Elastic stack 技术栈学习(三)—— ES核心概念、在Windows10系统下部署ELK
目录
零、前言
最开始可以认为es类似于百度、谷歌这样的全文搜索引擎/实时搜索平台,用户输入关键词,根据关键词去提取文档。
最后才发现的超级棒的教程:
【狂神说Java】ElasticSearch7.6.x最新完整教程通俗易懂_哔哩哔哩_bilibili
一. Elasticsearch
1. Elasticsearch部署
下载
Download Elasticsearch | Elastic
下载后解压,注意:解压目录中不要有中文。双击bin目录下的elasticsearch.bat就能运行
运行的过程中,有两个端口号需要记住一下。
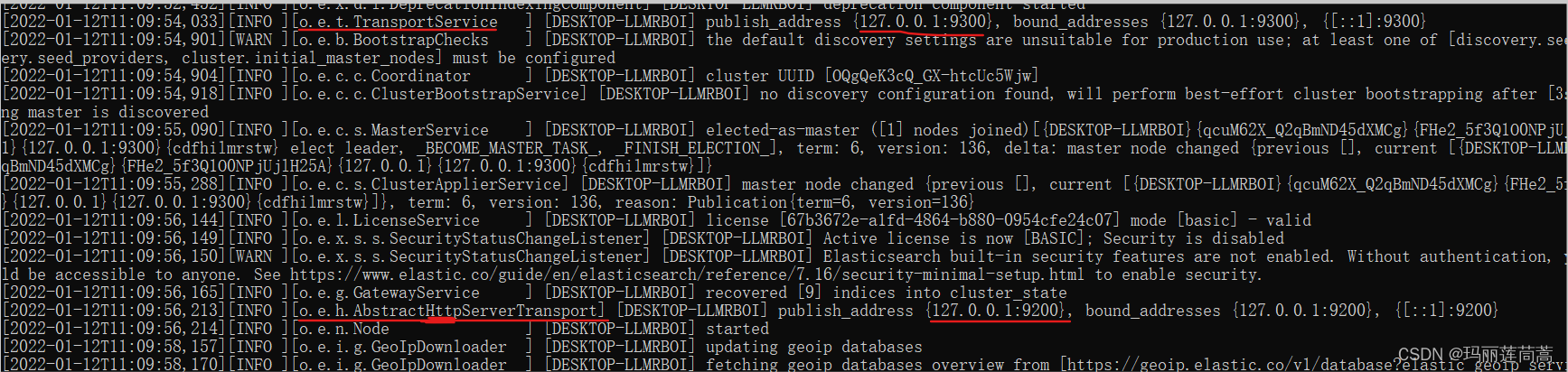
9300端口:为elasticsearch集群件组件的通信端口,简单说就是elasticsearch内部通信的端口。
9200端口:浏览器的访问端口。
打开浏览器,进入http://localhost:9200 测试是否运行成功,看到以下内容说明成功了。

但是运行过程中报了这样一个error(即便是有error也能运行)
[2022-01-06T09:50:50,430][ERROR][o.e.i.g.GeoIpDownloader ] [DESKTOP-LLMRBOI] exception during geoip databases update
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.ssl.Alerts.getSSLException(Alerts.java:192) ~[?:?]
at sun.security.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1949) ~[?:?]
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:302) ~[?:?]
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:296) ~[?:?]
at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1514) ~[?:?]
at sun.security.ssl.ClientHandshaker.processMessage(ClientHandshaker.java:216) ~[?:?]
at sun.security.ssl.Handshaker.processLoop(Handshaker.java:1026) ~[?:?]
at sun.security.ssl.Handshaker.process_record(Handshaker.java:961) ~[?:?]
at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1062) ~[?:?]
at sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1375) ~[?:?]
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1403) ~[?:?]
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1387) ~[?:?]
at sun.net.www.protocol.https.HttpsClient.afterConnect(HttpsClient.java:559) ~[?:?]
at sun.net.www.protocol.https.AbstractDelegateHttpsURLConnection.connect(AbstractDelegateHttpsURLConnection.java:185) ~[?:?]
at sun.net.www.protocol.http.HttpURLConnection.getInputStream0(HttpURLConnection.java:1546) ~[?:?]
at sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1474) ~[?:?]
at java.net.HttpURLConnection.getResponseCode(HttpURLConnection.java:480) ~[?:1.8.0_131]
at sun.net.www.protocol.https.HttpsURLConnectionImpl.getResponseCode(HttpsURLConnectionImpl.java:338) ~[?:?]
