(三)ES基于Rest Client的JAVA API开发
ES的JAVA API开发文章目录ES的JAVA API开发1: ES的JAVA API开发介绍2:基于rest client开发demo2.1maven依赖2.2 建立客户端连接1: ES的JAVA API开发介绍ES提供几种客户端供使用,引入不同的maven依赖即可transport在ES7.0之后将会逐步去除当ES的版本是6.0.0以上时,其建议我们使用官方的Java High-...
·
ES的基于High-Level Rest Client的JAVA API开发
文章目录
1: ES的JAVA API开发介绍
ES提供几种客户端供使用,引入不同的maven依赖即可
- transport模式:不推荐
在ES7.0之后将会逐步去除,使用Java API时,数据写入客户端应该把bulk请求轮询 发送到各个节点,当设置client.transport.sniff为true(默认为false) 时,写入节点为所有数据节点,否则节点列表为构建客户端对象时传入的节 点列表。 - 推荐使用High-Level Rest
写入时不会因为配置的节点不全导致请求只发送给配置的部分节点

1.1:High-Level Rest Client简介
每个方法API都可以调用同步或异步。
- 同步方法立刻返回一个响应对象
- 名称以async后缀结尾的异步方法则需要传递一个侦听器参数(listener),一旦接收到响应或错误,该参数就会被通知(在低级客户端管理的线程池上),后续可以获取异步执行结果进行逻辑处理。
High-Level Rest主要API简介:具体看官网
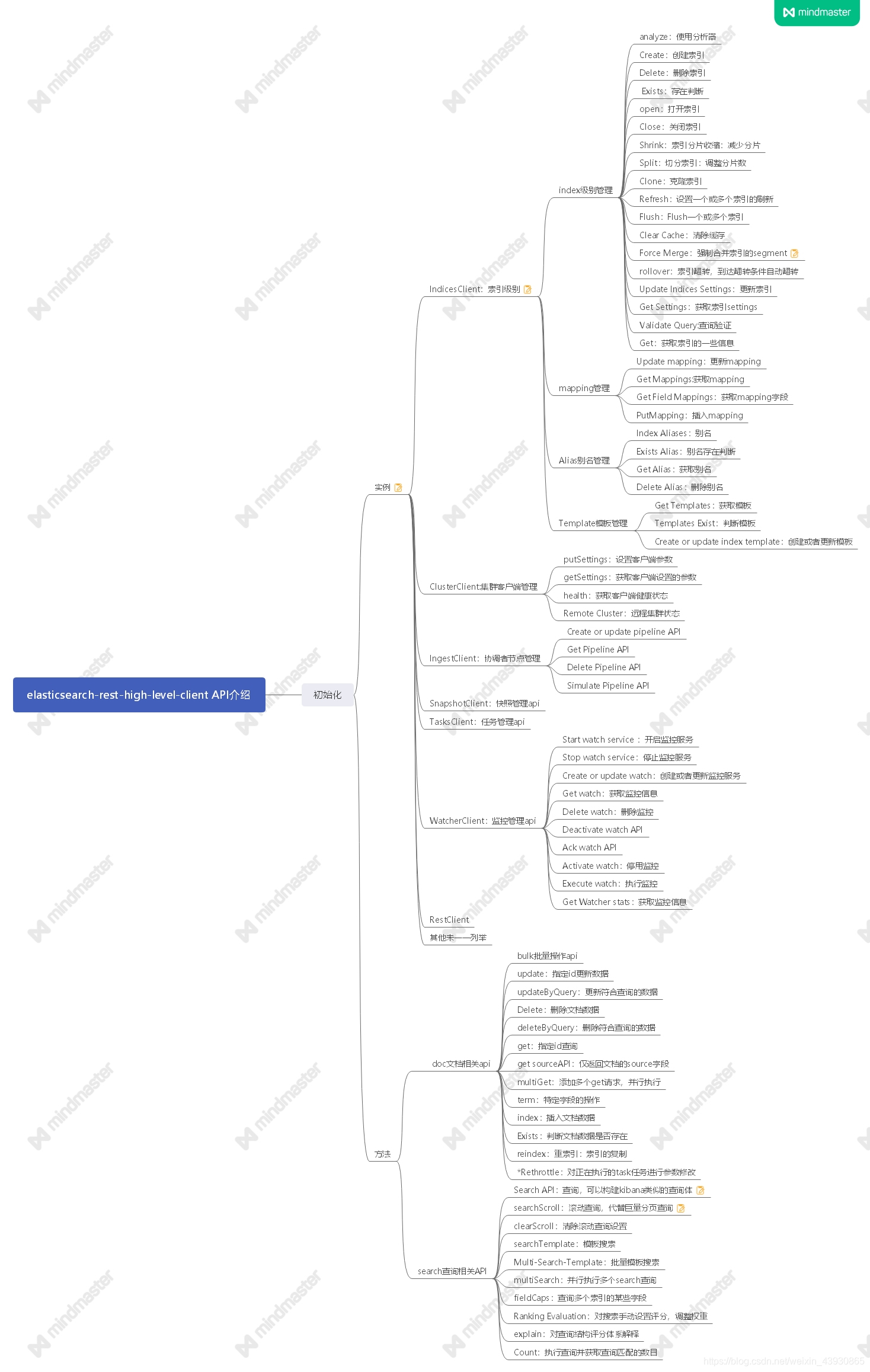
2:基于rest client开发demo
2.1:maven依赖
<!--仅需要这一个依赖-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${es.client.version}</version> //比如7.12.0
</dependency>
2.2: 客户端连接
获取客户端,通过设置IP和端口连接到特定Elasticsearch集群,是使用Elasticsearch提供的API之前的必要工作。
private static RestHighLevelClient client;
private static void init() {
client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.2.101", 9300, "http"),
new HttpHost("192.168.2.102", 9300, "http"),
new HttpHost("192.168.2.103", 9300, "http")
));
}
//注意关闭连接。完成Elasticsearch业务操作后,需要调用“RestHighLevelClient.close()”关闭所申请的资源。
private static void close() {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
2.3:数据写入
1:写入数据到索引中,索引的mapping提前设置完毕
private static void index() {
//构建索引请求
IndexRequest indexRequest = new IndexRequest("test_field", "type1","5");
//写入格式包括json,map,构建XContentBuilder三种方式
//此处采用map进行构建
HashMap<String, Object> hashMap = new HashMap<>();
hashMap.put("name", "lisan");
hashMap.put("age",5);
indexRequest.source(hashMap);
//执行请求
try {
//得到请求返回情况
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
String id = indexResponse.getId();
System.out.println("id:"+id );
} catch (IOException e) {
e.printStackTrace();
}
}
2:第二种查询方式
private static void queryData(RestClient restClient) throws Exception {
Map<String, String> params = Collections.singletonMap("pretty", "true");
Response rsp = null;
try {
rsp = restClient.performRequest("GET", "/" + index+ "/" + type+ "/" + id,params);//performRequest可以构建各种请求进行执行
Assert.assertEquals(rsp.getStatusLine().getStatusCode(), HttpStatus.SC_OK);
LOG.info("queryData,response entity is : " + EntityUtils.toString(rsp.getEntity()));
} catch (Exception e) {
Assert.fail();
}
}
查看写入结果:查看命令
GET test_field/type1/_search
{
"query":{
"bool": {
"must":[
{"match":{"name": "lisan"}},
{ "match":{"age":5}}
]
}
}
}
结果:可知写入成功。
"hits" : [
{
"_index" : "test_field",
"_type" : "type1",
"_id" : "5",
