Logstash实战从kafka解析业务日志并保存到ElasticSearch
准备kafka、logstash 、es 环境并启动服务,参考之前的文章这里不重复启动zookeeper:启动kafka:假设日志格式如下,包括基本字段(时间、IP、级别等)和业务字段(字段1,字段2,字段3)。消费消息并打印配置文件如下,从kafka获取日志并直接打印:启动logstash向kakfa发送消息后,logstash接收并打印了消息。消息输出到ES启动ES修改配置文件.output
环境准备
准备kafka、logstash 、es 环境并启动服务,参考之前的文章这里不重复
日志读取及保存
启动zookeeper:[root@localhost kafka]# bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
启动kafka:[root@localhost kafka]# bin/kafka-server-start.sh -daemon config/server.properties
假设日志格式如下,包括基本字段(时间、IP、级别等)和业务字段(字段1,字段2,字段3)。
2021-05-21 15:28:50.093 192.168.8.96 1 error 4 [#字段1#][#字段2#][#字段3#]
消费消息并打印
配置文件如下,从kafka获取日志并直接打印:
input {
kafka {
bootstrap_servers => "192.168.195.11:9092"
topics => ["guardlog"]
group_id => "GuardLogGroup"
client_id => "guard_cli"
security_protocol => "SSL"
}
}
filter {
}
output {
stdout { } # 控制台输出
}
启动logstash
[root@localhost logstash]# bin/logstash -f config/logstash.conf --config.reload.automatic
向kakfa发送消息后,logstash接收并打印了消息。
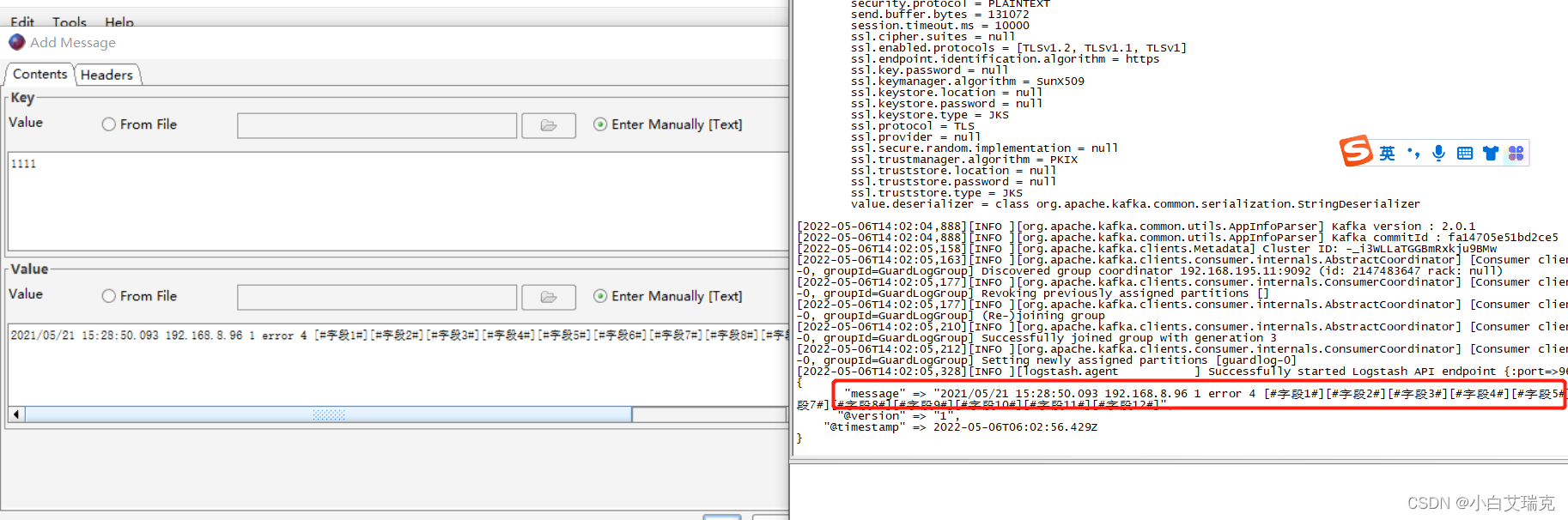
消息输出到ES
启动ES[es@localhost es7.12]$ bin/elasticsearch -d
修改配置文件.output 增加 es输出如下:
output {
stdout { } # 控制台输出
elasticsearch {
hosts => ["192.168.195.12:9200"]
index => "guardlog"
}
}
插入kafka消息控制台有输出
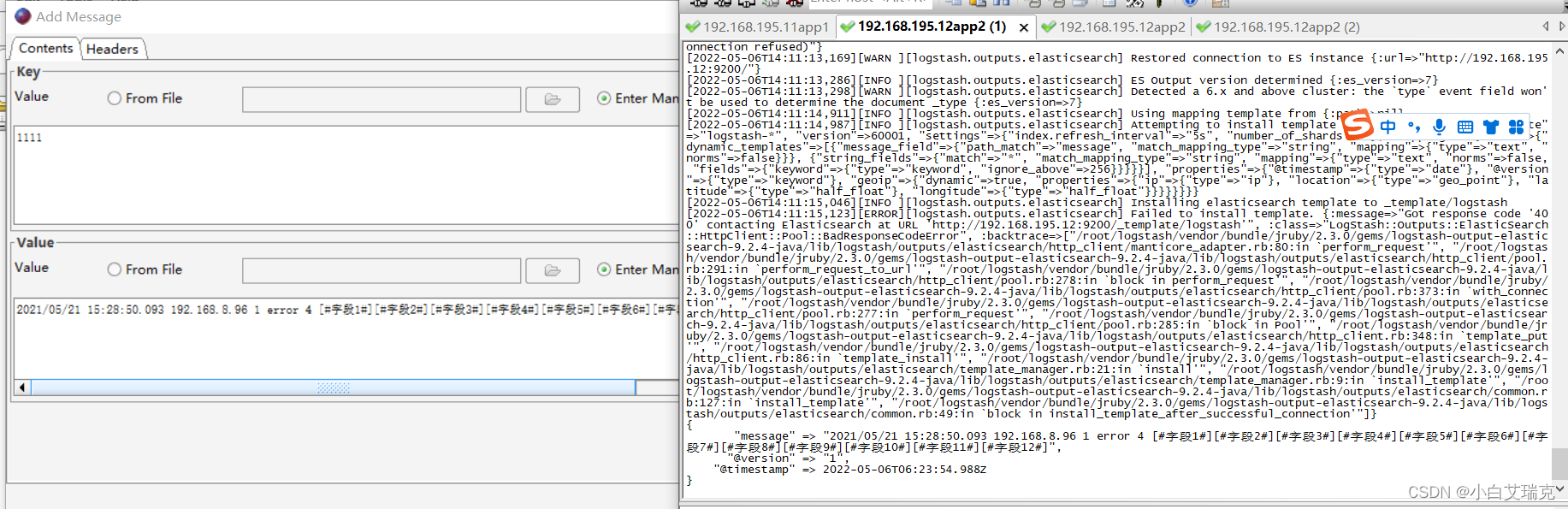
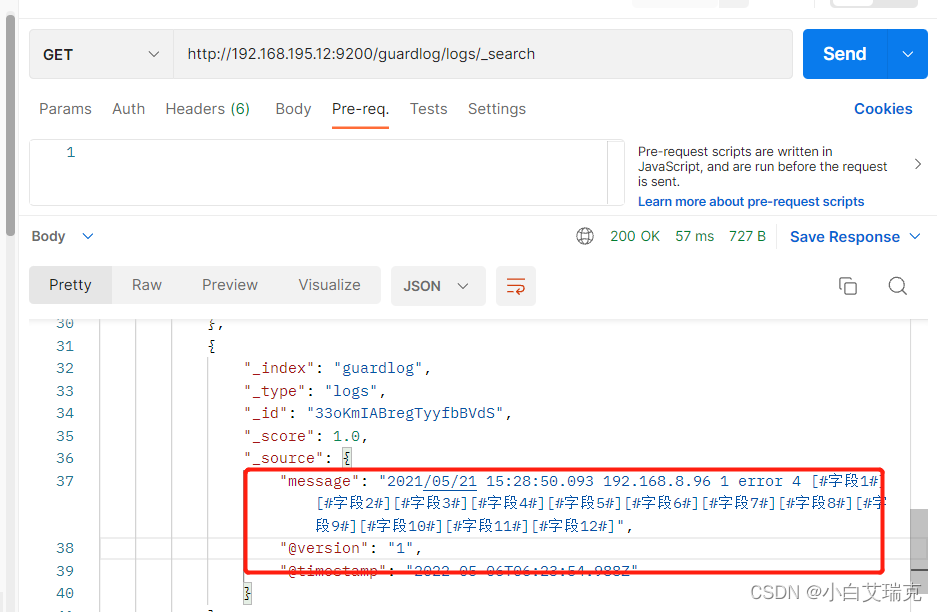
es中也有了这条消息,postman查询结果如下
日志解析