at org.elasticsearch.ingest.geoip.HttpClient.lambda$get$0(HttpClient.java:55) ~[ingest-geoip-7.16.2.jar:7.16.2]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_131]
at org.elasticsearch.ingest.geoip.HttpClient.doPrivileged(HttpClient.java:97) ~[ingest-geoip-7.16.2.jar:7.16.2]
at org.elasticsearch.ingest.geoip.HttpClient.get(HttpClient.java:49) ~[ingest-geoip-7.16.2.jar:7.16.2]
at org.elasticsearch.ingest.geoip.HttpClient.getBytes(HttpClient.java:40) ~[ingest-geoip-7.16.2.jar:7.16.2]
at org.elasticsearch.ingest.geoip.GeoIpDownloader.fetchDatabasesOverview(GeoIpDownloader.java:135) ~[ingest-geoip-7.16.2.jar:7.16.2]
at org.elasticsearch.ingest.geoip.GeoIpDownloader.updateDatabases(GeoIpDownloader.java:123) ~[ingest-geoip-7.16.2.jar:7.16.2]
at org.elasticsearch.ingest.geoip.GeoIpDownloader.runDownloader(GeoIpDownloader.java:260) [ingest-geoip-7.16.2.jar:7.16.2]
at org.elasticsearch.ingest.geoip.GeoIpDownloaderTaskExecutor.nodeOperation(GeoIpDownloaderTaskExecutor.java:97) [ingest-geoip-7.16.2.jar:7.16.2]
at org.elasticsearch.ingest.geoip.GeoIpDownloaderTaskExecutor.nodeOperation(GeoIpDownloaderTaskExecutor.java:43) [ingest-geoip-7.16.2.jar:7.16.2]
at org.elasticsearch.persistent.NodePersistentTasksExecutor$1.doRun(NodePersistentTasksExecutor.java:42) [elasticsearch-7.16.2.jar:7.16.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:777) [elasticsearch-7.16.2.jar:7.16.2]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:26) [elasticsearch-7.16.2.jar:7.16.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) [?:1.8.0_131]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) [?:1.8.0_131]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_131]GeoIP报的错误,GeoIP processor | Elasticsearch Guide [7.14] | Elastic
错误信息主要是
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
解决方法如下,就是在下载jre的security目录下加入ssh的安全证书。不过不影响运行所以我就没解决。
解决PKIX:unable to find valid certification path to requested target 的问题_阿飞的专栏-CSDN博客
2. 基本概念
索引:是elasticsearch对逻辑数据的逻辑存储,索引可以分为更小的部分。可以看作关系型数据库的“表”,用来做全文搜索,不存储数据。
文档:用关系型数据库来类比的话,一个文档相当于数据库 表中的一行记录
映射:所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做 映射(mapping)。一般由用户自己定义规则
3. elasticsearch文件夹介绍
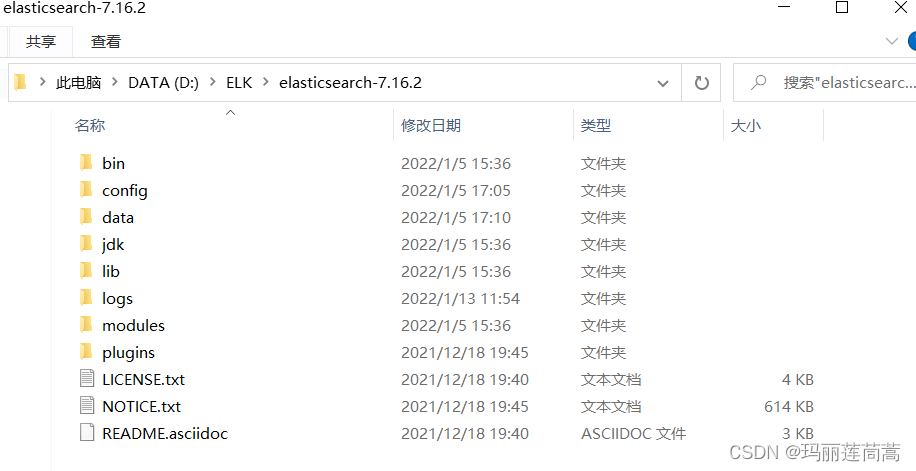
bin :启动文件
date:elasticsearch的数据就存在这里。
config :配置文件
elasticsearch.yml :es的配置文件
log4j2.properties :日志的配置文件,比如哪些日志想要,哪些不想要
jvm.options :Java虚拟机的相关配置。重要的有,es占用的内存大小(如果设置的太大,电脑性能跟不上就跑不起来)
lib :相关jar包
modules: 功能模块
plugins:插件。以后想要加入什么插件就扔进这个目录下。
logs : 日志
在lib文件夹里可以看到很多和Lucene有关的jar包,去搜了一下,Lucene是一个用于全文检索的开源程序库,提供API,Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品。
在Java开发环境里Lucene是一个成熟的免费开放源代码工具,所以被elasticsearch直接拿来用了(可以这样理解,用Lucene去写es,就相当于英伟达用gstreamer去写自己的deepstream)。同时后者也“乖乖”遵守开源软件的理念,因为Lucene是开源的,elasticsearch用了Lucene,所以elasticsearch也要开源。
区分es索引和Lucene倒排索引:
在我们创建es索引的时候,默认的分片数是5,这个分片就是Lucene的倒排索引。一个es索引是由多个Lucene索引组成的。
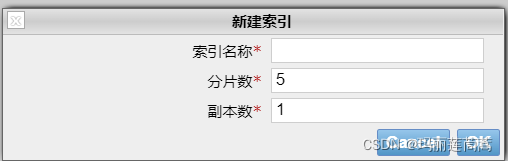
当然,使用es的时候,我们所说的索引自然是es索引。
4. 源码安装elasticsearch-head
elasticsearch-head之于elasticsearch 相当于 sqlyog之于mysql。
- 源码安装,通过npm run start启动(不推荐)
- 通过docker安装(推荐)
- 通过chrome插件安装(推荐)
- 通过ES的plugin方式安装,其实就是下载下来放入es目录下的plugin文件夹,可以去看IK分词器的安装就明白了(不推荐,而且2.0以上的版本就不提供插件了)
采用第一种方式:
依次执行以下4条命令:
git clone git://github.com/mobz/elasticsearch-head.git(因为之前已经安装过git了,所以直接用就行。)
看到package.json就知道这是一个标准的前端项目。
cd elasticsearch-headnpm installnpm run start这里发现npm命令没有安装过。其实nodejs作为前端重要的工具,应该单独拿出来学的。下面附上学习连接:
