MongoDB高效查询之索引机制
Mongo高级用法_踩踩踩从踩的博客-CSDN博客前言本篇文章会继续介绍MongoDB高效查询中的索引机制,主要包括什么是索引、索引的作用,全面介绍MongoDB中索引,以及如何使用索引来优化查询,查询性能分析 多键索引,通配符索引,二维空间索引;在mongoDB中 索引来高效查询 ,如何操作管理索引;MangoDB中使用索引考虑的因素, 这都是MongoDB 如何高效查询的基础,虽然没有es那么
前言
本篇文章会继续介绍MongoDB高效查询中的索引机制,主要包括什么是索引、索引的作用,全面介绍MongoDB中索引,以及如何使用索引来优化查询,查询性能分析 多键索引,通配符索引,二维空间索引 ;在mongoDB中 索引来高效查询 ,如何操作管理索引;MangoDB中使用索引考虑的因素, 这都是MongoDB 如何高效查询的基础,虽然没有es那么强大,但也有自己的一套规则优化。
索引

这个在 二叉 以及 平衡树中,保证数据查询快速,以及平衡度的,左平衡和右平衡。这都是在索引下面 保证查询 ,但插入时会降低效率了。
一般这个索引的节点都会有 列值和行地址。
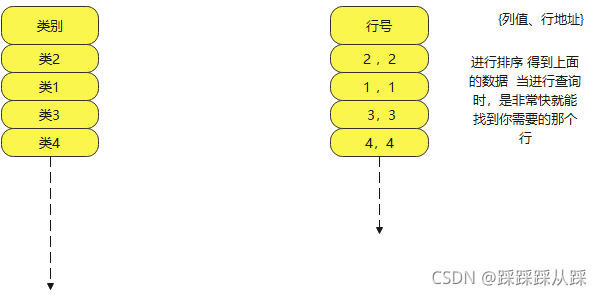
MongoDB中的索引类型

它有自己比较特色的索引,包括单字段索引,在添加数据时,就会默认创建索引。
MongoDb中如何创建索引
MongoDB使用 createIndex() 方法来创建索引, createIndex()方法基本语法格式如下所示:
// 创建索引的语法
db.collection.createIndex(keys, options)- keys 文档类型值
- options 文档类型值

/* 复合索引,索引的顺序跟查询排序相关联 */
db.inventory.createIndex({status:1, qty:-1});
// 上面的索引一升一降,查询排序的模式必须与索引键的模式匹配或逆向
{status:-1, qty:1}
{status:1, qty:-1}
db.inventory.find().sort({status:1, qty:-1}).explain();
db.inventory.find().sort({status:-1, qty:1}).explain();
// 下面的模式就不能够命中
{status:1, qty:1}
{status:-1, qty:-1}
/*多键索引,数组索引*/
db.inventory.createIndexes();
// 两个及以上多键索引,无法做复合索引这种复合索引的模式,就和关系型数据库中索引就很像了。
复合索引,还有前缀匹配。这个
针对数组 而提出的 多键索引。
/* 单字段索引,根据物品名称查询物品 */
db.inventory.createIndex({item:1});索引属性
这都是mongodb中比较特色的点,
- 唯一索引
- 部分索引
- 稀疏索引
- TLL索引

这种属于添加了过期机制的。 删掉数据。
- 不区分大小写
这对比前面的索引的。都是以简单方式 2进制进行对比的。 这里可以设置英语 法语这些支持。
MongoDB中的索引
一般索引

有序的数据存储结构。 最小 最大的索引 可以正着走 反着走,单字段索引 灵活度是很强的。

读和写都是基于内存的
可以对调着走。
尽量少建索引,因为会降低写的性能的。
多键索引

通配符索引
// 创建索引的语法
{ "userMetadata" : { "likes" : [ "dogs", "cats" ] } }
{ "userMetadata" : { "dislikes" : "pickles" } }
{ "userMetadata" : { "age" : 45 } }
{ "userMetadata" : "inactive" }db.userData.createIndex( { "userMetadata.$**" : 1 } )根据内容通配符去创建索引,
二维空间索引
- 2d,对在二维平面上坐标点为存储的数据使用索引,是2.2版本中的坐标对。
-
GeyHaystack索引是一个特殊的索引,该索引被优化以在较小的区域上返回结果。GeHaystack索引提高了使 用平面几何图形的查询的性能。
平面坐标对的形式
// 数组形式,推荐使用
location: [-73.856077, 40.848447]
// 内嵌文档形式,第一个为经度,第二个为纬度,忽略字段名
location: { field1: -73, field2: 41,6 }

球体空间索引



这种球体的方式,可以创建比较大的空间。
Hash索引
- 支持任意单字段的Hash索引,不能创建多键的Hash索引
- Hash值会发生碰撞,Hash索引不能设定为唯一约束
- 支持相等查询,不支持范围查询
- 创建hash索引的字段也可以创建其他索引
- hashed索引不支持不能转换为64位整数的浮点值,大于2的53次方的浮点值
// 创建一个hash索引
db.collection.createIndex( { field: "hashed" } )
使用索引考虑的因素
对应用程序的查询有深刻的理解 确定将要运行的查询的类型,以便可以构建引用这些字段的索引
- 通过索引来提高查询效率 当索引包含该查询扫描的所有字段时,该索引就支持该查询
- 通过索引对查询结果进行排序 为了支持有效的查询,在指定索引字段的顺序和排序顺序时
- 确保索引有足够的内存 内存有限的情况下,MongoDB通过保存最近的值来淘汰老值
- 使用能够覆盖索引的查询 查询使用索引缩小结果范围,可以限制可能检索的文档数量
管理索引的话 直接用下面的命令就行。


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)