上边我们从kafka读取日志并保存到了es 中但是可以看到,日志格式是一段文本,很多时候我们需要结构化的数据方便数据查询过滤等,因此我们在将日志保存到es前要对日志做解析和转换。
logstash提供了很多插件可以用来解析日志,对于常见的apache 等日志有现成的解析插件,这里我们使用grok插件来解析基本日志格式内容,并通过正则表达式和字符串分割解析出业务字段。
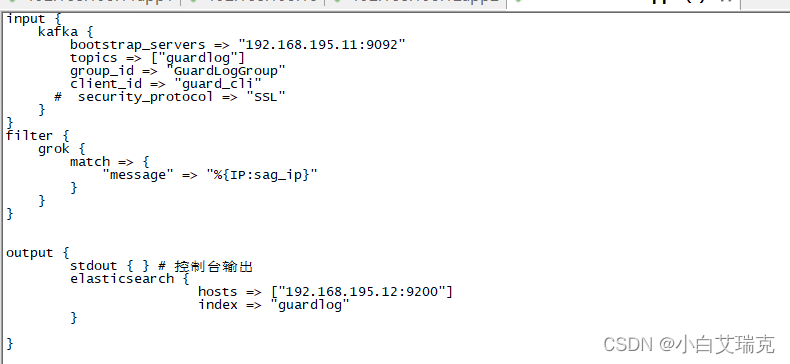
可以直接调用grok内置的正则格式,来解析日志内容,如下:通过IP 来解析日志中的请求者IP":%{IP:sag_ip}"
默认提供的格式见:patterns
groke基于正则表达式库是Oniguruma,你可以在Oniguruma网站上看到完整支持的regexp语法。
中文学习正则表达式网站:http://www.runoob.com/regexp/regexp-tutorial.html
调试工具:调试
观察输出内容可以看到,当日志内容中有ip时会解析出来并在日志中增加一个字段sag_ip 来保存这个值,但是如果日志中没有找到IP那么就会增加tags字段,提示groke解析失败。测试发现如果有一个表达式没有匹配到内容那么就是报错(提示解析失败)其他字段也无法正确解析。实际中可以通过是否存在tags字段来判断是否处理成功,如果未处理成功那么可以将数据单独保存到一个地方方便分析
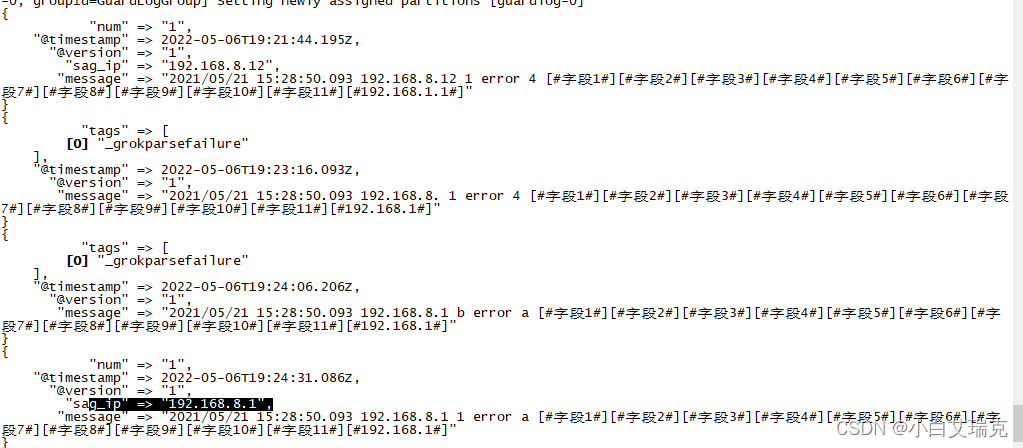
如下,我们使用 grok自带的表达式来解析时间、IP、tag、loglevel等内容,最后一个字段是使用我们自定义的正则表达式(\[#?)(?<source>.*(?=#\]$))来解析出 [##]中的全部内容,并保存到source字段
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:op_date} \s*%{IP:sag_ip} \s*%{DATA:sag_tag} \s*%{LOGLEVEL:log_level} \s*%{DATA:log_src} \s*(\[#?)(?<source>.*(?=#\]$))"
}
}
}
输入测试数据可以看到 ,数据被正常解析
{
"sag_tag" => "1",
"@version" => "1",
"message" => "2021-05-21 15:28:50.093 192.168.8.96 1 error 4 [#字段1#][#字段2#][#字段3#]",
"sag_ip" => "192.168.8.96",
"log_level" => "error",
"op_date" => "2021-05-21 15:28:50.093",
"log_src" => "4",
"@timestamp" => 2022-05-08T03:33:16.271Z,
"source" => "字段1#][#字段2#][#字段3"
}