【狂神说Java】Vue最新快速上手教程通俗易懂_哔哩哔哩_bilibili
【学相伴】大前端技能最通俗易懂的讲解,快速入门必看!NodeJS、Npm、Es6、Babel、Webpack、模块化讲解 | 遇见狂神说 | 飞哥 出品_哔哩哔哩_bilibili
Node.js 安装包及源码下载地址为:Download | Node.js。
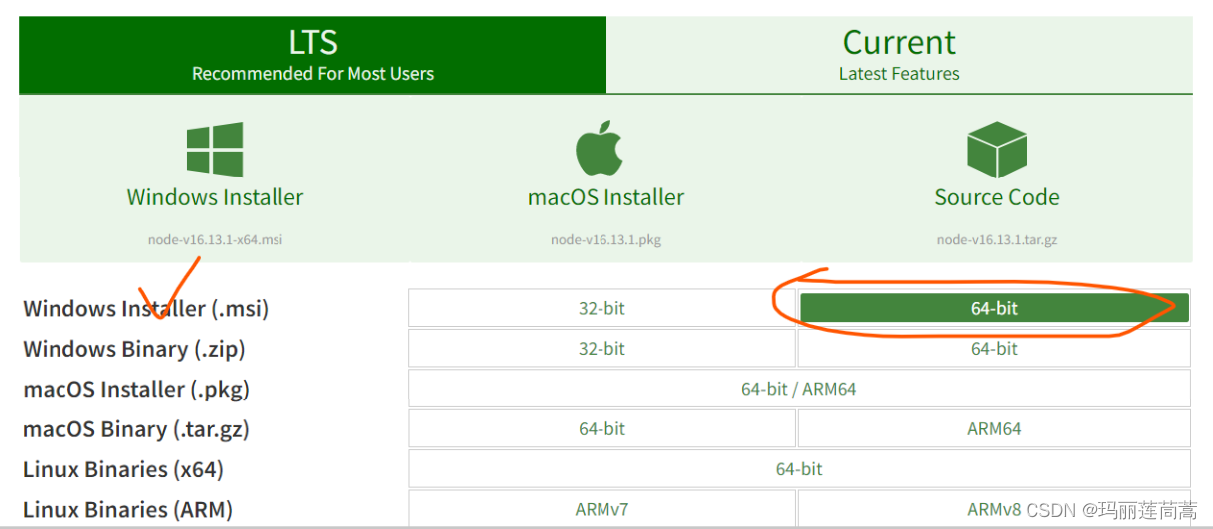
双击下载下来的.msi文件,然后就是类似于一直next那种安装。

去查看系统变量path,我们在安装过程中选择的文件夹已经被自动加入系统环境变量了。
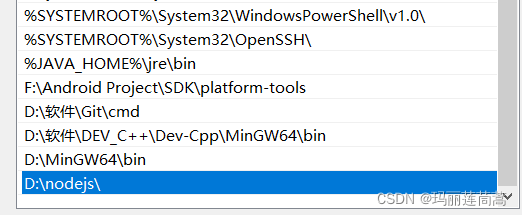
但是仍然无法在命令行运行

但是进入到安装文件夹去运行的时候,是正常的,说明安装是成功的。就是环境变量配置出错了。
解决:
过了几天复盘的时候,发现应该是下面这个问题导致的。环境变量一旦发生更改,需要关掉当前的cmd窗口然后重开一个。解决windows系统环境变量添加失败的问题 (方法之一)_玛丽莲茼蒿的博客-CSDN博客
通过下面的操作让npm命令install下来的依赖放在自定义的文件夹中。(这一步可以不用做)
(1)在node的安装目录中新建如下两个文件夹
(2)在cmd中运行下面两个命令(对的,就是在cmd中,虽然npm命令目前还无法运行)
npm config set prefix "D:\nodejs\node_global"
npm config set cache "D:\nodejs\node_cache" 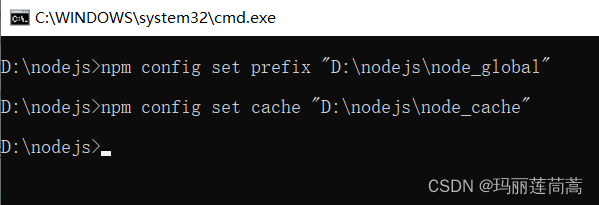
然后现在开始运行第3条命令,
npm install这条命令的作用是: 安装package.json中提到的所有依赖
"devDependencies": {
"grunt": "1.0.1",
"grunt-contrib-concat": "1.0.1",
"grunt-contrib-watch": "1.0.0",
"grunt-contrib-connect": "1.0.2",
"grunt-contrib-copy": "1.0.0",
"grunt-contrib-clean": "1.0.0",
"grunt-contrib-jasmine": "1.0.3",
"karma": "1.3.0",
"grunt-karma": "2.0.0",
"http-proxy": "1.16.x"
}然后报出以下错误:
D:\ELK\elasticsearch-head>npm install
npm ERR! code EPERM
npm ERR! syscall mkdir
npm ERR! path D:\nodejs\node_cache\_cacache
npm ERR! errno EPERM
npm ERR! FetchError: Invalid response body while trying to fetch https://registry.npmjs.org/grunt: EPERM: operation not permitted, mkdir 'D:\nodejs\node_cache\_cacache'
npm ERR! at D:\nodejs\node_modules\npm\node_modules\minipass-fetch\lib\body.js:162:15
npm ERR! at async Arborist.[nodeFromEdge] (D:\nodejs\node_modules\npm\node_modules\@npmcli\arborist\lib\arborist\build-ideal-tree.js:1061:19)
npm ERR! at async Arborist.[buildDepStep] (D:\nodejs\node_modules\npm\node_modules\@npmcli\arborist\lib\arborist\build-ideal-tree.js:930:11)
npm ERR! at async Arborist.buildIdealTree (D:\nodejs\node_modules\npm\node_modules\@npmcli\arborist\lib\arborist\build-ideal-tree.js:216:7)
npm ERR! at async Promise.all (index 1)
npm ERR! at async Arborist.reify (D:\nodejs\node_modules\npm\node_modules\@npmcli\arborist\lib\arborist\reify.js:149:5)
npm ERR! at async Install.install (D:\nodejs\node_modules\npm\lib\install.js:170:5)
npm ERR! FetchError: Invalid response body while trying to fetch https://registry.npmjs.org/grunt: EPERM: operation not permitted, mkdir 'D:\nodejs\node_cache\_cacache'
npm ERR! at D:\nodejs\node_modules\npm\node_modules\minipass-fetch\lib\body.js:162:15
npm ERR! at async Arborist.[nodeFromEdge] (D:\nodejs\node_modules\npm\node_modules\@npmcli\arborist\lib\arborist\build-ideal-tree.js:1061:19)
npm ERR! at async Arborist.[buildDepStep] (D:\nodejs\node_modules\npm\node_modules\@npmcli\arborist\lib\arborist\build-ideal-tree.js:930:11)
npm ERR! at async Arborist.buildIdealTree (D:\nodejs\node_modules\npm\node_modules\@npmcli\arborist\lib\arborist\build-ideal-tree.js:216:7)
npm ERR! at async Promise.all (index 1)
npm ERR! at async Arborist.reify (D:\nodejs\node_modules\npm\node_modules\@npmcli\arborist\lib\arborist\reify.js:149:5)
npm ERR! at async Install.install (D:\nodejs\node_modules\npm\lib\install.js:170:5) {
npm ERR! code: 'EPERM',
npm ERR! errno: 'EPERM',
npm ERR! syscall: 'mkdir',
npm ERR! path: 'D:\\nodejs\\node_cache\\_cacache',
npm ERR! type: 'system',
npm ERR! requiredBy: '.'
npm ERR! }
npm ERR!
