Java集成elasticsearch
Java集成elasticsearch
Java集成elasticsearch之简单的使用
Linux下载安装es
1、ES 7.x 及之前版本,选择 Java 8
2、ES 8.x 及之后版本,选择 Java 17 或者 Java 18,建议 Java 17,因为对应版本的 Logstash 不支持 Java 18
3、Java 9、Java 10、Java 12 和 Java 13 均为短期版本,不推荐使用
本文使用的是7.17,下载完后直接解压即可
下载地址:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.6-linux-x86_64.tar.gz
es因为安全原因是不能使用root用户启动,所以如果需要新建用户使用以下命令新建即可:
1、groupadd centos #创建es组
2、useradd centos -g es -p 密码 #-g指定用户 -p设置密码
3、chown centos:centos -R elasticsearch-7.17.3/ #给予centos用户es文件夹下的权限
es启动与简单使用
es因为安全问题不支持使用root启动的,所以应使用上面新建的用户去启动,需要先切换到创建的用户 su centos
-
使用
./bin/elasticsearch -d启动。 说明: -d 是启动到后台 -
查看日志:
tail -f ./logs/elasticsearch.log -
启动后可在命令行输入
curl http://127.0.0.1:9200或在浏览器访问http://ip:9200/(需要关闭防火墙或开放端口) 如出现下面内容说明启动成功。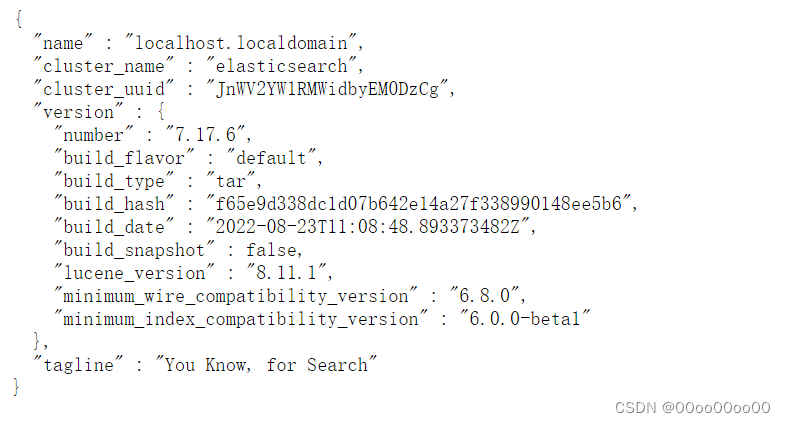
-
可以使用如下命令进行简单测试:
查看索引: curl -X GET "http://127.0.0.1:9200/_cat/indices?v
使用put请求创建索引: curl -X PUT http://127.0.0.1:9200/myindex
使用delete请求删除索引: curl -X DELETE http://127.0.0.1:9200/myindex
查看索引请求的返回信息如下,status字段返回状态说明
Green为最佳状态。Yellow即数据和集群可用,但是集群的备份有的是坏的。Red即数据和集群都不可用
Java集成
第一种,spring提供
导入依赖:文中有使用其它依赖较多,就不贴出来了 fastjson、lang3、lombok、mybatis-plus、druid、jakarta
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
创建实体类,实体类仅供参考
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "myindex", shards = 5, replicas = 1)// myindex 必须全小写
public class GoodsInfo implements Serializable {
/**
* @Id 主键id
* String 分两种:text 可分词,不参加聚合、keyword,不可分词,数据会根据完整匹配,可参与聚合
* ik_max_word :会对文本进行最细粒度的拆分,
* ik_smart:会对文本进行最粗粒度的拆分
* 索引时使用ik_max_word、搜索时使用ik_smart
* 分词器:analyzer 1、插入文档时,将text类型字段做分词,然后插入倒排索引。2、在查询时,先对text类型输入做分词,再去倒排索引搜索
* 分词器:如果想要“索引”和“查询”, 使用不同的分词器,那么 只需要在字段上 使用 search_analyzer。这样,索引只看 analyzer,查询就看 search_analyzer。
* 此外,如果没有定义,就看有没有 analyzer,再没有就去使用 ES 预设。
*/
@Id
private String goodId;
@Field(type = FieldType.Keyword)
private String userId;
@Field(type = FieldType.Keyword)
private String classId;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String goodTitle;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String goodIntro;
@Field(type = FieldType.Keyword)
private String goodImg;
@Field(type = FieldType.Keyword)
private String goodAddress;
@Field(type = FieldType.Double)
private Double price;
@Field(type = FieldType.Integer)
private int sts;
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd")
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd", timezone = "GMT+8")
private String time;
}
简单的curd
(想找 稍微复杂 的查询可以跳过这点。)