可以在souce字段的基础上根据#][# 进行字段分割就可以得到 所有的业务字段,如下使用ruby来完成这个功能
filter {
grok {
pattern_definitions =>{
# MYNUM => "\d+",
FIELD => "(?:\[#).*(?:#\])"
SAGTAG => "\w+"
}
#patterns_dir =>["/root/logstash/patterns"]
match => {
"message" => "%{TIMESTAMP_ISO8601:op_date} \s*%{IP:sag_ip} \s*%{DATA:sag_tag} \s*%{LOGLEVEL:log_level} \s*%{DATA:log_src} \s*(\[#?)(?<source>.*(?=#\]$))"
}
}
ruby{
code =>"
ipStr = event.get('source')
ipArray = ipStr.split('#][#',-1)
length = ipArray.length
path = ''
if length != 3
event.set('tags','mainMsgLengthError')
else
event.set('f1',ipArray[0])
event.set('f2',ipArray[1])
event.set('f3',ipArray[2])
end
"
}
}
再次测试可以发现业务字段已经都完成了解析
[2022-05-08T11:48:23,133][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator] [Consumer clientId=guard_cli-0, groupId=GuardLogGroup] Setting newly assigned partitions [guardlog-0]
{
"sag_tag" => "1",
"@version" => "1",
"f2" => "字段2",
"op_date" => "2021-05-21 15:28:50.093",
"source" => "字段1#][#字段2#][#字段3",
"f3" => "字段3",
"message" => "2021-05-21 15:28:50.093 192.168.8.96 1 error 4 [#字段1#][#字段2#][#字段3#]",
"sag_ip" => "192.168.8.96",
"log_level" => "error",
"log_src" => "4",
"@timestamp" => 2022-05-08T03:48:40.473Z,
"f1" => "字段1"
}
最后删除不必要的字段,同时增加输出判断 如果包含tags字段则输出到异常数据索引
filter {
grok {
pattern_definitions =>{
# MYNUM => "\d+",
FIELD => "(?:\[#).*(?:#\])"
SAGTAG => "\w+"