npm ERR! The operation was rejected by your operating system.
npm ERR! It's possible that the file was already in use (by a text editor or antivirus),
npm ERR! or that you lack permissions to access it.
npm ERR!
npm ERR! If you believe this might be a permissions issue, please double-check the
npm ERR! permissions of the file and its containing directories, or try running
npm ERR! the command again as root/Administrator.根据最后几行的错误提示,应该是权限的问题。解决方法:给当前用户授予修改这个文件夹的权限。
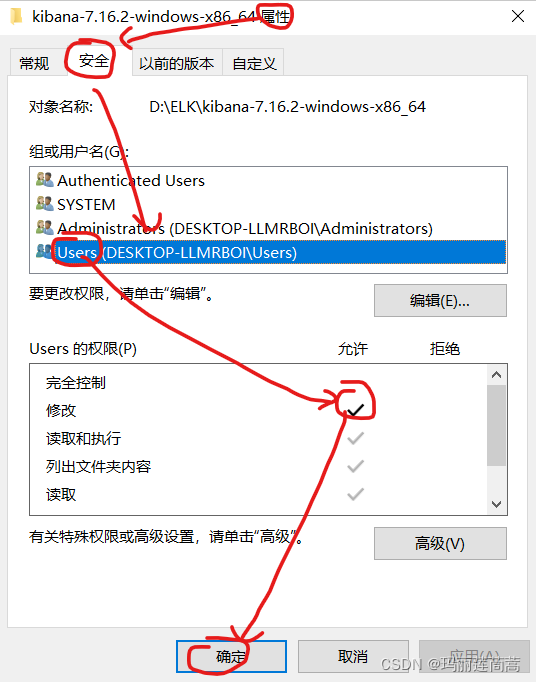
勾选上Users的“修改”权限
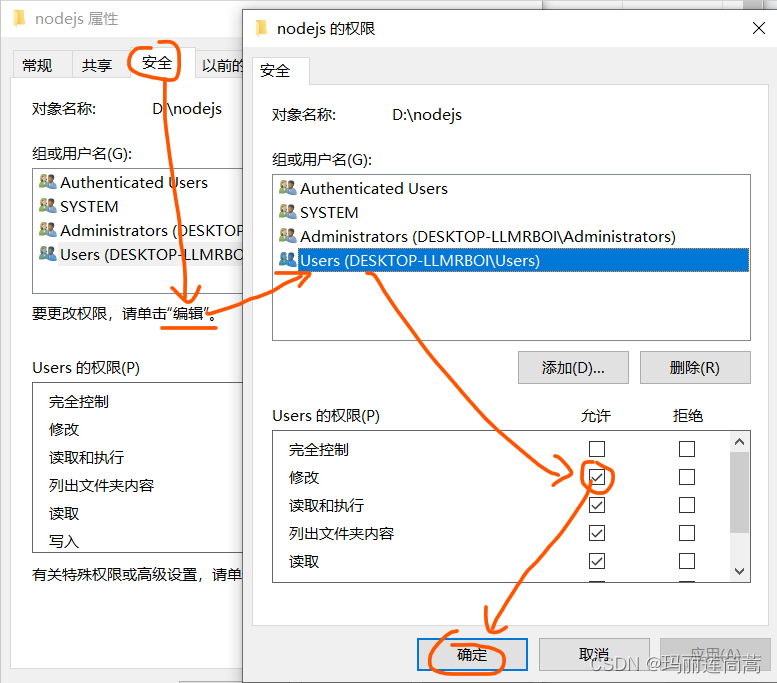
然后执行 npm install命令,上面的权限问题解决了,但是报出了下面的warning和error
npm WARN EBADENGINE Unsupported engine {
npm WARN EBADENGINE package: 'karma@1.3.0',
npm WARN EBADENGINE required: { node: '0.10 || 0.12 || 4 || 5 || 6' },
npm WARN EBADENGINE current: { node: 'v16.13.1', npm: '8.1.2' }
npm WARN EBADENGINE }
npm WARN EBADENGINE Unsupported engine {
npm WARN EBADENGINE package: 'http2@3.3.7',
npm WARN EBADENGINE required: { node: '>=0.12.0 <9.0.0' },
npm WARN EBADENGINE current: { node: 'v16.13.1', npm: '8.1.2' }
npm WARN EBADENGINE }
npm WARN deprecated resolve-url@0.2.1: https://github.com/lydell/resolve-url#deprecated
npm WARN deprecated urix@0.1.0: Please see https://github.com/lydell/urix#deprecated
npm WARN deprecated json3@3.3.2: Please use the native JSON object instead of JSON 3
npm WARN deprecated uuid@3.4.0: Please upgrade to version 7 or higher. Older versions may use Math.random() in certain circumstances, which is known to be problematic. See https://v8.dev/blog/math-random for details.
npm WARN deprecated har-validator@5.1.5: this library is no longer supported
npm WARN deprecated request@2.88.2: request has been deprecated, see https://github.com/request/request/issues/3142
npm WARN deprecated chokidar@1.7.0: Chokidar 2 will break on node v14+. Upgrade to chokidar 3 with 15x less dependencies.
npm WARN deprecated phantomjs-prebuilt@2.1.16: this package is now deprecated
npm WARN deprecated http2@3.3.7: Use the built-in module in node 9.0.0 or newer, instead
npm WARN deprecated coffee-script@1.10.0: CoffeeScript on NPM has moved to "coffeescript" (no hyphen)
npm WARN deprecated core-js@2.6.12: core-js@<3.4 is no longer maintained and not recommended for usage due to the number of issues. Because of the V8 engine whims, feature detection in old core-js versions could cause a slowdown up to 100x even if nothing is polyfilled. Please, upgrade your dependencies to the actual version of core-js.
npm WARN deprecated json3@3.2.6: Please use the native JSON object instead of JSON 3
npm WARN cleanup Failed to remove some directories [
npm WARN cleanup [
npm WARN cleanup 'D:\\ELK\\elasticsearch-head\\node_modules',
npm WARN cleanup [Error: EPERM: operation not permitted, unlink 'D:\ELK\elasticsearch-head\node_modules\lodash\dist\lodash.underscore.js'] {
npm WARN cleanup errno: -4048,
npm WARN cleanup code: 'EPERM',
npm WARN cleanup syscall: 'unlink',
npm WARN cleanup path: 'D:\\ELK\\elasticsearch-head\\node_modules\\lodash\\dist\\lodash.underscore.js'
npm WARN cleanup }
npm WARN cleanup ]
npm WARN cleanup ]
npm notice
npm notice New minor version of npm available! 8.1.2 -> 8.3.0
npm notice Changelog: https://github.com/npm/cli/releases/tag/v8.3.0
npm notice Run npm install -g npm@8.3.0 to update!
