使用MySql的binlog写入功能以及Canal实现数据同步
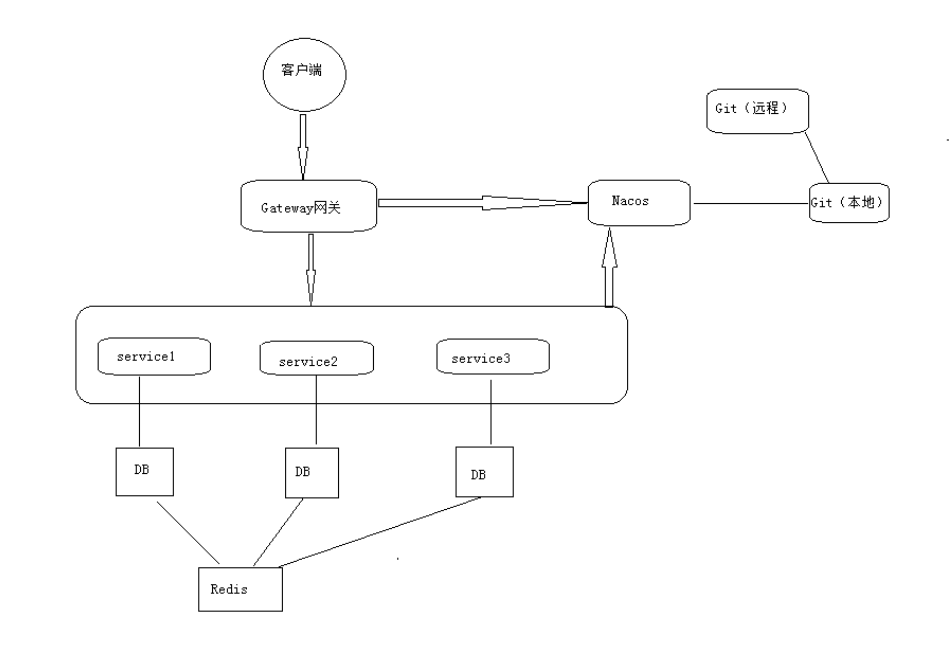
8、GateWay网关
前期使用Nginx作为网关,后期使用GateWay作为网关(需要在Nacos注册中心进行注册)

网关图解
9、首页Banner模块(待做)
添加和删除
10、订单管理模块(待做)
订单表的CRUD
二、前台系统功能
1、首页数据显示
显示首页Banner功能(放入Redis进行缓存)
显示热门课程(放入Redis进行缓存)
显示名师(放入Redis进行缓存)
2、注册功能
获取手机验证码(阿里云云市场)
3、登录注册功能
3.1、普通登录
- 你项目使用的是SSO(单点登录)实现登录的吗?是怎么实现的?
我使用的是token的方式,用户登录成功后,根据相关的信息生成token,然后返回给cookie,他每次访问的时候都会从请求头中获取token的值,并解析获取用信息,判断是否已经登录

单点登录三种方式介绍
-
你使用什么方式生成Token的?
使用Jwt生成token字符串
-
Jwt有几部分组成,分别为什么?
三部分组成,分别为:
jwt头:JWT头部分是一个描述JWT元数据的JSON对象
有效载荷(用户信息):是JWT的主体内容部分,也是一个JSON对象,包含需要传递的数据。 JWT指定七个默认字段供选择
签名哈希(防伪标志):是对上面两部分数据签名,通过指定的算法生成哈希,以确保数据不会被篡改。
-
你登录功能的实现流程是什么(重要)?
1、前端调用登录的接口,后端将用户信息封装成登录对象,登录成功会返回一个token字符串;
2、前端获取后把token字符串放到cookie中;
3、前端创建请求拦截器进行判断,如果cookie里包含token字符串,把token放到header中;
4、前端再次调用接口获取用户信息(由于请求拦截器的存在,会将token放在请求中返回给后端),
后端从header中取到token的值并查询用户信息返回给前端,然后前端在页面中进行显示