}
#patterns_dir =>["/root/logstash/patterns"]
match => {
"message" => "%{TIMESTAMP_ISO8601:op_date} \s*%{IP:sag_ip} \s*%{DATA:sag_tag} \s*%{LOGLEVEL:log_level} \s*%{DATA:log_src} \s*(\[#?)(?<source>.*(?=#\]$))"
}
}
ruby{
code =>"
ipStr = event.get('source')
elasticsearch {
hosts => ["192.168.195.12:9200"]
index => "guardlog"
}
ipArray = ipStr.split('#][#',-1)
length = ipArray.length
path = ''
if length != 3
event.set('tags','mainMsgLengthError')
else
event.set('f1',ipArray[0])
event.set('f2',ipArray[1])
event.set('f3',ipArray[2])
end
"
}
if [tags] {
#如果出错了,不删除内容直接保存到
} else {
#如果没有出错择删除不必要的字段 并保存到es
mutate {remove_field => ["source","message","@timestamp","@version"]}
}
}
output {
stdout { } # 控制台输出
if [tags] {
elasticsearch {
hosts => ["192.168.195.12:9200"]
index => "guarderrlog"
}
} else {
elasticsearch {
hosts => ["192.168.195.12:9200"]
index => "guardlog"
}
}
}
再次测试,没有了多余的字段,同时一旦解析出错就会保存到guarderrlog索引中
[2022-05-08T11:55:47,875][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator] [Consumer clientId=guard_cli-0, groupId=GuardLogGroup] Setting newly assigned partitions [guardlog-0]
{
"sag_tag" => "1",
"f2" => "字段2",
"op_date" => "2021-05-21 15:28:50.093",
"f3" => "字段3",
"sag_ip" => "192.168.8.96",
"log_level" => "error",
"log_src" => "4",
"f1" => "字段1"
}
grok调试工具