创建DiscussPostRepository(其实就是个mapper),继承spring提供的ElasticsearchRepository<T, ID>
import com.example.elasticsearch.entity.GoodsInfo;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
/**
* PagingAndSortingRepository 可以使用 Page<T> findAll(Pageable pageable); 分页
* ElasticsearchRepository<T,ID> T为实体类,ID为实体类的id,对应id的类型的包装类 id需为主键
* T只能针对单个对象进行创建,实例化填充object也不行,
* GoodsInfo只是一个实体类,并不影响后面的使用,所以将GoodsInfo改成自己的也是可以的,String为实体类里面的id
*/
@Repository
public interface DiscussPostRepository extends ElasticsearchRepository<GoodsInfo,String> {
//做数据预热
@Select("select * from goods_info order by time desc")
List<GoodsInfo> qryAllGoods();
}
简单的curd父类已经提供了,我们直接使用就行
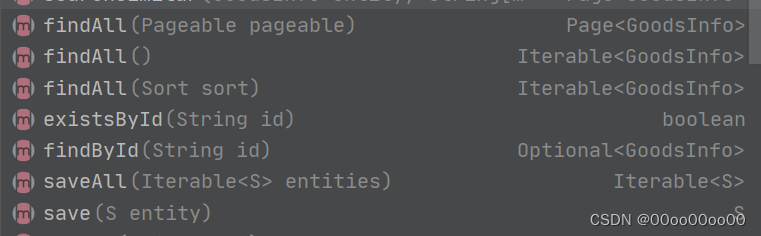
都是些简单的代码就不贴了,在service中使用mapper是一样的。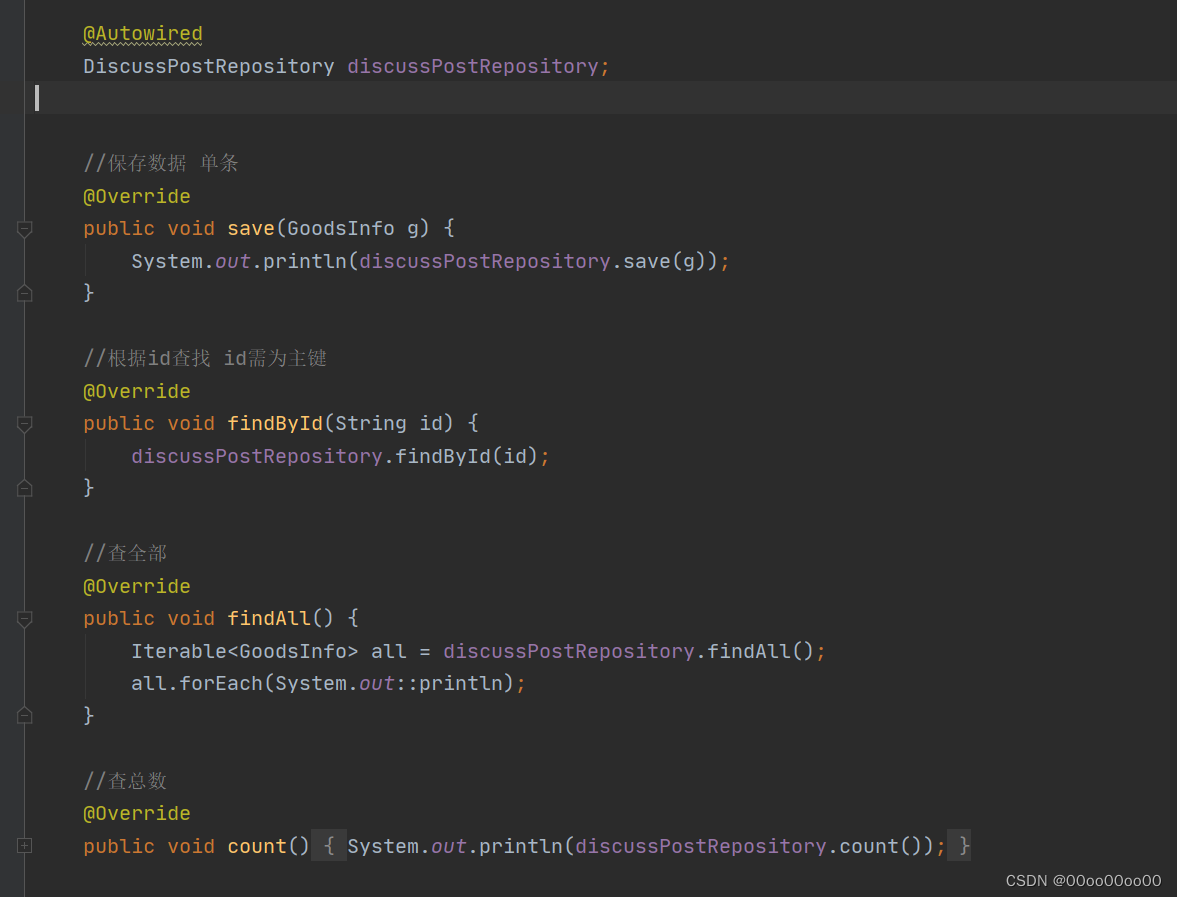
稍微复杂
需要先构建一个高级客户端RestHighLevelClient
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
@Component
public class ElasticSearchConfig {
//请求地址 http://ip
@Value("${elasticsearch.url}")
private String url;
//索引
@Value("${spring.elasticsearch.index}")
private String index;
//请求端口 9200
@Value("${elasticsearch.port}")
private int port;
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
//http://127.0.0.1:9200
new HttpHost(url,port)
)
);
return client;
}
}
service:
public interface GoodsInfoElasticService {
void queryBuild(String keyword,String beginTime,String endTime, int page, int size);
}
serviceImpl:
public class GoodsInfoElasticServiceImpl implements GoodsInfoElasticService {
@Autowired
RestHighLevelClient client;
/**
* QueryBuilders.
* 精确查询:term、terms 范围查询:range 模糊查询:wildcardQuery
* term :单值查询 类似 =
* terms:多值查询,类似in
* range:范围查询 类似 between and
* wildcardQuery:模糊查询 like
*
* 匹配查询:match、multiMatch
* match:单字段匹配一个值 根据分词后的结果去查询,如果分词后的结果有命中一个,就会返回,模糊查询
* multiMatch:多字段匹配同一个值
*
* 复合查询 bool :must、must_not、should 、filter
* must:必须满足条件
* must_not:必须不满足条件
* should:应该满足条件
* filter:过滤,关闭评分,提高查询效率
*
* 以下聚合查询
* 统计:max、min、sum、avg、count
* stats:一并获取max、min、sum、count、AVG统计
* extendedStats:追加方差、标准差等统计指标
* ardinality:去重
* 分组:单字段分组、多字段分组、筛选后分组
*/
/**
* 1、SearchRequest 构建查询请求
* 2、SearchSourceBuilder 构建请求体(查询条件)
* QueryBuilders 查询条件 --> termQuery()、termsQuery()、rangeQuery() 范围查询 、wildcardQuery()通配符查询(支持* 匹配任何字符序列,包括空 避免*开始,会检索大量内容造成效率缓慢)、idsQuery()只根据id查询
* 、fuzzyQuery()模糊查询、前缀匹配查询 prefixQuery("name","hello");
* AggregateBuilders 聚合条件 --> min、max、sum、range、terms、stats、extendedStats
*/
@Override
public void queryBuild(String keyword, String beginTime, String endTime, int page, int size) {
try {