登录逻辑
3.2、微信扫码登录
-
OAuth2是什么?
只是一种解决方法,按照一种规则,但是具体是什么规则,没有规定。他是一种方案,但不是一种协议
主要解决两个问题:
1、开放系统间授权
2、分布式访问问题
-
你是如何获取扫码人微信信息的?
扫码后,微信会返回两个值code和state;
拿着这个code去请求微信的固定地址,获得两个值access_token访问凭证和openid(每个微信的唯一表示);
然后拿着这两个再去请求微信的一个固定地址获取到扫码人的信息
3.3、用户注册
-
用户注册的详细流程?
前端填写信息后这些信息会发送到后端(验证码会存在Redis中);
后端接收前端的请求参数并将数据封装成对象(用户昵称、手机号、密码、验证码),并进行参数校验(手机号、密码、验证码);
校验成功后将用户信息加入数据库,前端根据返回的状态码判断是否注册成功,若成功则跳转到登录页面;
4、名师列表功能
- 名师列表分页显示
5、名师详情功能
- 点击某个讲师后显示讲师详情(讲师信息和主讲课程)
6、课程列表功能
-
点击首页课程后显示对应的八条课程(条件查询带分页)
-
具体细节:
前端封装查询对象VO(或修改查询对象VO),后端根据查询对象VO拼接查询条件,查询后返回分页数据,前端进行显示
-
点击一级分类,显示对应的二级分类,查询数据(二级联动效果)
7、课程详情功能
- 课程信息显示(包含基本信息、讲师信息、分类信息、大纲信息 => 自定义sql查询)
8、课程详细视频在线播放功能
-
点击具体某个小节后可在线播放
-
具体细节:
后端创建接口获取视频播放凭证;
前端进行页面跳转并进行播放。
9、课程评论功能
-
可对课程进行相应的评论
-
具体细节:
前端封装评论对象VO,后端接收查询对象VO;
后端创建分页查询课程评论的接口以及添加评论的接口;
前端调用接口获取数据并在页面进行显示
10、课程支付功能
一、后端的四个接口:
- 生成课程订单
- 根据订单id查询订单信息
- 生成微信支付二维码
- 查询订单支付状态
二、支付流程:
- 课程详情页点击立即购买 => 获取订单号 => 跳转订单显示页面