npm notice
npm ERR! code ERR_SOCKET_TIMEOUT
npm ERR! network Socket timeout
npm ERR! network This is a problem related to network connectivity.
npm ERR! network In most cases you are behind a proxy or have bad network settings.
npm ERR! network
npm ERR! network If you are behind a proxy, please make sure that the
npm ERR! network 'proxy' config is set properly. See: 'npm help config'
npm ERR! A complete log of this run can be found in:
npm ERR! D:\nodejs\node_cache\_logs\2022-01-09T15_23_55_105Z-debug.log看起来好像是网络问题,在运行一遍还是不行。但是报的错误变了:
......
npm ERR! code 1
npm ERR! path D:\ELK\elasticsearch-head\node_modules\phantomjs-prebuilt
npm ERR! command failed
npm ERR! command C:\WINDOWS\system32\cmd.exe /d /s /c node install.js
npm ERR! PhantomJS not found on PATH
npm ERR! Downloading https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-windows.zip
npm ERR! Saving to C:\Users\DELL\AppData\Local\Temp\phantomjs\phantomjs-2.1.1-windows.zip
npm ERR! Receiving...
npm ERR! Error making request.
npm ERR! Error: read ECONNRESET
npm ERR! at TLSWrap.onStreamRead (node:internal/stream_base_commons:220:20)
npm ERR!
npm ERR! Please report this full log at https://github.com/Medium/phantomjs
又重新运行命令nmp install,这次不报错了。运行这么多次才成功,说白了还是网络问题,因为npm仓库在国外(和maven一样,maven可以设置国内镜像,npm应该也可以设置,不过因为我只用这一次,就没设置)。
added 526 packages, removed 1 package, and audited 527 packages in 2m
8 packages are looking for funding
run `npm fund` for details
40 vulnerabilities (4 low, 3 moderate, 21 high, 12 critical)
To address issues that do not require attention, run:
npm audit fix
To address all issues (including breaking changes), run:
npm audit fix --force
Run `npm audit` for details.
然后输入命令
rmp run start
head运行成功了,太不容易了。我们再登录网址查验一下。
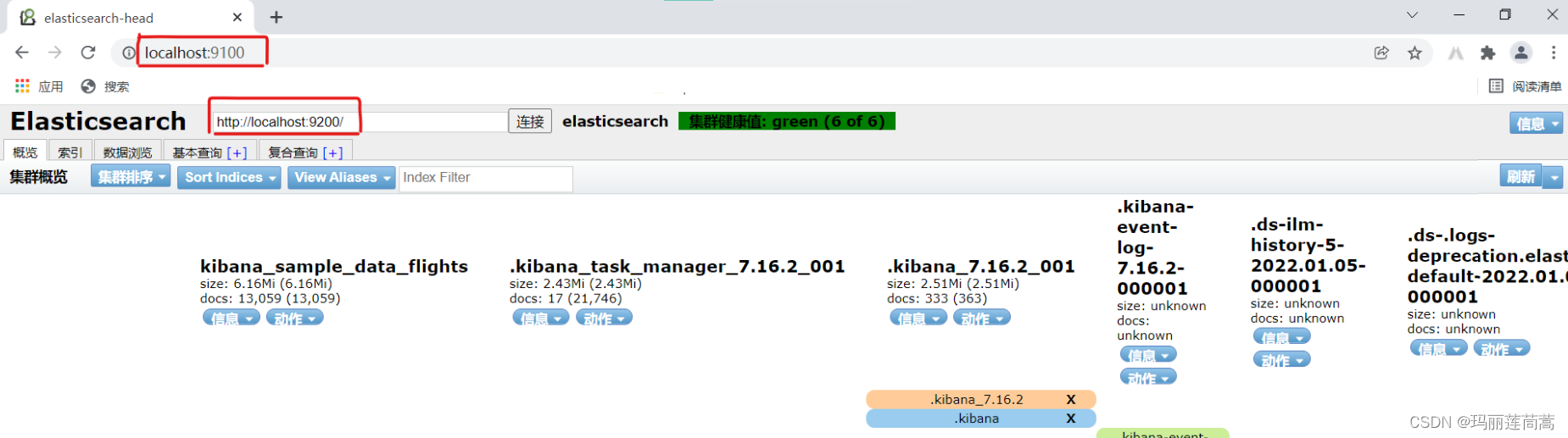
终于按好这个head了。不过集群健康值显示未连接。下面解决这个问题。
思考:首先,elasticsearch是正常开启的,并且命令行报出的日志表明集群状态是健康(green)的。

其次,head也安装好了。所以应该是elasticsearch和elasticsearch-head之间的通信出了问题,图中也显示“集群状态值:未连接”,无法连接的话,考虑是配置的问题。
解决方法:
参考这篇博客ES系列二、CentOS7安装ES head6.3.1 - 小人物的奋斗 - 博客园
更改elasticsearch的配置文件:elasticsearch安装路径/config/elasticsearch.yml.
