【深入浅出flink】第6篇:详解flink中Text Sink、Csv Sink、Socket Sink、Kafka Sink、Redis Sink、ES Sink,以及万能的UDF Sink
Sink 用来消费 DataStream数据的。Flink提供了很多预置的Sink方法,比如Text Sink、Csv Sink、Socket Sink、Kafka Sink、Redis Sink、ES Sink。当现有的Sink不能满足需求时,用户也可以实现自定义sink,用来解决复杂需求。
大家好,我是雷恩Layne,这是《深入浅出flink》系列的第六篇文章,我旨在用最直白的语言写好flink,希望能让所有看到的人一目了然。如果大家喜欢,欢迎点赞、关注,也欢迎留言,共同交流flink的点点滴滴 O(∩_∩)O
文章目录
DataStream是Flink的较低级API,用于进行数据的实时处理任务,可以将该编程模型分为Source、Transformation、Sink三个部分,如下图所示:
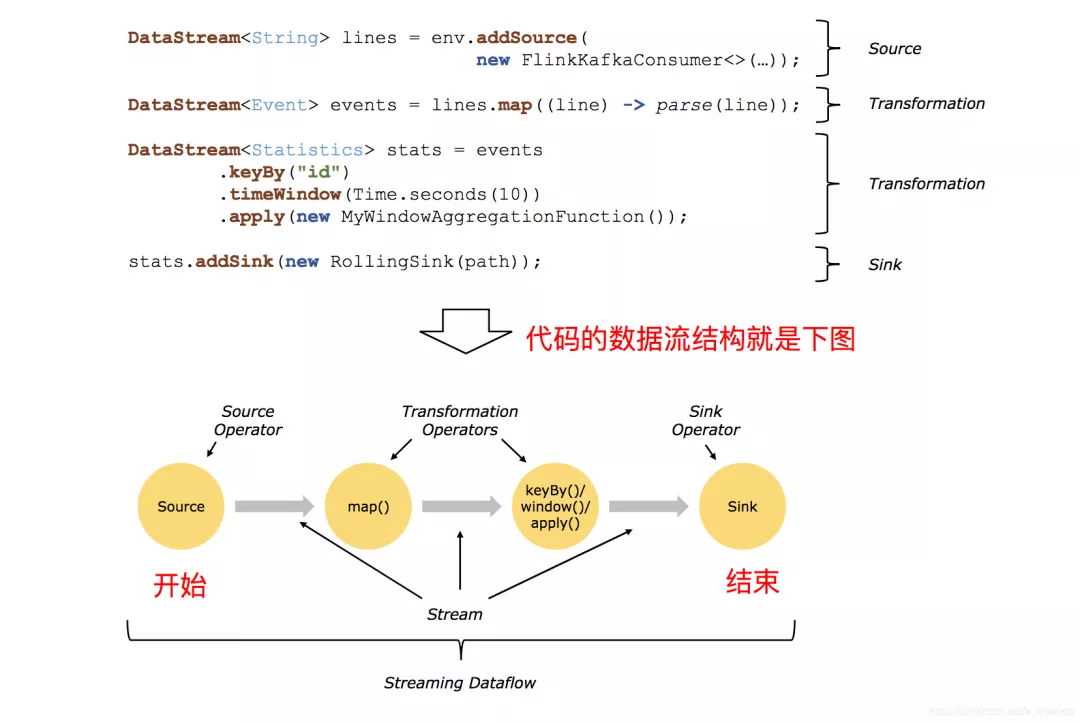
之前的文章讲解编程模型和Source和Transformation部分:
- 【深入浅出flink】第4篇:flink常见的并行度和多并行度Source,你掌握了多少?