获取订单号并跳转详情页
- 订单详情页显示支付详情 => 点击去支付跳转到支付页面
javascript
toPay(){
this.$router.push({path:'/pay/'+this.orderNo})
}-
支付详情页面(页面渲染完成后每三秒去调用一次查询订单状态的方法 => 支付成功跳转到课程详情页面)
后端接口
java
@ApiOperation(value = "根据订单号查询订单支付状态") @GetMapping("/queryPayStatus/{orderNo}") public ResultVo queryPayStatus(@PathVariable String orderNo){ Map<String,String> map = tPayLogService.queryPayStatus(orderNo); if (map==null){ return ResultVo.error().message("支付出错了"); } //如果返回的map不为空,通过map获取订单的状态 if (map.get("trade_state").equals("SUCCESS")){ //支付成功 => 添加记录到支付表里,并更新订单表的状态 tPayLogService.updateOrderStatus(map); return ResultVo.ok().message("支付成功"); } return ResultVo.ok().message("支付中").code(25000); }前端创建响应拦截器(根据响应码进行页面跳转)
javascript
// http response 拦截器 service.interceptors.response.use( response => { //debugger if (response.data.code == 28004) { console.log("response.data.resultCode是28004") // 返回 错误代码-1 清除ticket信息并跳转到登录页面 //debugger window.location.href="/login" return }else{ if (response.data.code !== 20000) { //25000:订单支付中,不做任何提示 if(response.data.code != 25000) { Message({ message: response.data.message || 'error', type: 'error', duration: 5 * 1000 }) } } else { return response; } } }, error => { //返回接口返回的错误信息 return Promise.reject(error.response) });前端页面代码
javascript
<template>
<div class="cart py-container">
<!--主内容-->
<div class="checkout py-container pay">
<div class="checkout-tit">
<h4 class="fl tit-txt">
<span class="success-icon"></span
><span class="success-info"
>订单提交成功,请您及时付款!订单 号:{{
payObj.out_trade_no
}}</span
>
</h4>
<span class="fr"
><em class="sui-lead">应付金额:</em
><em class="orange money">¥{{ payObj.total_fee }}</em></span
>
<div class="clearfix"></div>
</div>
<div class="checkout-steps">
<div class="fl weixin">微信支付</div>
<div class="fl sao">
<p class="red">请使用微信扫一扫。</p>
<div class="fl code">
<!-- <img id="qrious" src="~/assets/img/erweima.png" alt=""> -->
<!-- <qriously value="weixin://wxpay/bizpayurl?pr=R7tnDpZ":size="338"/> -->
<!--code_url为二维码地址,这里需要通过一个vue的组件【qriously】显示-->
<!--执行npm install vue-qriously下载组件-->
<qriously :value="payObj.code_url" :size="338" />
<div class="saosao">
<p>请使用微信扫一扫</p>
<p>扫描二维码支付</p>
</div>
</div>
</div>
<div class="clearfix"></div>
<!-- <p><a href="pay.html" target="_blank">> 其他支付方式</a></p> -->
</div>
</div>
</div>
</template>
<script>
import orderApi from "@/api/order";
export default {
data() {
return {
orderNo: "",
payObj: {},
timer1: "",
};
},
created() {
this.orderNo = this.$route.params.orderNo;
//生成二维码
this.createQRcode();
},
methods: {
//生成二维码
createQRcode() {
orderApi.createWxQRcode(this.orderNo).then((resp) => {
this.payObj = resp.data.data;
});
},
//根据订单号,查询支付的状态
queryPayStatus(out_trade_no) {
orderApi.getPayStatus(out_trade_no).then((resp) => {
if (resp.data.success) {
//如果支付成功,清除定时器
clearInterval(this.timer1);
//提示
this.$message({
type: "success",
message: "支付成功!",
});
//跳转到课程详细页面观看视频
this.$router.push({ path: "/course/" + this.payObj.course_id });
}
});
},
},
//每个三秒去调用一次查询订单状态的方法
//在页面渲染之后调用
mounted() {
this.timer1 = setInterval(() => {
this.queryPayStatus(this.payObj.out_trade_no);
}, 3000);
},
};
</script>
三、你的微信支付功能的流程你说说?
-
如果课程是收费课程,点击立即购买,生成课程订单;
-
点击订单页面中的去支付,生成微信支付二维码;
-
使用微信区扫秒二维码实现支付;
-
支付之后,每个3秒查询支付状态(是否支付成功),如果没有支付成功就等待;
-
如果支付成功之后,修改订单状态,向支付表中添加记录
项目技术点
一、前后端分离开发
-
项目开发模式为前后端分离开发
-
后端写接口,前端调后端接口得到数据并显示
二、项目使用【前端】技术
1、vue
基本语法
- 指令:
v-bind 简写:v-modelv-forv-ifv-html
- 生命周期:
created(),页面渲染之前mounted(),页面渲染之后
-
绑定事件:
-v-on简写@ -
ES6规范,通过babel转成ES5,框架自带
2、Element-UI
Vue.js的后台组件库,方便程序员进行页面快速布局和构建
3、Nodejs
- Js运行环境,不需要浏览器直接运行代码,模拟服务器效果(
java需要jdk=>javascript需要Node.js)
4、NPM
- 包管理工具,类似Maven,管理前端
js依赖
-
npm命令
npm init初始化npm install依赖名
5、Babel
- 转码器,ES6转换ES5代码(编写Es6代码 => 转化Es5代码后运行)
- Es6代码浏览器兼容性很差
6、前端模块化
- 通过一个页面或js去调用另外一个页面的js文件的方法
- ES6语法不能在
node.js中直接使用,需要通过babel编译成ES5再执行
7、后台系统用vue-admin-templete
- 基于vue、Element-ui
8、前台系统用Nuxt
- 基于vue、3000端口
- 服务器渲染技术
9、Echarts
- 图表工具(百度捐给Aprch)
10、Webpaack
- webpack是一个前端资源加载/打包工具。根据模块的依赖关系进行静态分析,然后将这些模块按照指定的规则生成对应的静态资源
三、项目使用【后端】技术【1】
1、微服务架构
- 将项目拆分为独立的模块,每个模块都有其端口号,模块与模块之间没有关系,是通过远程调用实现
2、SpringBoot
- SpringBoot是什么东西?
SpringBoot本质就是spring,只是快速构建Spring工程的脚手架
细节:
-
启动类包扫描机制
从外往里扫,也可以设置扫描机制,通过
@ComponentScan(包路径) -
配置类
SpringBoot配置文件类型
.properties
.yml
- 配置文件加载机制
先bootstrap
再properties或yaml
再对应的环境如:dev、test、prod
3、SpringCloud
一、SpringCloud简介
Spring Cloud是一系列框架的集合。它利用Spring Boot的开发便利性简化了分布式系统基础设施的开 发,如服务发现、服务注册、配置中心、消息总线、负载均衡、 熔断器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring并没有重复制造轮子,它只是将目前各家公司开发的比较 成熟、经得起实际考验的服务框架组合起来,通过SpringBoot风格进行再封装屏蔽掉了复杂的配置和实 现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包
二、Spring Cloud和Spring Boot是什么关系
Spring Boot 是 Spring 的一套快速配置脚手架,可以基于Spring Boot 快速开发单个微服务,Spring Cloud是一个基于Spring Boot实现的开发工具;Spring Boot专注于快速、方便集成的单个微服务个 体,Spring Cloud关注全局的服务治理框架; Spring Boot使用了默认大于配置的理念,很多集成方案已 经帮你选择好了,能不配置就不配置,Spring Cloud很大的一部分是基于Spring Boot来实现,必须基 于Spring Boot开发。可以单独使用Spring Boot开发项目,但是Spring Cloud离不开 Spring Boot。
三、Spring Cloud相关基础服务组件
基础服务组件
-
服务发现——Netflix Eureka (Nacos)
-
服务调用——Netflix Feign
-
熔断器——Netflix Hystrix
-
服务网关——Spring Cloud GateWay
-
分布式配置——Spring Cloud Config (Nacos)
-
消息总线 —— Spring Cloud Bus (Nacos)
-
负载均衡 ——Ribbon
项目中,使用阿里巴巴Nacos,代替springcloud一些组件
-
Nacos
注册中心
配置中心
-
Feign
服务调用,一个微服务调用另外一个微服务,实现远程调用
-
Hystrix
熔断器
-
Gateway网关,之前是zuul / Nginx
三、SpringCloud版本