"_score" : 2.2039728,
"_source" : {
"name" : "lisan",
"age" : 5
}
}
]
2.4:get查询 api
示例
private static void get(){
GetRequest getRequest = new GetRequest("test_field", "type1","5");
try {
//documentFields 就是查询到的文档内容,可以使用documentFields.toString
GetResponse documentFields = client.get(getRequest, RequestOptions.DEFAULT);
String id = documentFields.getId();
Map<String, Object> source = documentFields.getSource();
Object name1 = source.get("name");
System.out.println(id+" name:"+name1);
} catch (IOException e) {
e.printStackTrace();
}
}
1:指定索引中的文档id进行查询
private static void getIndex(RestHighLevelClient highLevelClient, String index, String type, String id) {
try {
GetRequest getRequest = new GetRequest(index, type, id);
String[] includes = new String[] { "message", "test*" };
String[] excludes = Strings.EMPTY_ARRAY;
FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);
getRequest.fetchSourceContext(fetchSourceContext);
getRequest.storedFields("message");
GetResponse getResponse = highLevelClient.get(getRequest, RequestOptions.DEFAULT);
LOG.info("GetIndex response is {}", getResponse.toString());
} catch (Exception e) {
LOG.error("GetIndex is failed,exception occurred.", e);
}
}
使用api进行查询,太大的数据量一般建议使用Scrolld游标查询
2:游标查询
private static String searchScroll(RestHighLevelClient highLevelClient,String index) {
String scrollId = null;
try {
final Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1L));
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.scroll(scroll);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("title", "Elasticsearch"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = highLevelClient.search(searchRequest, RequestOptions.DEFAULT);
scrollId = searchResponse.getScrollId();
SearchHit[] searchHits = searchResponse.getHits().getHits();
LOG.info("SearchHits is {}", searchResponse.toString());
while (searchHits != null && searchHits.length > 0) {
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(scroll);
searchResponse = highLevelClient.searchScroll(scrollRequest, RequestOptions.DEFAULT);
scrollId = searchResponse.getScrollId();
searchHits = searchResponse.getHits().getHits();
LOG.info("SearchHits is {}", searchResponse.toString());
}
} catch (Exception e) {
LOG.error("SearchScroll is failed,exception occured.", e);
return null;
}
return scrollId;
}
使用完毕记得关闭游标
private static void clearScroll(RestHighLevelClient highLevelClient,String scrollId) {
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
ClearScrollResponse clearScrollResponse;
try {
clearScrollResponse = highLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT));
if (clearScrollResponse.isSucceeded()) {