- 【深入浅出flink】第5篇:详细梳理flink中常见的dataSteam算子,transformation操作全靠它们
本文来介绍常用的Flink Sink。
1. Sink简介
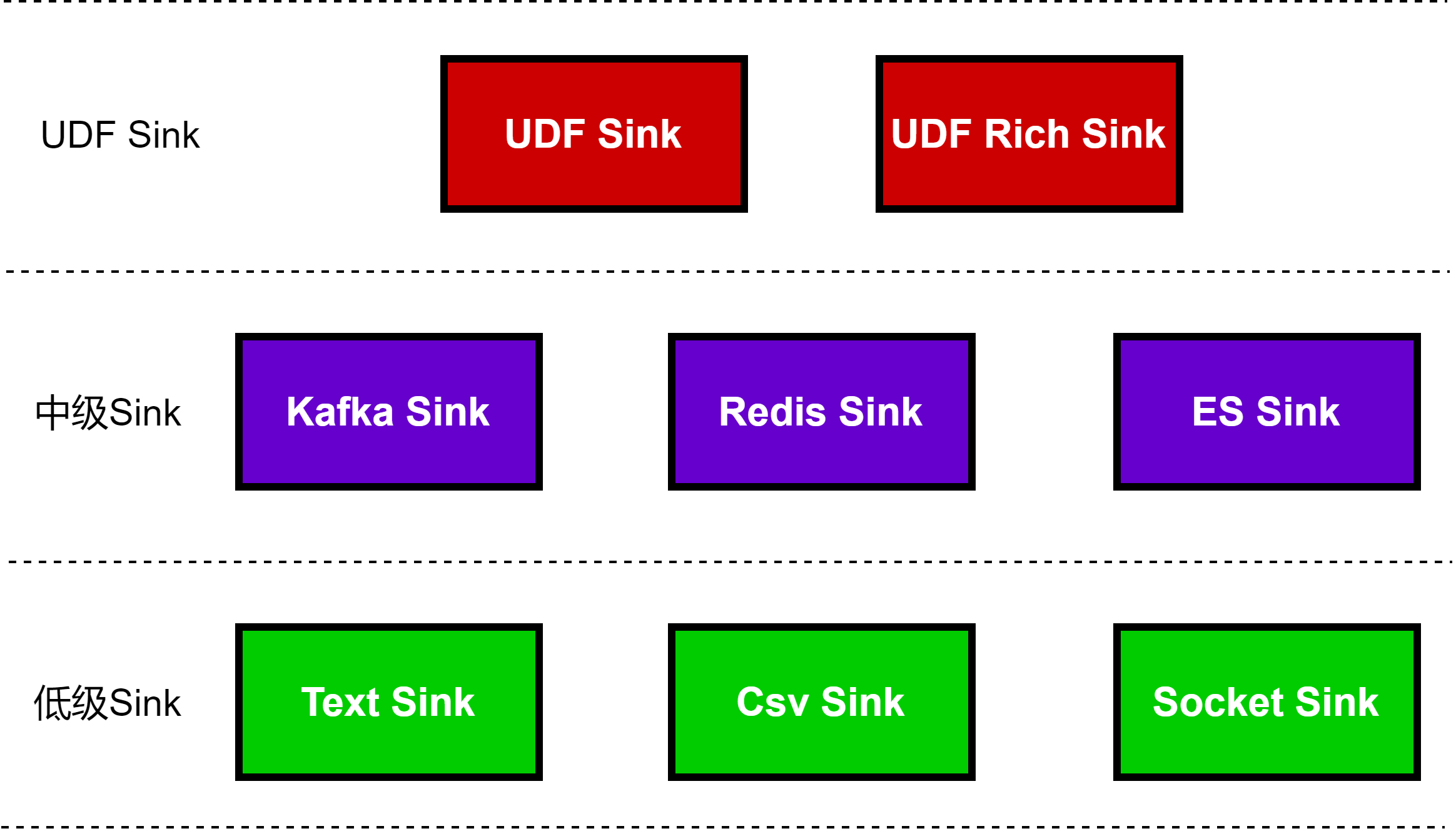
Sink 用来消费 DataStream 并转发到文件,套接字,外部系统或打印到页面。Flink提供了很多预置的Sink方法,封装在 DataStream 算子上,方便我们随时调用,如下图所示。其中,常见的低级Sink和中级Sink(或称写入中间件的Sink)在flink中已经实现好了,我们调用即可。

当现有的Sink不能满足需求时,用户也可以自定义实现sink,实现方法主要有两种:
- 通过实现RichSinkFunction抽象类定义Rich版本的Sink
- 通过实现SinkFunction接口定义一般的Sink
然后,new一个自定义的类对象,通过DataStream的addSink方法将对象传入即可。
2. Flink预定义的Sink
flink提供了大量的已经实现好的Sink,常见的有:
- 基于文件的Sink
- 基于Socket的Sink
- 基于标准输出的Sink
- 基于Kafka的Sink
- 基于Redis的Sink
- 基于Elasticsearch的Sink
- . . .