springcloud版本号
4、MyBatisPlus
- MyBatisPlus就是对MyBatis的增强,本身并没改变
- 自动填充
- 乐观锁
- 逻辑删除
- 性能分析
- 代码生成器
5、EasyExcel
- 阿里巴巴提供操作Excel工具,效率高,代码简洁
6、Swagger
前后端分离开发交互文档
- 给一些比较难以理解的属性或者接口上增加注释信息
- 接口文档实时更新
- 可以在线测试
项目正式发布的时候需要关闭Swagger
三、项目使用【后端】技术【2】
1、SpringSecurity
1.1、框架介绍
Spring 是一个非常流行和成功的 Java 应用开发框架。Spring Security 基于 Spring 框架,提供了一套Web 应用安全性的完整解决方案。
一般来说,Web 应用的安全性包括用户认证(Authentication)和用户授权(Authorization)两个部分。
(1)用户认证指的是:验证某个用户是否为系统中的合法主体,也就是说用户能否访问该系统。用户认证一般要求用户提供用户名和密码。系统通过校验用户名和密码来完成认证过程。说人话就是登录认证
(2)用户授权指的是验证某个用户是否有权限执行某个操作。在一个系统中,不同用户所具有的权限是不同的。比如对一个文件来说,有的用户只能进行读取,而有的用户可以进行修改。一般来说,系统会为不同的用户分配不同的角色,而每个角色则对应一系列的权限。判断是普通用户还是管理员基于功能访问权限
Spring Security其实就是用filter,多请求的路径进行过滤。
(1)如果是基于Session,那么Spring-security会对cookie里的sessionid进行解析,找到服务器存储的sesion信息,然后判断当前用户是否符合请求的要求。
(2)如果是token,则是解析出token,然后将当前请求加入到Spring-security管理的权限信息中去
1.2、认证与授权实现思路
如果系统的模块众多,每个模块都需要就行授权与认证,所以我们选择基于token的形式进行授权与认证,用户根据用户名密码认证成功,然后获取当前用户角色的一系列权限值,并以用户名为key,权限列表为value的形式存入redis缓存中,根据用户名相关信息生成token返回,浏览器将token记录到cookie中,每次调用api接口都默认将token携带到header请求头中,Spring-security解析header头获取token信息,解析token获取当前用户名,根据用户名就可以从redis中获取权限列表,这样Spring-security就能够判断当前请求是否有权限访问
1.3、认证与授权流程
-
用户名密码认证成功,获取用户的权限值;并以用户名为Key,权限列表为Value的形式存储在Redis缓存中
-
根据用户名相关信息返回token,浏览器将token记录到cookie中,没请求都会在请求头中携带token
-
请求中,Spring-security会解析请求头中的token,并获取用户名;
-
根据用户名为key,去redis中获取value值权限列表
-
根据权限列表来判断用户是否有权限访问
-
图解