SearchRequest request = new SearchRequest(index);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//组建模糊查询 keyword:例 hello world 会拆分存储,加keyword不进行分词搜索
if (StringUtils.isNotBlank(keyword)) {
boolQueryBuilder.must(QueryBuilders.wildcardQuery("goodTitle.keyword", "*" + keyword + "*"));
//多字段匹配 operator: or 表示 只要有一个词在文档中出现则就符合条件,and表示每个词都在文档中出现则才符合条件
// boolQueryBuilder.must(QueryBuilders.multiMatchQuery("数据", "goodTitle","goodIntro").operator(Operator.OR));
}
//组建时间范围查询
if (StringUtils.isNotBlank(beginTime) && StringUtils.isNotBlank(endTime)) {
beginTime = StringUtils.join(beginTime, "000000");
endTime = StringUtils.join(endTime, "999999");
boolQueryBuilder.filter(QueryBuilders.rangeQuery("time.keyword").gte(beginTime).lte(endTime));
}
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.from((page - 1) * size);
searchSourceBuilder.size(size);
//fetchSource(string[],string[]) 第一个数组表明需要哪些字段,第二个是不需要哪些字段 类似 select id,name,age
searchSourceBuilder.fetchSource(new String[]{"goodTitle", "goodId", "userId", "classId", "goodIntro"}, new String[]{});
request.source(searchSourceBuilder);
SearchResponse response = client.restHighLevelClient().search(request, RequestOptions.DEFAULT);
//搜索结果
SearchHits hits = response.getHits();
// 匹配到的总记录数
long totalHits = hits.getTotalHits().value;
// 得到匹配度高的文档
SearchHit[] searchHits = hits.getHits();
List<GoodsInfo> goodsInfos = new ArrayList<>();
if (null != searchHits && searchHits.length > 0) {
for (SearchHit searchHit : searchHits) {
String sourceString = searchHit.getSourceAsString();
GoodsInfo goodsInfo = JSONObject.parseObject(sourceString, GoodsInfo.class);
goodsInfos.add(goodsInfo);
}
}
for (int i = 0; i < goodsInfos.size(); i++) {
System.out.println(goodsInfos.get(i));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
第二种:es提供
增加如下依赖:
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.0.1</version>
</dependency>
创建客户端连接工具类
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.util.Arrays;
/**
* @author Liner
* todo ES连接配置工具
* @date 2021/12/9 21:36
*/
@Component
public class ElasticSearchConfig {
@Value("${elasticsearch.url}")
private String url;
@Value("${spring.elasticsearch.index}")
private String index;
@Value("${elasticsearch.port}")
private int port;
public static ElasticsearchClient client;
//http集群
public ElasticsearchClient elasticsearchClient(){
// final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
// credentialsProvider.setCredentials(
// AuthScope.ANY, new UsernamePasswordCredentials(account, passWord));//设置账号密码