大部分DataSteam Sink API,我们都可以直接在算子上进行调用,只有少数需要我们new一个对象,传入到DataStream的addSink方法中。
需要说明的是,DataStream中以write *开头的方法主要用于调试目。他们没有参与 Flink checkpoint,这意味着这些函数通常具有至少一次的语义。刷新到目标系统的数据取决于 OutputFormat 的实现,并非所有发送到 OutputFormat 的数据都会立即显示在目标系统中。此外,在失败的情况下,这些记录可能会丢失。要将流可靠、准确地传送到文件系统,请使用 flink-connector-filesystem。通过
.addSink(...)方法的自定义实现,可以实现在 checkpoint 中精确一次的语义。这部分在后面我会单独写成一篇文章。
flink预置的Sink几乎均实现了RichSinkFunction抽象类,以便更好的控制算子的生命周期,如下图所示:

2.1 基于文件的Sink
(1)基于文本文件的Sink
将dataStream数据写入到文本文件有两种方式:
- 调用dataStream的writeAsText方法,传入指定路径
- 调用dataStream的writeUsingOutputFormat方法,传入TextOutputFormat
示例:将dataStream数据写入到文本文件中
DataStream<String> dataStream = env.fromElements("hello","world","flink");
dataStream.writeAsText("data/output/test1.txt");
dataStream.writeUsingOutputFormat(
new TextOutputFormat<String>(new Path("data/output/test2.txt")));
这两个方法本质上是一样的。
(2)基于Csv文件的Sink
基于Csv文件的Sink要求dataStream中的数据必须是元祖类型,将dataStream数据写入到Csv文件有两种方式:
- 调用dataStream的writeAsCsv方法,传入指定路径
- 调用dataStream的writeAsCsv方法,传入指定路径
示例:将dataStream数据写入到csv文件中
DataStream<Tuple2<String,Long>> dataStream = env.fromElements(
new Tuple2<>("hello",1L),
new Tuple2<>("world",3L),
new Tuple2<>("flink",5L));
dataStream.writeAsCsv("data/output/test1.csv");
dataStream.writeUsingOutputFormat(
new CsvOutputFormat(new Path("data/output/test2.csv")));
2.2 基于标准输出的Sink
print() / printToErr():在标准输出/标准错误流上打印每个元素的 toString() 值。可以定义输出前缀,这有助于区分不同的打印调用。如果并行度大于1,输出也包含生成输出的任务的标识符。
示例:将dataStream中的数据打印到标准输出和标准错误上
DataStream<String> dataStream = env.fromElements("hello","world","flink");
dataStream.print("标准输出");
dataStream.printToErr("标准错误");
2.3 基于Socket的Sink
writeToSocket:将元素写入 Socket,使用 SerializationSchema 进行序列化,如果发送字符串,可以自定义成SimpleStringSchema。
示例:将数据发送到远程端口
DataStream<String> dataStream = env.fromElements("hello","world","flink");
dataStream.writeToSocket("localhost",7777,new SimpleStringSchema());
2.4 基于Kafka的Sink
在flink中,要想把dataStream中的数据写入到kafka中非常简单,只需用一行代码就可以搞定。
根据不同的版本,flink给我们提供了三种kafka sink,分别是:
- FlinkKafkaProducer09
- FlinkKafkaProducer010
- FlinkKafkaProducer011
示例:dataStream中的数据写入到kafka
(1)引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
(2)将FlinkKafkaProducer011对象添加到addSink中
DataStream<String> dataStream = env.fromElements("hello","world","flink");
dataStream.addSink(new FlinkKafkaProducer011[String]("localhost:9092", "test", new SimpleStringSchema()))
2.5 基于Redis的Sink
flink给我们提供了写入Redis的Sink,这使得将dataStream中的数据写入到Redis非常简洁。
示例:将dataStream中的数据写入到Redis
(1)引入依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
(2)定义一个redis的mapper类,用于定义保存到redis时调用的命令
public static class MyRedisMapper implements RedisMapper<Tuple2<String,Long>>{
// 保存到redis的命令,存成哈希表
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "wordcount");
}
public String getKeyFromData(Tuple2<String,Long> data) {
return data.f0;
}
public String getValueFromData(Tuple2<String,Long> data) {
return data.f1.toString();
}
}
(3)将MyRedisMapper对象添加到addSink中
DataStream<Tuple2<String,Long>> dataStream = env.fromElements(
new Tuple2<>("hello",1L),
new Tuple2<>("world",3L),
new Tuple2<>("flink",5L));
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("localhost")
.setPort(6379)
.build();
dataStream.addSink( new RedisSink<Tuple2<String,Long>>(config, new MyRedisMapper()) );
2.6 基于Elasticsearch的Sink
flink也给我们提供了写入Elasticsearch的Sink。
示例:将dataStream中的数据写入到Elasticsearch
(1)引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.12</artifactId>
<version>1.10.1</version>
</dependency>
(2)ElasitcsearchSinkFunction的实现
public static class MyEsSinkFunction implements ElasticsearchSinkFunction<Tuple2<String,Long>>{
@Override
public void process(Tuple2<String,Long> element, RuntimeContext ctx, RequestIndexer indexer) {
HashMap<String, String> dataSource = new HashMap<>();
dataSource.put("word",element.f0);
dataSource.put("count",element.f1.toString());
IndexRequest indexRequest = Requests.indexRequest()