SpringSecurity授权过程

SpringSecurity代码执行过程
2、Redis
-
首页数据通过Redis做缓存
-
注册(通过手机号)过程中将后端生成的验证码存储在redis中(设置5分钟过期)
-
Redis数据类型:
- Set
- List
- Hash
- String
- zset
-
Redis做缓存,什么样的数据适合使用Redis做缓存?
经常访问,但不经常修改的数据;如主页
3、Nginx
- 方向代理服务器
- 请求转发、负载均衡、动静分离
4、OAuth2+JWT
-
针对特定问题的解决方案
-
Jwt制定一种规则生成字符串,包括:三部分
- JWT头
- 有效载荷(用户信息)
- 防伪标志
5、HttpClient
-
模拟浏览器,不借助浏览器发送请求响应的工具
-
项目中应用场景:微信登录获取扫描人信息,微信支付查询支付状态
6、Cookie
-
特点:
- 客户端技术,存储在浏览器、客户端中
- 每次发送请求,都会带着cookie
- cookie有默认有效时长,默认关闭浏览器就不存在了,也可以设置时长,会话级别
7、Cannal
-
Canal是阿里巴巴旗下的一款开源项目,纯java开发,支持MySql数据库
-
使用MySql的binlog写入功能以及Canal实现数据同步
8、Git
- 代码提交到远程的Git仓库中
- 进行项目的版本控制
9、Docker
- 容器化技术
- 项目中使用的Mysql数据库和Redis均为容器构建
10、Jenkins
- 自动化构建和部署
项目遇到的问题
1、前端问题—路由切换问题
- vue-router导航切换时,如果两个路由都渲染同一个组件,组件会重复使用,组件的生命周期钩子(created)不会再被调用,使得一些数据无法根据path的改变得到更新。
- 即多次路由跳转到同一个页面,created()只执行一次,后面在进行跳转时不会执行
- 解决方案:通过vue监听机制解决

image-20210311194336555
2、前端问题—ES6模块化运行问题
ES6代码在浏览器的兼容性比较差,使用Babel把ES6代码转换为ES5的代码运行
3、MyBatisPlus生成19位id值问题
-
问题描述:mp生成的ip值为19位,js处理数据类型值时,只处理16位
-
解决方案:将Long改为String类型
4、跨域问题
- 问题描述:访问协议(http、https)、ip地址、端口号(9528、9001)
三者有任何一个不一样,就会产生跨域问题
- 解决方案:
在controller添加注解@CrossOrigin
通过Gateway网关解决,写一个配置类
上面只能使用一个,不然会失效
前端请求先经过网关 => 网关分发请求到对应接口 => 从接口获取数据并返回
5、413问题
-
问题描述:上传视频时,nginx有上传视频大小限制,如果超过,就会出现413错误
413描述:请求体过大
-
解决方案:在Nginx里配置客户端提交文件大小
-
响应状态码:413、跨域403、重定向302
6、Maven加载问题
- 问题描述:Maven加载项目时,不会加载src-java文件夹里面的xml类型文件

错误详情
-
解决方案:
1、复制xml文件到target目录
2、在maven中配置,在properties配置文件中指定xml文件夹
7、前端字符串转化为js对象问题
- 问题描述:登录过程中前端将用户信息放进cookie时,无法将js对象直接放进cookie里面

