windows下 利用ELK做日志收集
ELK:ElasticSearch + LogStash + KibanaES中文社区:ElasticSearch中文社区下载应用场景:Logback + ELK日志收集环境:Windows10参考文章:ELK+logback:日志存储及可视化_夜太黑-CSDN博客https://blog.csdn.net/longchao2/article/details/80136872环境搭建:(三者都可以
ELK:ElasticSearch + LogStash + Kibana
ES中文社区:ElasticSearch中文社区下载
应用场景:Logback + ELK日志收集
环境:Windows10
参考文章:ELK+logback:日志存储及可视化_夜太黑-CSDN博客![]() https://blog.csdn.net/longchao2/article/details/80136872
https://blog.csdn.net/longchao2/article/details/80136872
环境搭建:(三者都可以直接下载压缩包解压后即可使用)
ElasticSearch安装:地址参见【ES中文社区】
ES中需要添加IK分词器插件,在ES中文社区中的Plugins中可以下载


找到对应的版本(我用的版本是7.6.1),下载解压,在ES的plugin目录下创建ik文件夹,将分词器插件复制 过去即可
过去即可
进入bin 目录 双击 elasticsearch.bat启动即可
LogStash安装:地址参见【ES中文社区】
下载解压后,在bin 目录下创建配置文件供logstash启动时加载,如logstash.conf。input有多种配置,如tcp、file等,filter也有gork、csv等,output除了es也有别的输出目的地。
//输入配置
input {
tcp {
host => "127.0.0.1"//安装logstash的机器的ip地址
port => 9250//端口号
mode => "server"
codec => "json"//按json格式编码
}
}
//过滤配置
filter {
csv{
source => "message"
columns => ["column a","column b"] //从message中取出字段名
remove_field => ["column c","column b"] //去除不需要的字段名
}
}
//输出配置
output {
stdout{codec =>rubydebug}
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "syslog-%{[appname]}" //es中创建索引的名称
flush_size => 1000 //刷新频率
}
}
## 示例:对上面的配置,若输入日志为123,234,456,logstash以逗号为分隔符,自动分割日志为value值,输出为,column a:123,column b:234
## net.logstash.logback 这个框架默认输出日志是json 所以一定要有codec => "json" 这个配置
## index => "%{[appname]}" 这个配置就是获取日志中的 appname字段的值做为索引的名称
指定配置文件启动logstash,logstash -f logstash.conf

如图,Starting tcp input listener {:address=>"127.0.0.1:9250", :ssl_enable=>"false"} 指定TCP方式传输监听配置,也就是在logstash.conf中的输入配置。
Kibana安装:地址参见【ES中文社区】
默认是英文版,在kibana.yml中设置中文显示
# 本机的端口
server.port: 5601
# 本机IP地址
server.host: "127.0.0.1"
# ES的服务IP+端口
elasticsearch.hosts: ["http://localhost:9200"]
# 设置为中文
i18n.locale: "zh-CN"Logback配置
参考文章:logback将日志传输到 logstash![]() https://blog.csdn.net/qq1010267837/article/details/90730474 输出json乱码
https://blog.csdn.net/qq1010267837/article/details/90730474 输出json乱码![]() https://blog.csdn.net/wang0120000/article/details/105097417/
https://blog.csdn.net/wang0120000/article/details/105097417/
使用logback将应用里的日志输出到logstash,输出到logstash中的日志必须是指定格式的特定日志信息,所以,需要过滤和格式化。
引入依赖
<dependency>
<groupId>net.logstash.log4j</groupId>
<artifactId>jsonevent-layout</artifactId>
<version>1.6</version>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.11</version>
</dependency>logback.xml 文件配置(添加appender)
<appender name="stash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!-- 安装logstash机器的ip地址,这里我们使用的TCP方式,所以直接配置TCP输入配置的监听 -->
<destination>127.0.0.1:9250</destination>
<!-- 引入过滤类 -->
<!-- <filter class="com.program.interceptor.ELKFilter"/>-->
<!-- encoder必须配置,有多种可选 -->
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder">
<customFields>{"appname":"elk-demo"}</customFields>
</encoder>
<!-- <destination>destination1.domain.com:4560</destination>
<destination>destination2.domain.com:4560</destination>
<destination>destination3.domain.com:4560</destination> -->
<!-- <connectionStrategy>
<roundRobin>
<connectionTTL>5 minutes</connectionTTL>
</roundRobin>
</connectionStrategy> -->
<!-- 向logstash输出日志如果有多个logstash IP或端口可以轮询负载各端口 -->
</appender>自定义日志级别
通常情况下我们是在root级别加上新的appender,在root上控制日志级别。但是现在有一个场景就是我们希望能够新加的appender的日志级别能够不与其他地方交叉,也就是能够支持自定义。
<logger name="BUSINESSLOG" level="DEBUG" additivity="false">
<appender-ref ref="CUSTOMLOG"/>
</logger>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="DEBUG" />
<appender-ref ref="INFO" />
<appender-ref ref="WARN" />
<appender-ref ref="ERROR" />
</root>在logback中的logger标签能够定义不同的日志打印级别,logger中的level指定自身appender日志打印级别,若不指定,默认root对应的level配置。
过滤类编写
public class ELKFilter extends Filter<ILoggingEvent> {
@Override
public FilterReply decide(ILoggingEvent event) {
if (event.getMessage().startsWith("KeyWords")) {//只有以"KeyWords"开头的日志被输出到logstash
return FilterReply.ACCEPT;
} else {
return FilterReply.DENY;
}
}
}自定义索引名称
logstash传输到ElasticSearch默认会创建logstash-*的索引名字,但是这个不符合业务要求,真实的场景中,不可能将所有的日志全部放在一块,我们的目的就是为了追踪日志的便利性,这样的话没有意义,所以我们需要去自定义索引的名字。