RestClientBuilder builder = RestClient.builder(new HttpHost(url,port));
// RestClientBuilder builder = RestClient.builder(httpHosts)
// .setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
// Create the low-level client
RestClient restClient = builder.build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
client = new ElasticsearchClient(transport);//获取连接
return client;
}
}
import co.elastic.clients.elasticsearch.core.*;
import co.elastic.clients.elasticsearch.core.ExistsRequest;
import co.elastic.clients.elasticsearch.indices.*;
import com.alibaba.fastjson.JSONObject;
import com.example.elasticsearch.commons.ElasticSearchConfig;
import com.example.elasticsearch.commons.ElasticSearchConfigF;
import com.example.elasticsearch.entity.GoodsInfo;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Component
@Slf4j
public class ElasticSearchUtil {
@Autowired
ElasticSearchConfig client;
/**
* 创建索引
*
* @param index 索引名
* @param type 分片
* @param val
* @return
*/
public String createIndex(String index, String type, String val) {
if (existsIndex(index)){
throw new RuntimeException("索引已经存在");
}
CreateIndexResponse createResponse = null;
try {
createResponse = client.elasticsearchClient().indices().create(
new CreateIndexRequest.Builder()
.index(index)
// .aliases("foo",
// new Alias.Builder().isWriteIndex(true).build()
// )
.build()
);
log.info(String.valueOf(createResponse));
return index;
} catch (Exception e) {
throw new RuntimeException("创建索引失败,索引名:" + index + " 信息:" + createResponse);
}
}
//DELETE /book
// 删除索引
public boolean deleteIndex(String index){
if (!existsIndex(index)) {
throw new RuntimeException("索引不存在");
}
try {
//创建删除索引请求
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest.Builder().index(index).build();
//执行
return client.elasticsearchClient().indices().delete(deleteIndexRequest).acknowledged();
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("索引删除失败");
}
}
/**
* 判断索引是否存在
*
* @param index 索引
* @return
*/
public boolean existsIndex(String index) {
boolean exists = false;
try {
exists = client.elasticsearchClient().indices().exists(new co.elastic.clients.elasticsearch.indices.ExistsRequest.Builder().index(index).build()).value();
//exists = client.elasticsearchClient().indices().existsIndexTemplate(new ExistsIndexTemplateRequest.Builder().name(index).build()).value();
} catch (IOException e) {
e.printStackTrace();
}
return exists;
}
/**
* 查询id数据是否存在,id为主键
*
* @param index 索引
* @param id 主键id
* @return
*/