在最后增加两行:
#------------------------------------Add by mymyslef !!!-------------------------
# ---------------------------To connect with elasticsearch-head------------
http.cors.enabled: true
http.cors.allow-origin: "*"保存,然后重新启动elasticsearch,再次通过浏览器进入http://localhost:9100,连接状态就正常了。
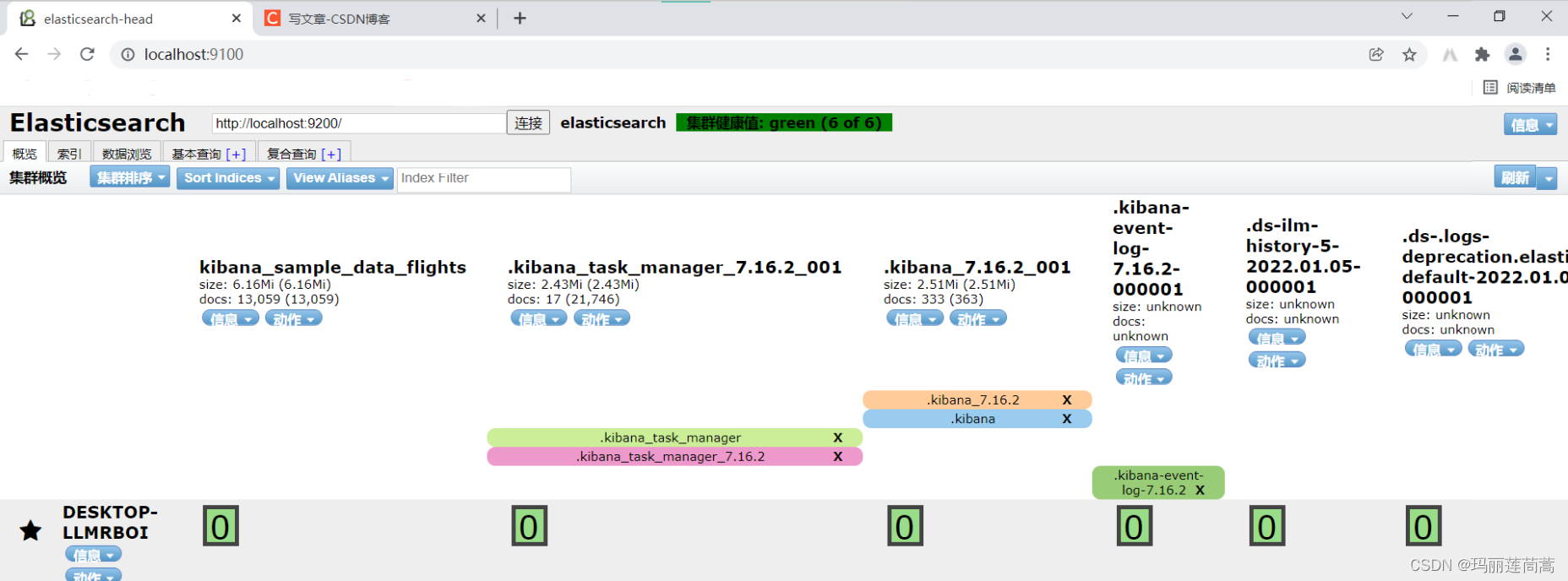
说明:我这是在Windows10系统下搞的,如果是在Linux系统下,可能需要别的配置。
解释:
# 是否支持跨域,默认为false
http.cors.enabled
#当设置允许跨域,默认为*,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使用正则表达式。比如只允许本地地址。 /https?:\/\/localhost(:[0-9]+)?/
http.cors.allow-origin
cros为: Cross-origin resource sharing ,即跨域访问(根据同源策略,只要协议、域名、端口三者有一个不同,就属于跨域)。 默认值为false,为了用户的安全,浏览器默认不允许跨域访问。
所以我们在http://localhost:9100里去访问9200属于端口号不同的跨域访问。
5.elasticsearch-head今后的使用说明
es是一个实时搜索平台/服务器(对外提供9200端口),但是可以直接看成一个关系型数据库。(也就是对于es的认知既可以是一个搜索工具,又可以是一个数据存储工具,就看你怎么去用了)
只把这个head当做数据展示的工具就好,虽然他有利用JSON查询数据的功能,但是在head里面写JSON没有格式是非常不方便的事情。而查询数据这个功能kibana已经做的非常好了,所以以后还是在kibana中查询数据。
基本上只用到下面前三个功能: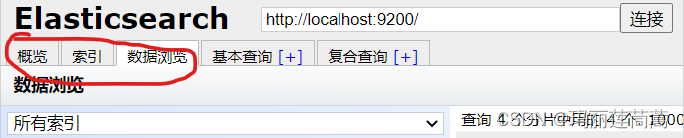
6.核心概念
索引:是elasticsearch对逻辑数据的逻辑存储,索引可以分为更小的部分。可以看作关系型数据库的“表”,用来做全文搜索,不存储数据。
文档:用关系型数据库来类比的话,一个文档相当于数据库 表中的一行记录(关系型数据库的一个元祖)
映射:所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做 映射(mapping)。一般由用户自己定义规则