LOG.info("ClearScroll is successful.");
} else {
LOG.error("ClearScroll is failed.");
}
} catch (IOException e) {
LOG.error("ClearScroll is failed,exception occured.", e);
}
}
2.5:bulk批量操作 api
作用是执行批量操作,例如建立索引,更新索引或者删除索引。项目一般使用此api进行数据的写入操作
bulk优化
1:使用bulk命令进行批量索引数据时,每批次提交的数据大小为5~15MB。比如每条数据大小为1k,那么建议批量提交的数据条数为5000条。
当前集群的最佳批量请求大小,可以从5MB开始测试,缓慢增加这个大小,直到写入性能不能提升为止。
2:每个批量请求中只处理一个索引的数据,一个bulk请求只写入一个索引的数据,不建议一个bulk请求同时写入多个索引的数据,不同索引的数据分多个bulk请求提交。
1:概念
bulk批量请求可用于使用单个请求执行多个(create、index、update、delete)操作
index(最常用) : 如果文档不存在就创建他,如果文档存在就更新他
create : 如果文档不存在就创建他,但如果文档存在就返回错误
使用时一定要在metadata设置_id值,他才能去判断这个文档是否存在
update : 更新一个文档,如果文档不存在就返回错误
使用时也要给_id值,且后面文档的格式和其他人不一样
delete : 删除一个文档,如果要删除的文档id不存在,就返回错误
BulkResponse的api:
2:批量代码:用source构建数据
private static void bulk(){
//1:构建bulk批量操作
BulkRequest bulkRequest = new BulkRequest();
//2:通过add操作实现一个请求执行多个操作
//source构建数据时,k,v,k,v形式。索引-类型-文档id.source(数据)
bulkRequest.add(new IndexRequest("test_field", "type1","6").source("name","lisi","age",5));
//3:同步执行操作:可通过for等循环控制,实现一次导入多条数据:
try {
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
RestStatus status = bulk.status();
System.out.println(status);
} catch (IOException e) {
e.printStackTrace();
}
}
查看批量导入结果:成功
{
"_index" : "test_field",
"_type" : "type1",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "lisi",
"age" : 5
}
}
2.1:BulkResponse 的api
1:检查批量响应的执行状态
if (bulk.hasFailures()){//返回true,至少一个失败,进行迭代处理
for (BulkItemResponse itemResponse : bulk) {
BulkItemResponse.Failure failure = itemResponse.getFailure();
}
}
3:第二种批量导入:使用XContentBuilder创建json数据+异步提交
项目中使用此方法的较多,利于schema的管理
private static void bulk() {
//1:构建bulk批量操作
BulkRequest bulkRequest = new BulkRequest();
//2:通过add操作实现一个请求执行多个操作
// bulkRequest.add(new IndexRequest("test_field", "type1","6").source("name","lisi","age",5));
try {
//:3:使用XContentBuilder创建json数据
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder();
//开始
xContentBuilder.startObject();
//项目中一般通过schema进行fields的加载获取,再进行XContentBuilder 的构建
xContentBuilder.field("name", "wangwu");
xContentBuilder.field("age", 8);
//构建结束,
xContentBuilder.endObject();
bulkRequest.add(new IndexRequest("test_field", "type1", "7").source(xContentBuilder));
} catch (IOException e) {
e.printStackTrace();
}
//4:执行操作
try {
//同步执行
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
//异步执行
ActionListener<BulkResponse> actionListener = new ActionListener<BulkResponse>() {
@Override
public void onResponse(BulkResponse bulkItemResponses) {
/*当执行成功完成时调用。该响应作为参数提供,并包含执行的每个操作的单个结果的列表。请注意,一个或多个操作可能已失败,而其他操作已成功执行*/
for (BulkItemResponse bulkItemResponse : bulkItemResponses) {