之前添加的appender中出现的customeFields标签即可实现此点,appname为自定义的字段,elk-demo为字段值,那么这个配置有什么用呢,且往下看。
 logstash的输出配置中有这么一段,会发现在ES的配置中有index一项,index即为可配置索引的名称,appname即为customeFields标签中配置的字段名字。
logstash的输出配置中有这么一段,会发现在ES的配置中有index一项,index即为可配置索引的名称,appname即为customeFields标签中配置的字段名字。
接下来我们来做一个试验
测试demo
1. 启动ELK。
2. 创建简单的Springboot项目,定义DemoController,指向logback中自定义的"BUSINESSLOG",BUSINESSLOG即为自定义日志级别的name,定义了四种日志的打印(trace、debug、info、error)来验证自定义日志级别。

3. localhost:5601进入Kibana管理界面查看当前索引列表,目前只有一个默认的 ilm-history-1-000001。

4. 启动项目,调用定义的api

5. 回到Kibana的索引管理会发现一下新创建的索引

看到存储大小为17.3kb,接下来我们去看一下ES中的数据到底是不是我们打印的日志呢
6. Kibana—索引模式—创建索引模式

索引模式:输入刚刚生成的索引名字,成功匹配1个索引,然后下一步

配置设置:选择@timestamp ,创建索引模式

7. 查看索引

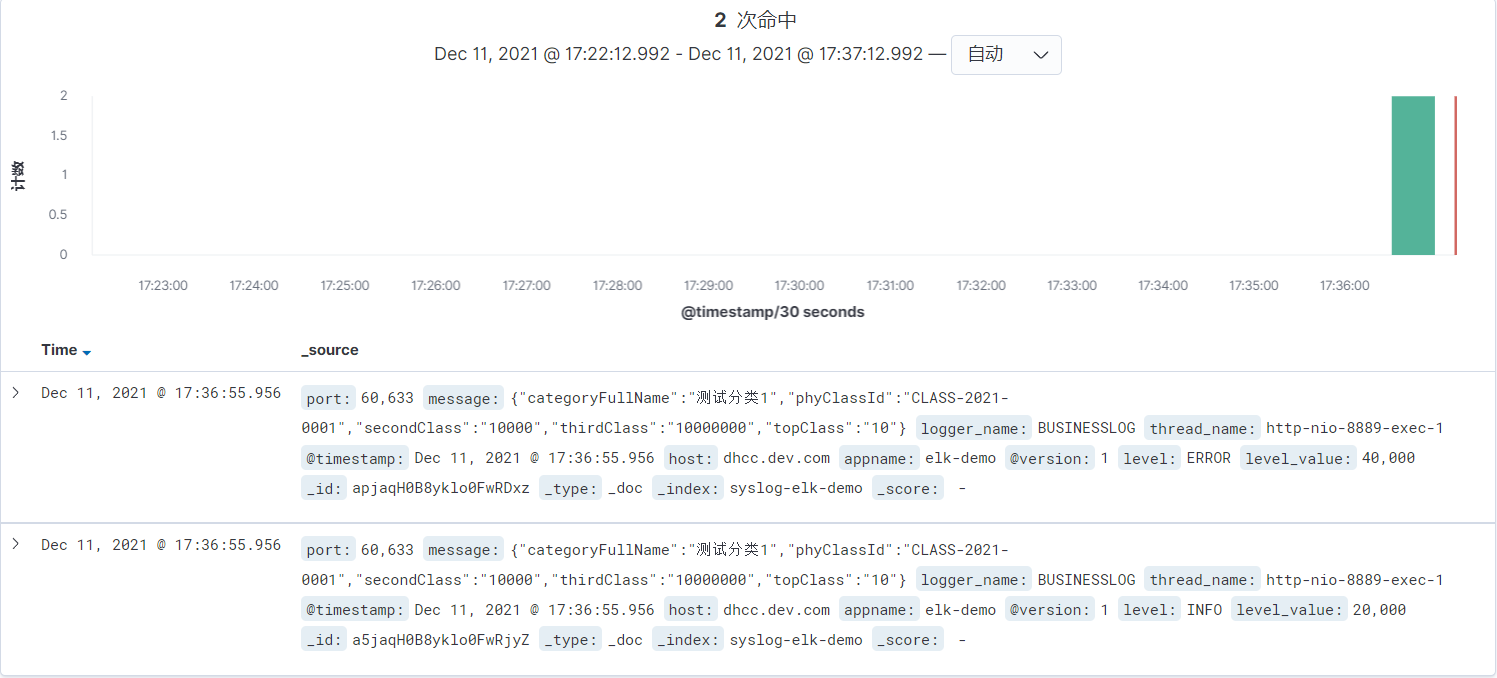
可以看到有3次命中,再看我们在DemoController中定义了四种级别的日志,在logback中我们自定义的 BUSINESS 日志级别控制在 DEBUG ,而 ROOT 控制在 INFO 级别,可见我自定义的日志级别并没有收到ROOT的限制。


8. 删除索引,删除logback中BUSINESS的级别level配置



9. 重启项目,再次POSTMAN调用API

再次查看索引内容,2次命中,level分别为ERROR、INFO,由此可见此时的级别控制默认为ROOT的配置。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)