倒排索引(数据库面试重点):
倒排索引,也是索引。
索引,初衷都是为了快速检索到你要的数据。
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的。
对 Mysql 来说,是 B+ 树,对 Elasticsearch/Lucene 来说,是倒排索引。
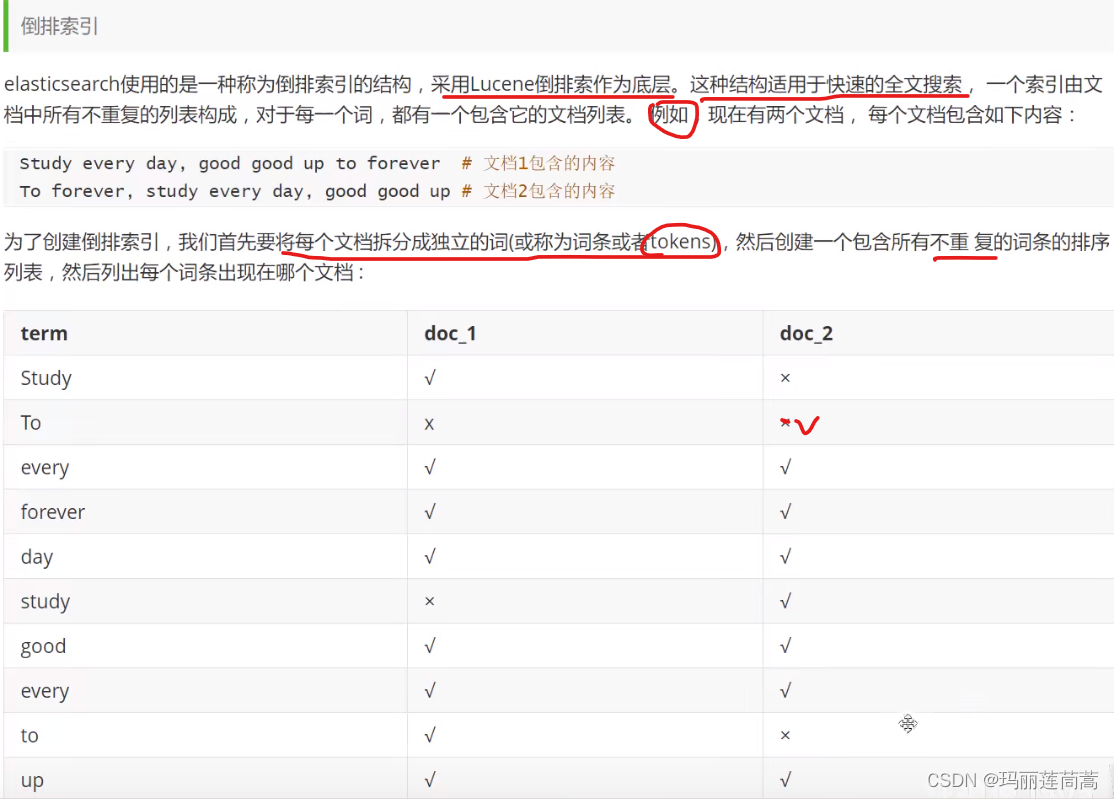
比如说,现在我要搜索“to forever”,doc_1里面既匹配了to又匹配了forever,doc_2只匹配了to,那么doc_1的权重就更高(和我们搜索的更相关,或者说,用百度搜索搜到的结果中,doc_1出现的位置更靠前)
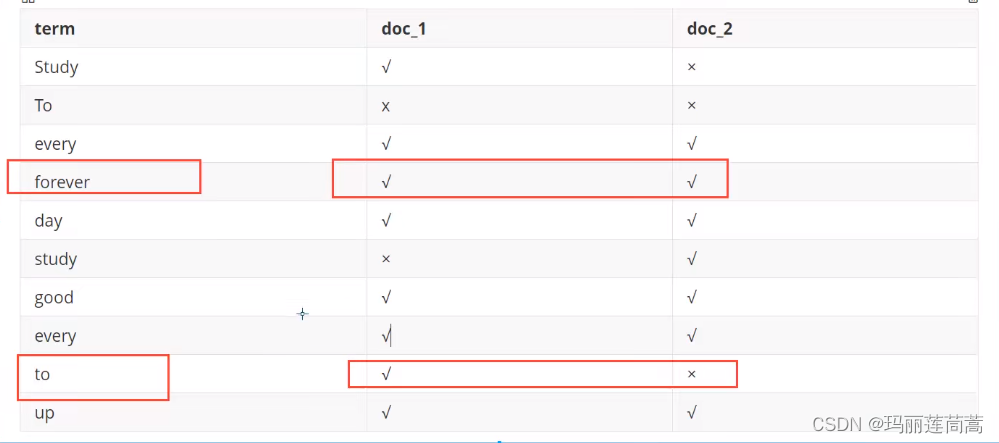
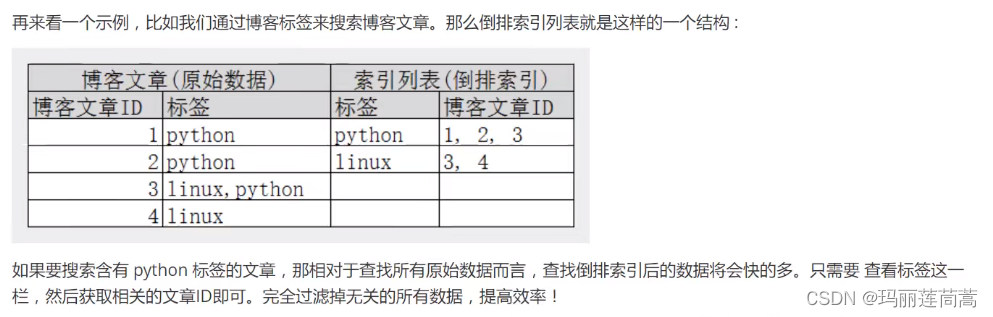
有了倒排索引后,根据用户输入的关键字,就可以立马定位到有这个关键字的文档,这一步的时间复杂度是O(1)。那么现在压力给到了关键字的定位这边,所有文档拆分出了成千上万个关键字,如何定位到用户输入的那个关键字呢?从头到尾全局遍历肯定不行。
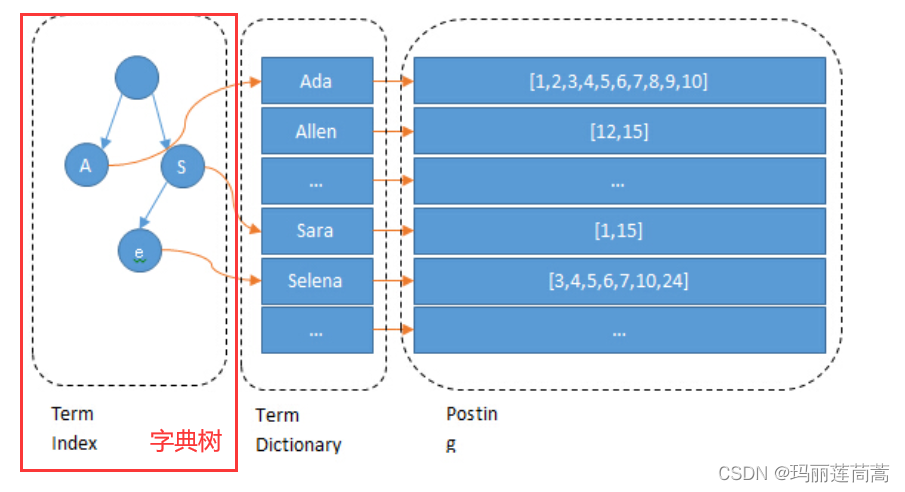
Lucene 的倒排索,增加了最左边的一层「字典树」term index,它不存储所有的单词,只存储单词前缀,通过字典树找到单词所在的块,也就是单词的大概位置,再在块里二分查找,找到对应的单词,再找到单词对应的文档列表。
当然,内存寸土寸金,能省则省,所以 Lucene 还用了 FST(Finite State Transducers)对它进一步压缩。
 https://blog.csdn.net/u013008898/article/details/116493167
https://blog.csdn.net/u013008898/article/details/116493167二、下载安装JDK
PS: 其实elasticsearch已经内置了jdk:
不过开发人员普遍使用自己在本机安装的jdk。
因为我之前安装过JDK,所以检查一下环境变量是否正确就可以了。
三、Kibana
1.下载
版本要和elasticsearch一致,都下载的7.16.2版本
Download Kibana Free | Get Started Now | Elastic

打开kibana,双击bin文件夹下的kibana.bat,注意需要先打开elasticsearch才能打开kibana。
这个等的时间比较久。然后进入http://localhost:5601测试是否成功。成功的话进入如下页面
2.错误处理