DocWriteResponse itemResponse = bulkItemResponse.getResponse();
if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX
|| bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) {
IndexResponse indexResponse = (IndexResponse) itemResponse;
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) {
UpdateResponse updateResponse = (UpdateResponse) itemResponse;
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) {
DeleteResponse deleteResponse = (DeleteResponse) itemResponse;
}
}
}
@Override
public void onFailure(Exception e) {
/*批量失败时*/
}
};
client.bulkAsync(bulkRequest, RequestOptions.DEFAULT, actionListener);
RestStatus status = bulk.status();
System.out.println(status);
} catch (IOException e) {
e.printStackTrace();
}
}
查看结果:成功
{
"_index" : "test_field",
"_type" : "type1",
"_id" : "7",
"_score" : 1.0,
"_source" : {
"name" : "wangwu",
"age" : 8
}
}
2.6:搜索索引信息
查询索引内容,并进行过滤排序、翻页、高亮显示等。
private static void search(RestHighLevelClient highLevelClient,String index) {
try {
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("user", "kimchy1"));
//Specifying Sorting
searchSourceBuilder.sort(new FieldSortBuilder("_doc").order(SortOrder.ASC));
// Source filter
String[] includeFields = new String[] { "message", "user", "innerObject*" };
String[] excludeFields = new String[] { "postDate" };
searchSourceBuilder.fetchSource(includeFields, excludeFields);// Control which fields get included or
// excluded
// Request Highlighting`在这里插入代码片`
HighlightBuilder highlightBuilder = new HighlightBuilder();
HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user"); // Create a field highlighter for
// the user field
highlightBuilder.field(highlightUser);
searchSourceBuilder.highlighter(highlightBuilder);
searchSourceBuilder.from(0);
searchSourceBuilder.size(2);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = highLevelClient.search(searchRequest, RequestOptions.DEFAULT);
LOG.info("Search response is {}.", searchResponse.toString());
} catch (Exception e) {
LOG.error("Search is failed,exception occurred.", e);
}
}
2.7:删除索引
private static void deleteIndex(RestHighLevelClient highLevelClient, String index) {
try {
DeleteIndexRequest request = new DeleteIndexRequest(index);
DeleteIndexResponse delateResponse = highLevelClient.indices().deleteIndex(request, RequestOptions.DEFAULT));
if (delateResponse.isAcknowledged()) {
LOG.info("Delete index is successful");
} else {
LOG.info("Delete index is failed");
}
} catch (Exception e) {
LOG.error("Delete index : {} is failed, exception occurred.", index, e);
}
}
3:kafka+sparkstreaming+es+hbase架构
我们的数据处理速度,入库5000/s/台左右
参考文献:es官方开发文档

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)