错误详情
-
问题解决:
加入cookie时将 js对象转化为字符串

错误详情
项目面试总结
1、项目描述
项目具体描述
1、项目总体介绍
示例:在线教育项目采用B2C商业模块、使用微服务架构,前后端分离开发
2、项目功能模块(你做的模块)
示例:在线教育项目分为前台系统(用户)和后台系统(管理员)
前台系统包括:首页数据显示、课程列表和详情、课程支付、课程视频播放、微信登录、微信支付等待
后台系统包括:权限管理、课程管理、统计分析、课程分类管理等等
我在这个项目主要负责前台微信登录和支付,负责后台权限管理和统计分析
3、项目涉及的技术栈
示例:项目采用前后端分离开发
前端技术包括:Vue、element-ui、nuxt、babel等等
后端技术包括:SpringBoot、SpringCloud、EasyExcel、Redis等等
第三方技术包含:阿里云OSS、视频点播、短信服务等等
2、这是一个项目还是一个产品
是一个产品;项目是从0开始搭建的
3、测试要求
首页和视频详情页qps单机qps要求 2000+
经常用每秒查询率来衡量域名系统服务器的机器的性能,其即为QPS
QPS = 并发量 / 平均响应时间
4、企业中的项目(产品)开发流程
一个中大型项目的开发流程:
1、需求调研(产品经理)
2、需求评审(产品/设计/前端/后端/测试/运营)
3、立项(项目经理、品管)
4、UI设计
5、开发
- 架构、数据库设计、API文档、MOCK数据、开发、单元测试
- 前端
- 后端
6、前后端联调
7、项目测试:黑盒白盒、压力测试(qps)、loadrunner
8、bug修改
9、回归测试
10、运维和部署上线
11、灰度发布
12、全量发布
13、维护和运营
5、系统中都有那些角色?数据库是怎么设计的?
前台:会员(学员)
后台:系统管理员、运营人员
后台分库,每个微服务一个独立的数据库,使用了分布式id生成器
6、视频点播是怎么实现的(流媒体你们是怎么实现的)
我们直接接入了阿里云的云视频点播。云平台上的功能包括视频上传、转码、加密、智能审核、监控统计等。
还包括视频播放功能,阿里云还提供了一个视频播放器。
7、前后端联调经常遇到的问题:
1、请求方式post、get
2、json、x-wwww-form-urlencoded混乱的错误
3、后台必要的参数,前端省略了
4、数据类型不匹配
5、空指针异常
6、分布式系统中分布式id生成器生成的id 长度过大(19个字符长度的整数),js无法解析(js智能解析16个长度:2的53次幂)id策略改成 ID_WORKER_STR
8、前后端分离项目中的跨域问题是如何解决的
后端服务器配置:我们的项目中是通过Spring注解解决跨域的 @CrossOrigin
也可以使用nginx反向代理、httpClient、网关
9、说说你做了哪个部分、遇到了什么问题、怎么解决的
问题1:
分布式id生成器在前端无法处理,总是在后三位进行四舍五入。
分布式id生成器生成的id是19个字符的长度,前端javascript脚本对整数的处理能力只有2的53次方,也就是最多只能处理16个字符解决的方案是把id在程序中设置成了字符串的性质
问题2:
项目迁移到Spring-Cloud的时候,经过网关时,前端传递的cookie后端一只获取不了,看了cloud中zuul的源码,发现向下游传递数据的时候,zull默认过滤了敏感信息,将cookie过滤掉了解决的方案是在配置文件中将请求头的过滤清除掉,使cookie可以向下游传递
10、分布式系统的id生成策略
分布式系统唯一ID生成方案汇总 - nick hao - 博客园
11、项目组有多少人,人员如何组成?
不要太教条,说说人一任职务
12、分布式系统的CAP原理
CAP定理:
指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可同时获得。
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(所有节点在同一时间的数据完全一致,越多节点,数据同步越耗时)
可用性(A):负载过大后,集群整体是否还能响应客户端的读写请求。(服务一直可用,而且是正常响应时间)
分区容错性(P):分区容错性,就是高可用性,一个节点崩了,并不影响其它的节点(100个节点,挂了几个,不影响服务,越多机器越好)
CA 满足的情况下,P不能满足的原因:
数据同步(C)需要时间,也要正常的时间内响应(A),那么机器数量就要少,所以P就不满足
CP 满足的情况下,A不能满足的原因:
数据同步(C)需要时间, 机器数量也多(P),但是同步数据需要时间,所以不能再正常时间内响应,所以A就 不满足
AP 满足的情况下,C不能满足的原因:
机器数量也多(P),正常的时间内响应(A),那么数据就不能及时同步到其他节点,所以C不满足
注册中心选择的原则:
Zookeeper:CP设计,保证了一致性,集群搭建的时候,某个节点失效,则会进行选举行的leader,或者半数以上节点不可用,则无法提供服务,因此可用性没法满足Eureka:AP原则,无主从节点,一个节点挂了,自动切换其他节点可以使用,去中心化
结论:
分布式系统中P,肯定要满足,所以我们只能在一致性和可用性之间进行权衡
如果要求一致性,则选择zookeeper,如金融行业
如果要求可用性,则Eureka,如教育、电商系统
没有最好的选择,最好的选择是根据业务场景来进行架构设计
13、前端渲染和后端渲染有什么区别
前端渲染是返回 json 给前端,通过 javascript 将数据绑定到页面上
后端渲染是在服务器端将页面生成直接发送给服务器,有利于 SEO 的优化
14、能画一下系统架构图吗


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)