.index("wordcount")
.type("readingData")
.source(dataSource);
indexer.add(indexRequest);
}
}
(3)将ElasitcsearchSinkFunction对象添加到addSink中
// es的httpHosts配置
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("localhost", 9200));
dataStream.addSink( new ElasticsearchSink.Builder<Tuple2<String,Long>>(httpHosts, new MyEsSinkFunction()).build());
3. Rich版本的UDF Sink
如果Flink没有预置的Sink,我们可以自定义Sink,自定义Sink方法有两种:
- 通过实现RichSinkFunction抽象类定义Rich版本的Sink
- 通过实现SinkFunction接口定义一般的Sink
这里补充一下富函数(RichFunction)的知识。
富函数(RichFunction)是DataStream API提供的一个函数类的接口,所有Flink函数类都有其Rich版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。比如,我们常见的Map、FlatMap、Filter算子富函数版如下:
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
Rich Function典型的生命周期方法有:
- open()方法是rich function的初始化方法,当一个算子被调用之前open()会被调用。
- close()方法是生命周期中的最后一个调用的方法,做一些清理工作。
- getRuntimeContext()方法提供了函数的RuntimeContext的一些信息,例如函数执行的并行度,任务的名字,以及state状态。
现在,我们通过实现RichSinkFunction定义Rich版本的JDBC Sink。
(1)在mysql中创建wordcount表
DROP TABLE IF EXISTS `wordcount`;
CREATE TABLE `wordcount` (
`word` varchar(25) DEFAULT NULL,
`count` bigint(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(2)引入mysql jdbc依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.24</version>
</dependency>
(3)自定义rich版JDBC Sink,向mysql中插入数据
class MyJDBCSink extends RichSinkFunction<Tuple2<String,Long>> {
//声明连接和预编译语句
Connection connection=null;
PreparedStatement insertStmt=null;
PreparedStatement updateStmt=null;
@Override
public void open(Configuration parameters) throws Exception {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test"
,"root","123456");
insertStmt = connection.prepareStatement("insert into wordcount (word,count) value (?,?)");
updateStmt = connection.prepareStatement("update wordcount set count= ? where word = ?");
}
//每来一条数据,调用连接,执行sql
@Override
public void invoke(Tuple2<String,Long> value, Context context) throws Exception {
//直接执行更新语句,如果没有更新那么就插入
updateStmt.setLong(1,value.f1);
updateStmt.setString(2,value.f0);
updateStmt.execute();
if(updateStmt.getUpdateCount()==0){
insertStmt.setString(1,value.f0);
insertStmt.setDouble(2,value.f1);
insertStmt.execute();
}
}
@Override
public void close() throws Exception {
insertStmt.close();
updateStmt.close();
connection.close();
}
}
(4)将MyJDBCSink对象添加到addSink中
DataStream<Tuple2<String,Long>> dataStream = env.fromElements(
new Tuple2<>("hello",1L),
new Tuple2<>("world",3L),
new Tuple2<>("flink",5L),
new Tuple2<>("world",99L));
dataStream.addSink(new MyJDBCSink());
可以看到,继承RichSinkFunction抽象类,我们可以通过实现其open、close等方法,控制算子的声明周期,从而在算子被调用之前,连接Mysql并初始化预编译语句,算子执行过程中只进行插入和更新操作,执行完成后释放连接。这样就能做到整个操作过程只与Mysql连接一次,加快了执行效率。
4. 一般的UDF Sink
通过实现SinkFunction接口定义一般的Sink:
(1)实现SinkFunction,向mysql中插入数据
class MyJDBCSink implements SinkFunction<Tuple2<String, Long>> {
@Override
public void invoke(Tuple2<String, Long> value) throws Exception {
//声明连接和预编译语句
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test"
, "root", "123456");
PreparedStatement insertStmt = connection.prepareStatement("insert into wordcount (word,count) value (?,?)");
PreparedStatement updateStmt = connection.prepareStatement("update wordcount set count= ? where word = ?");
//直接执行更新语句,如果没有更新那么就插入
updateStmt.setLong(1,value.f1);
updateStmt.setString(2,value.f0);
updateStmt.execute();
if(updateStmt.getUpdateCount()==0){
insertStmt.setString(1,value.f0);
insertStmt.setDouble(2,value.f1);
insertStmt.execute();
}
insertStmt.close();
updateStmt.close();
connection.close();
}
}
(2)将MyJDBCSink对象添加到addSink中
DataStream<Tuple2<String, Long>> dataStream = env.fromElements(
new Tuple2<>("hello", 1L),
new Tuple2<>("world", 3L),
new Tuple2<>("flink", 5L),
new Tuple2<>("world", 99L));
dataStream.addSink(new MyJDBCSink());
可以看到这种方式虽然简单,但是每来一个数据,就要连接mysql和释放连接,加重了资源的消耗,与rich版JDBC Sink相比,效率低很多。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)