数据大屏+词云SpringBoot+Redis+Jieba(后端项目-源码分享)
一、项目描述1 后端项目1.1 项目简介让我们先理解这个项目的原理先整理好前端需要的各种图表的数据,将其SQL语句存入query_statement表再定期执行这些SQL,执行结果放Redis最后提供一个接口让前端取数据项目使用SpringBoot-Redis-Jieba,为大屏项目提供数据接口(配套前端项目)一个基于 SrpingBoot、Redis、Jieba 框架的 " 数据大屏项目 "项目
一、项目描述
1 后端项目
1.1 项目简介
让我们先理解这个项目的原理
- 先整理好前端需要的各种图表的数据,将其SQL语句存入query_statement表
- 再定期执行这些SQL,执行结果放Redis
- 最后提供一个接口让前端取数据
项目使用SpringBoot-Redis-Jieba,为大屏项目提供数据接口(配套前端项目)
- 一个基于 SrpingBoot、Redis、Jieba 框架的 " 数据大屏项目 "
- 项目使用定时器,定期从数据库执行n个统计SQL,将统计结果存放Redis中,前端定时刷新请求数据都从redis中取,减轻数据库压力
- 通过Jieba分词统计词频最高的词,前端使用词云展示
- 请拉取 main 分支的代码,其余是开发分支。
- 现支持源数据库Oracle、Mysql,其余数据库各位自己研究吧,SpringBoot的项目,易拓展
- 返回值使用同样的JSON结构,RestFul开发风格,
友情链接:
1.2 下载地址:
前端代码(旧版无词云):前端代码下载
后端代码:后端代码下载
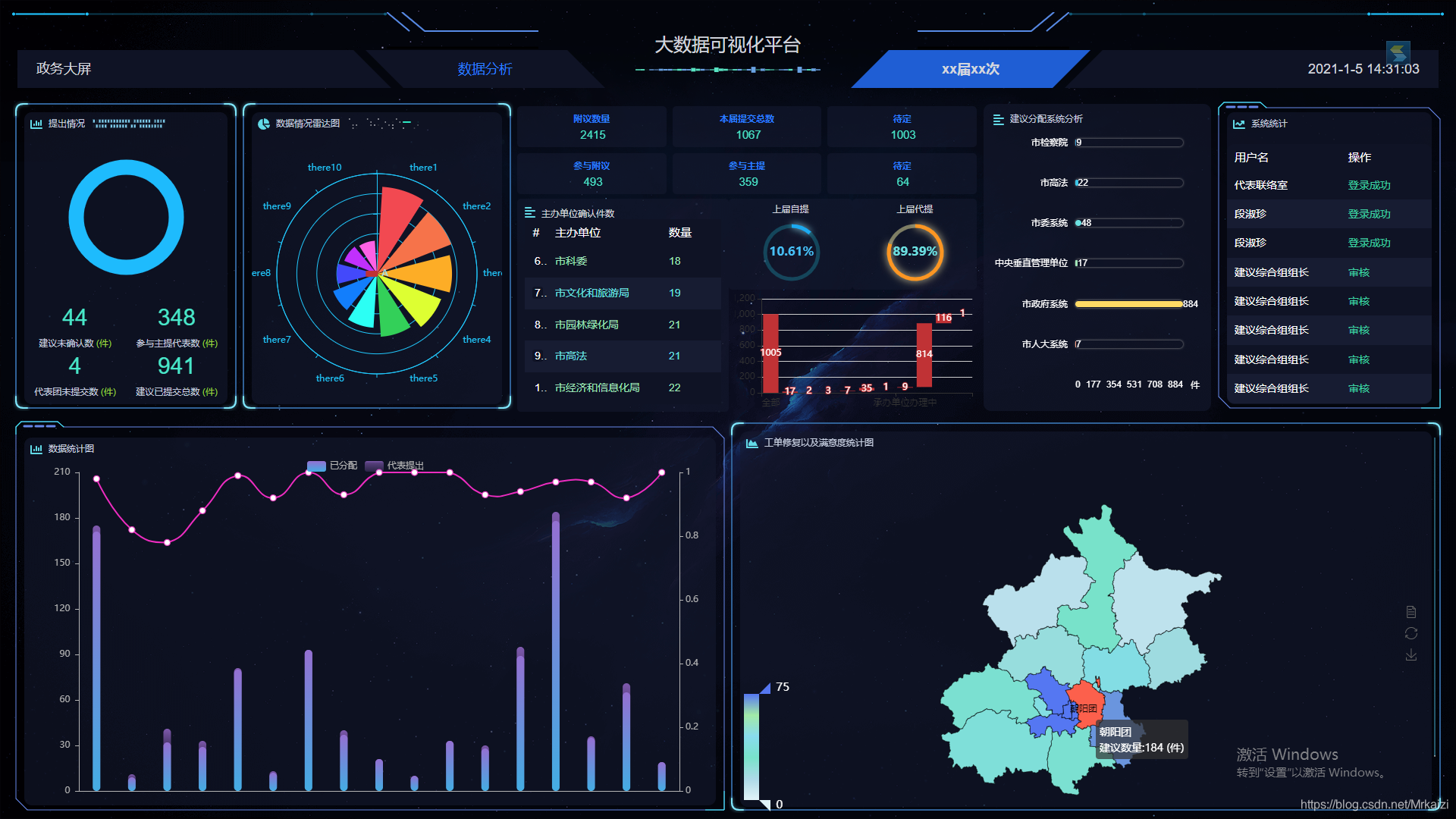
新版:
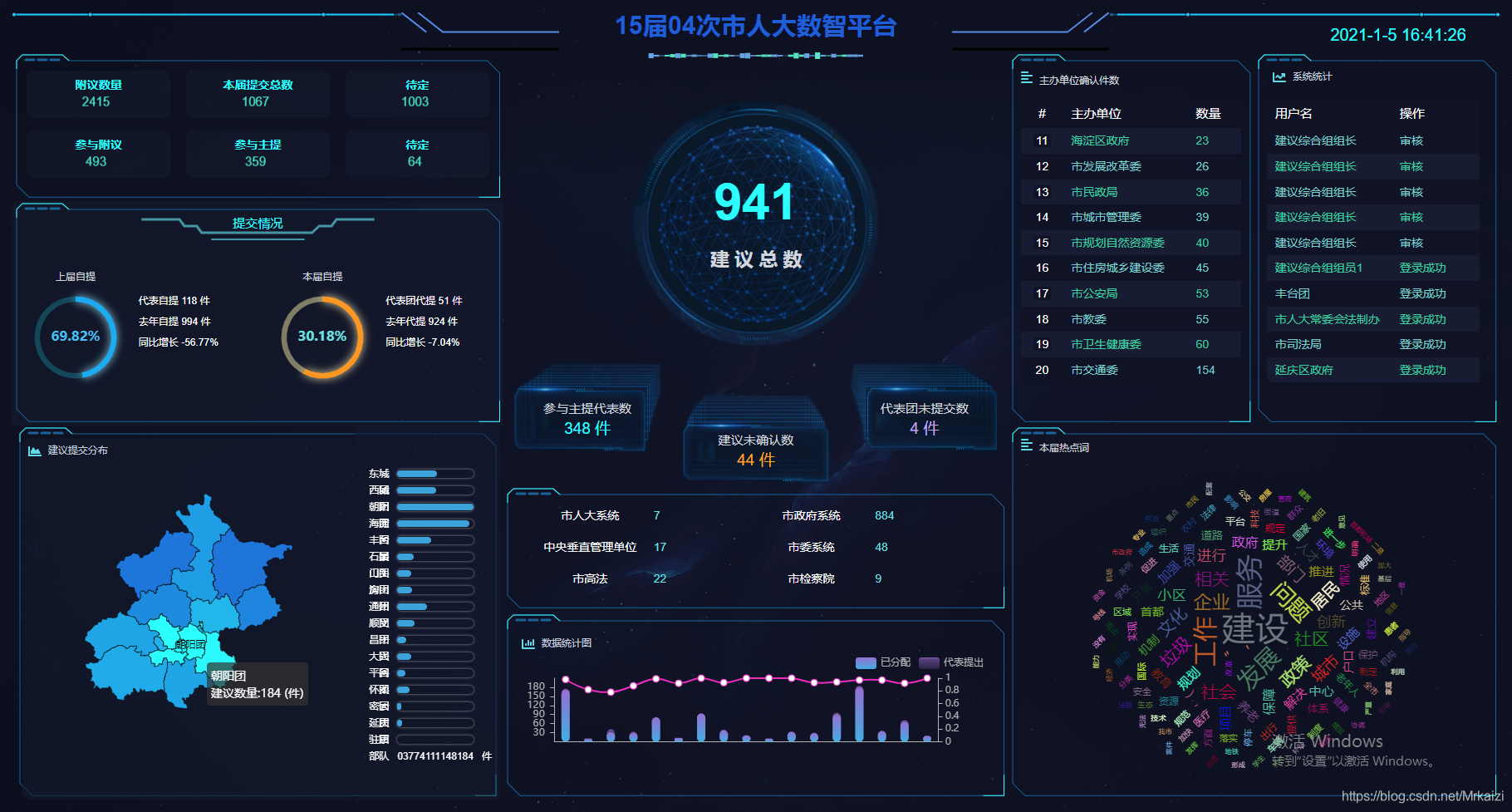
旧版:
1.2 主要文件介绍
项目基于Maven管理依赖,分层清晰,mapper、pojo、service、common服务于api、jieba
业务代码基本都在api中
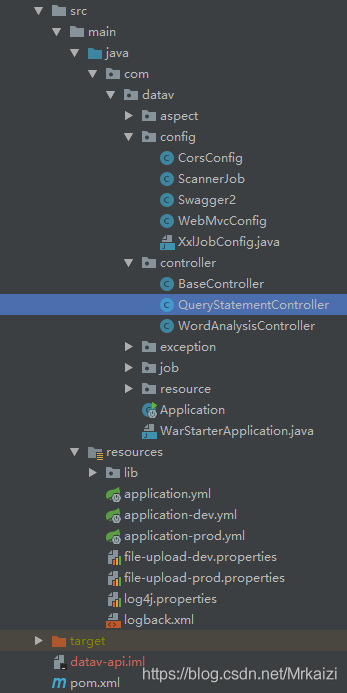
- CorsConfig配置跨域访问,上线后在此配置跨域
- ScannerJob(核心)定时器每隔固定间隔,将query_statement表中所有查询语句取出执行,执行结果存到Redis中
- QueryStatementController 提供获取数据接口,优先从Redis获取,获取不到去query_statement表查,查到后执行sql,并将数据存至Redis
1.3 使用介绍
管理统计SQL
一般情况下,一个前端图,对应一组统计数据(通常是一个sql)。我们动态的将这些SQL存到query_statement表中,表结构如下。
| name | statement | description |
|---|---|---|
| LOGIN_LOG | select ‘xxx’ as X0, count(*) as COUNT from xxx order by xxx | 对应左下折线图 |
| SUBMIT_SUM | select * from datav_log limit 50 | 对应右上轮播日志 |
- name是统计数据名称(唯一),与前端约定好哪个图对应哪个SQL
- statement是统计用的SQL本体,一个SQL对应前端一个图表控件(折线图、饼图)
- description 描述信息
定期执行,保存结果
整理好SQL后,最后由定时器com.datav.config.ScannerJob定期查询到所有统计SQL,执行后存入Redis
/**
* 设置定时器10min刷新数据
*/
@Scheduled(cron = "* 0/10 * * * ?")
