Filebeat采集日志讲解(二)
文章目录课前三分钟Filebeat输出到kafka集群输出kafka发送到不同topic关于kafka更多配置Filebeat输出到LogstashFilebeat输出到Elasticsearch课前三分钟上节课我们讲述了关于Filebeat采集日志数据的一些基本使用,我们可以自定义输出一些我们想要的信息和格式。本节课我们将继续探讨Filebeat如何配置输出。filebeat的输出主要支持...
文章目录
课前三分钟
上节课我们讲述了关于Filebeat采集日志数据的一些基本使用,我们可以自定义输出一些我们想要的信息和格式。本节课我们将继续探讨Filebeat如何配置输出。
filebeat的输出主要支持一下几个组件:
- Elasticsearch
- Logstash
- Kafka
- Redis
- File
- Console
- Cloud
Console(控制台)输出上一节课我们测试功能的时候已经介绍了,主要是用来开发测试使用。还有一些其他的数据出口,像Logstash和Elasticsearch也是我们经常会用到的。本节课我们将重点介绍输出消息队列——kafka,也会简单介绍一下输出Logstash和Elasticsearch。
Filebeat输出到kafka集群
其实在日志系统中,与其说是Filebeat输出kafka,不如说是将每个Filebeat实例作为一个kafka的producer,实际上有多少个Filebeat就有多少个生产者,这样通过kafka可以实现高并发的日志集中处理。
输出kafka
output.kafka:
enabled: true
hosts: ["kafka1:9092","kafka2:9092","kafka3:9092"]
topic: logtest
codec.format:
string: '{"@timestamp":"%{[@timestamp]}","hostname":"%{[beat.hostname]}","log_type":"%{[fields.log_type]}","message":"%{[message]}"}'
说明:
- enabled,确定此模块是否启动,默认true;
- hosts,指定kafka集群地址,不建议配置单个,但也不建议把所有节点全配置上去,如果全配上注意负载均衡,关于负载均衡后面会介绍;
- topic,指定发送kafka的topic;
- codec.format,上一课已经详细介绍了,自定义输出格式和内容。
测试:
首先,我们进入kafka的bin目录,启动一个消费者
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic logtest --from-beginning
启动之后,logtest这个topic中的消息就会消费到控制台上了。
然后,我们启动Filebeat,并且往监控日志中增加一条信息。如果可以在kafka消费者终端看到我们刚刚写入并且按照自定义格式输出到控制台的消息,证明输出kafka已经走通。
发送到不同topic
经过上面的测试,我们已经知道我们已经把日志成功发送到kafka集群中了。不过上节课我们提到了,我们有很多种类的日志,有些时候我们并不想把所有日志都发送到同一个topic上,不便于分析处理也不便于日志的维护。所以我们一般会选择不同类别的日志写到不同的topic中。
首先,要在input中加入filed字段,上一节课字段分类已经讲述了。
fields:
log_type: system
然后,在配置topic输出:
topic: '%{[fields.log_topic]}'
这样就会根据新增加的字段log_type的值来决定发送到哪个topic中了。
关于kafka更多配置
到此,我们实现了Filebeat发送数据到指定kafka-topic。在实际应用中,我们还需要加一些配置来优化这一过程的性能。
required_acks:1
- ack策略,0表示不等待kafka端响应,1表示等待分区Leader响应,-1表示等待所有副本全部响应。默认是1。注意这里是-1不是all,这个配置值是int类型,all会报错。
compression:gzip
- 指定压缩方式,4选1,none,snappy,lz4和gzip。默认是gzip。
compression_level
- 设置gzip使用的压缩级别。将此值设置为0将禁用压缩。压缩级别必须在1(最佳速度)到9(最佳压缩)的范围内。增加压缩级别将减少网络使用,但会增加CPU使用率。默认值为4。
max_message_bytes
- 单条消息最大长度限制,这里指的是输出长度,并不单单指日志长度。超过长度的消息会被扔掉。默认值为1000000(字节)。这个值必须小于等于kafka能够接受的最大长度(message.max.bytes)。
timeout
- 等待kafka超时时间,默认30S。
broker_timeout
- 等待ack返回超时,默认10s。
client_id
- 用于记录,默认为:beats。
loadbalance:true
- 是否启动后复杂均衡,默认false。
worker
- 工作线程数,默认1。如果 loadbalance:true ,则实际线程数 = worker * hosts。
metadata
refresh_frequency
retry.max
retry.backoff
- kafka元数据配置。
- 刷新间隔。默认为10分钟。
- 重试次数,默认值为3。
- 重试之间的等待时间。默认值为250毫秒。
max_retries
- 消息发送失败重试次数,Filebeat默认会无限次重试且无法改变。(Logstash作为采集工具是也有此配置,并且可以选择重试次数,不过一般都会选择一直重试下去,就是阻塞。)
bulk_max_sizeedit
- 批量请求最大事件数,可以理解成日志条数。
Filebeat输出到Logstash
对于日志系统的其中一种架构(如下图),我们会用到Filebeat输出到Logstash这种方式。
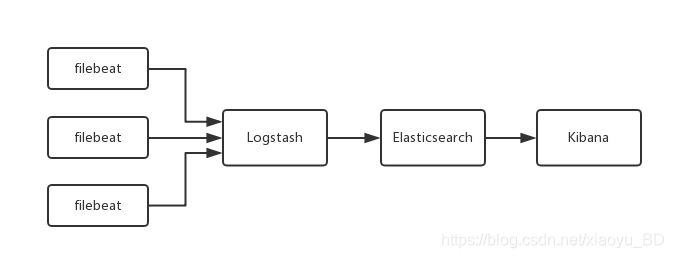
配置输出:
output.logstash:
hosts:[“127.0.0.1:5044”]
说明:
- 很简单,指定Logstash的地址和端口号。
Logstash配置输入:
input {
beats {
port => 5044
}
}
Filebeat输出到Elasticsearch
Filebeat输出到Elasticsearch是配置文件默认开启的输出。
配置输出:
output.elasticsearch:
hosts: ["10.45.3.2:9200", "10.45.3.1:9200"]
protocol: https
index:“%{[fields.log_type]} - %{+ yyyy.MM.dd}”
说明:
- hosts,指定es地址,也可以是https://10.45.3.2:9220。
- protocol,连接方式,默认http。
- index,写入Elasticsearch索引名字,可以指定自动动态配置。
- 之所以没有配置模版是因为不建议在filebeat中配置,建议在Elasticsearch端集中配置模版,方便管理。
更多文章关注公众号


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)