上述过程中我们每次都通过运行logstash来验证我们解析的正确性,很繁琐,实际中我们有必要搞一套grok测试工具。以方便对解析过程的测试。网络上的工具有时候不稳定,可以在本地启动调试服务。
docker环境下运行一下命令就可以运行本地的测试服务,
[root@localhost ~]# docker pull qiudev/grokdebugger
[root@localhost ~]# docker run -d --name grokdebugger -p 19999:9999
启动后我们访问 http://192.168.195.10:19999/ 就可以使用本地调试服务
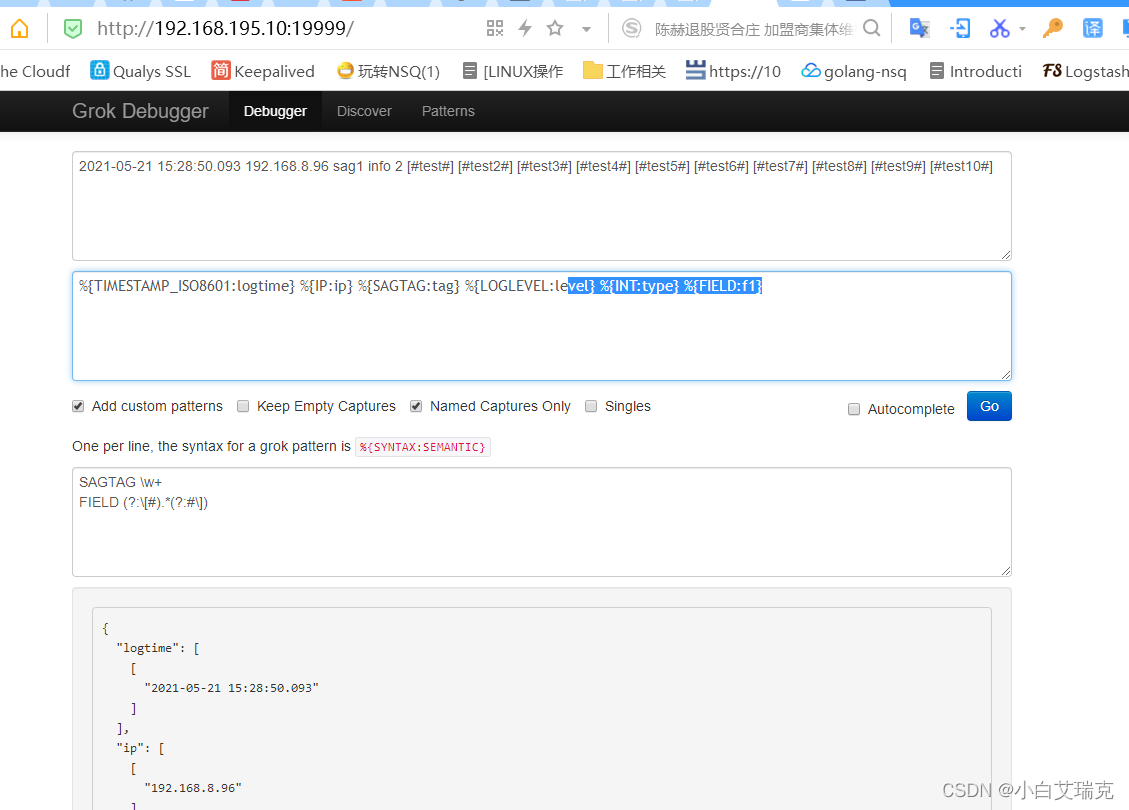
grok自定义格式
如果grok自带的表达式不能满足需求,还可以自定义表达式,在logstash 中自定义表达式有多种方式
通过pattern_definitions 属性来定义
grok {
pattern_definitions =>{
# MYNUM => "\d+",
FIELD => "(?:\[#).*(?:#\])"
SAGTAG => "\w+"
}
match => {
"message" => "%{TIMESTAMP_ISO8601:op_date} \s*%{IP:sag_ip} \s*%{DATA:sag_tag} \s*%{LOGLEVEL:log_level} \s*%{DATA:log_src} \s*(\[#?)(?<source>.*(?=#\]$))"
}
}
通过文件来定义
定义一个模式文件里边每行都是一个模式
[root@192 patterns]# pwd
/root/logstashacc/patterns
[root@192 patterns]# cat pattern
#LOG_TIME (?>\d\d){1,2}[/-](?:0[1-9]|1[0-2])[/-](?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9])
MYNUM [-]\d+
然后再grok配置文件中通过patterns_dir 属性配置好模式文件所在的目录即可
grok {
patterns_dir =>["/root/logstash/patterns"]
match => {
"message" => "%{TIMESTAMP_ISO8601:op_date} \s*%{IP:sag_ip} \s*%{DATA:sag_tag} \s*%{LOGLEVEL:log_level} \s*%{DATA:log_src} \s*(\[#?)(?<source>.*(?=#\]$))"
}
}
直接在配置文件中使用
如上述配置中的 (\[#?)(?<source>.*(?=#\]$)) 就是直接书写正则表达式
关于表达式的详细规则和语法 请参考这个不错的学习网站 编程胶囊

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)