public void autoRefreshRedisData(){
// 取出所有统计sql
List<QueryStatement> queryStatementList = queryStatementService.getList();
// 全部执行后放进Redis
queryStatementList.stream().forEach(queryStatement -> {
List<Map<String, Object>> dataList = queryStatementService.findDataByQuery(queryStatement);
String jsonStr = JsonUtils.objectToJson(dataList);
redisOperator.set(QUERY_NAME + ":" + queryStatement.getName(), jsonStr);
});
// 打印执行时长
System.out.println(DateUtil.getCurrentDateString(DateUtil.DATETIME_PATTERN));
}
提供接口,查询数据
@RestController
public class QueryStatementController {
@Autowired
private QueryStatementService queryStatementService;
@Autowired
private RedisOperator redisOperator;
public static String QUERY_NAME = "QUERY_NAME";
@GetMapping("/getDataByName")
public Object getDataByName(String name) {
// 在Redis取数据
String jsonStr = redisOperator.get(QUERY_NAME + ":" + name);
// 取不到,到数据库找SQL,执行后存入Redis
if (StringUtils.isBlank(jsonStr)) {
List<Map<String, Object>> dataList = queryStatementService.findDataBySql(name);
jsonStr = JsonUtils.objectToJson(dataList);
redisOperator.set(QUERY_NAME + ":" + name, jsonStr);
}
return JSONResult.ok(jsonStr);
}
}
-
如何启动项目
Maven项目,拉下代码,idea打开,mvn install
配置数据库,执行oracle.sql创建表
根据业务定制query_statement中统计的SQL语句
配置数据库连接,启动项目 -
如何请求数据
http://localhost:8088/getDataByName?name=SUBMIT_SUM
这里传的name就是你query_statement表的name,唯一字段哦
-
如设置何跨域
com.datav.config.CorsConfig修改这个配置类就好,都是现成的 -
如何使用词云
词云使用Jieba切词,原理是将你要分析的数据,整合为一个String,调用切词工具
WordAnalysisController有具体的例子可以参考
// 分析词云数据
@GetMapping("/analysisProposalContent")
public Object analysisProposalContent() {
// 将源数据取出,一堆blob
String jsonStr = new String();
List<byte[]> contentList = queryStatementService.selectProposalContent();
List<Map<String, Object>> analysisResult = analysis(contentList);
jsonStr = JsonUtils.objectToJson(analysisResult);
redisOperator.set(QUERY_NAME + ":" + name, jsonStr);
return JSONResult.ok(jsonStr);
}
public List<Map<String, Object>> analysis(List<byte[]> contentList) {
ArrayList<Map<String, Object>> result = new ArrayList<Map<String, Object>>();
// 整合为一个String
StringBuilder content = new StringBuilder();
contentList.stream().forEach(blob -> {
try {
content.append(new String(blob,"utf-8"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
});
// 设置最后保留多少个词
int topN = 300;
TFIDFAnalyzer tfidfAnalyzer = new TFIDFAnalyzer();
String contentStr = content.toString();
contentStr = contentStr.replaceAll("\r|\n|。|《|》| |%", "");
// 调用Jieba
List<Keyword> list = tfidfAnalyzer.analyze(contentStr, topN);
for (Keyword word : list) {
System.out.print(word.getName() + ":" + word.getTfidfvalue() + ",");
HashMap<String, Object> tempMap = new HashMap<>();
tempMap.put(word.getName(),word.getTfidfvalue());
result.add(tempMap);
}
return result;
}
四、更新情况
- 执行SQL部分,现在为串行,将改为多线程并发进行
- 切词多线程优化
- 加入xxl-job,一个图建立一个定时任务,分开管理,设置不同的定时器,因为每个图数据更新时间不一致,进行动态的管理定时任务,研发中。。。
五、其余
前端框架是基于项目 gitee 地址(国内速度快)开发,吃水不忘挖井人!感谢大佬无私奉献~
配套前端代码,详情见链接数据大屏项目Vue+DataV+Echarts(附源码)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)