public boolean existsDocumentById(String index, String id) {
if (!existsIndex(index)) {
log.info("索引不存在:" + index);
return false;
}
boolean exists = false;
try {
exists = client.elasticsearchClient().exists(new ExistsRequest.Builder().index(index).id(id).build()).value();
return exists;
} catch (Exception e) {
e.printStackTrace();
}
return exists;
}
/**
* 根据主键id删除文档
*
* @param index
* @param id
*/
public void deleteDocumentById(String index, String id) {
if (!existsIndex(index)) {
log.info("索引不存在:" + index);
throw new RuntimeException("索引不存在:" + index);
}
try {
if (existsDocumentById(index, id)) {
DeleteResponse delete = client.elasticsearchClient().delete(new DeleteRequest.Builder().index(index).id(id).build());
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 根据id获取文档
*
* @throws IOException
*/
public <T> T getDocumentById(String index, String id, Class<T> clazz) throws IOException {
// get /index/_doc/1
GetRequest getRequest = new GetRequest.Builder().index(index).id(id).build();
GetResponse<T> bookGetResponse = client.elasticsearchClient().get(getRequest, clazz);
T result = bookGetResponse.source();
return result;
}
/**
* 根据id更新文档
*/
public <T> void updateDocument(String index, String id, Class<T> tClass) throws IOException {
UpdateResponse<T> personUpdateResponse = client.elasticsearchClient().update(
new UpdateRequest.Builder<T, Object>()
.index(index)
.id(id)
.doc(tClass)
.build()
, tClass);
// 执行结果
System.out.println(personUpdateResponse.result());
}
/**
* 新增数据,如果索引下存在主键id数据则会替换
*
* @param index 索引
* @param id 主键id
* @param tClass 实体类class
* @param <T>
* @throws IOException
*/
public <T> String createDocument(String index, String id, T tClass){
IndexResponse indexResponse;
try {
// 创建添加文档的请求
IndexRequest<T> indexRequest = new IndexRequest.Builder<T>().index(index).document(tClass).id(id).build();
// 执行
indexResponse = client.elasticsearchClient().index(indexRequest);
}catch (Exception e){
throw new RuntimeException("查询失败");
}
return indexResponse.id();
}
/**
* 批量新增数据,暂时用不了,需要指定主键id,如果有指定的class可以循环遍历新增
* @param index 索引
* @param id 主键id
* @param tClass 实体类class
* @param <T>
*/
public <T> void createDocumentAll(String index, String id, List<T> tClass){
try {
BulkRequest.Builder br = new BulkRequest.Builder();
for (T product : tClass) {
br.operations(op -> op
.index(idx -> idx
.index(index)
.id(id)
.document(product)
)
);
}
}catch (Exception e){
e.printStackTrace();
}
}
}
es官方提供的暂时没有写出复杂的查询构建。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)