可以看到上面kibana是成功运行了的。但是一个多周以后又不行了。命令行报出了下面的错误:
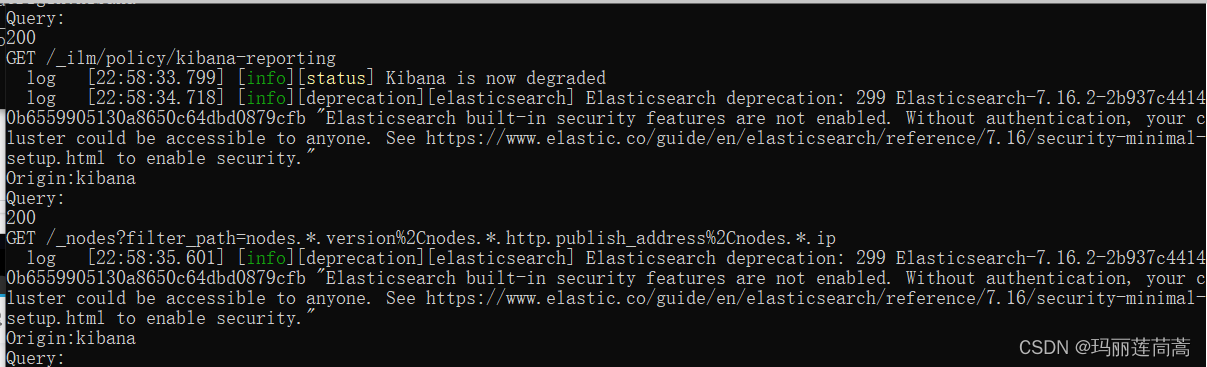
http://localhost:5601也无法访问。
打眼儿一看,好像是权限的问题。先尝试一下修改权限,给kibana的用户目录加上普通用户的修改权限。
再次运行还是一样的问题,不过多尝试几次5601就能访问了。
3.kibana汉化
在kibana工作目录的如下路径中(不同版本的路径不太一样,总之就是在kibana的工作目录下去搜索zh-CN.json文件就可以了)
可以看到有一个将近3万行的人工翻译的json文件:zh-CN.json
这便是开发人员提供给我们用来汉化的。
如何汉化:
在config目录里找到kibana.yml文件,更改最后一个配置项。可以看到默认是英文“en”,改成"zh-CN"
# Specifies locale to be used for all localizable strings, dates and number formats.
# Supported languages are the following: English - en , by default , Chinese - zh-CN .
#i18n.locale: "en"
i18n.locale: "zh-CN"更改配置项后,重新启动kibana才可以看到汉化的结果。
4、在es中创建索引并可视化
(1)运行elasticsearch、elasticsearch-head和kibana
(2)在开发工具(Dev tools)中,用PUT命令创建索引test1,顺便给出4个文档("zxf","wanna_sleep","morning","small_new_year")各个字段的值。
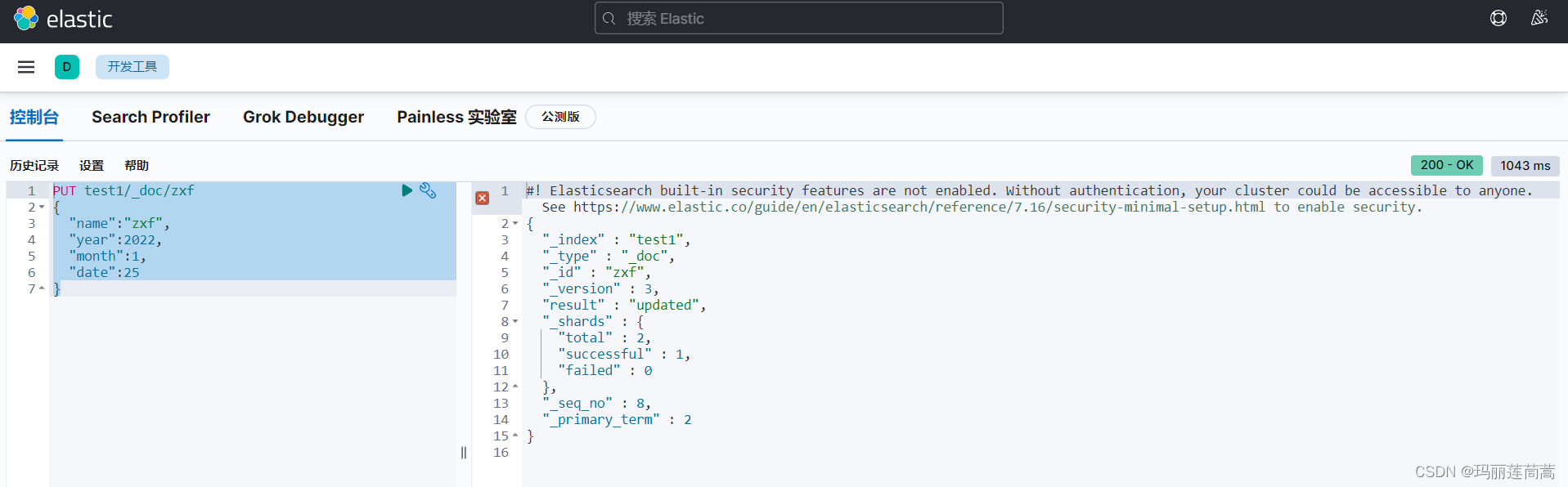
PUT test1/_doc/zxf
{
"name":"zxf",
"year":2022,
"month":1,
"date":25
}
PUT test1/_doc/wanna_sleep
{
"name":"wanna sleep",
"year":2022,
"month":1,
"date":25
}
PUT test1/_doc/morning
{
"name":"morning",
"year":2022,
"month":1,
"date":25
}
PUT test1/_doc/small_new_year
{
"name":"small_new_year",
"year":2022,
"month":1,
"date":25
}来head中查看一下,
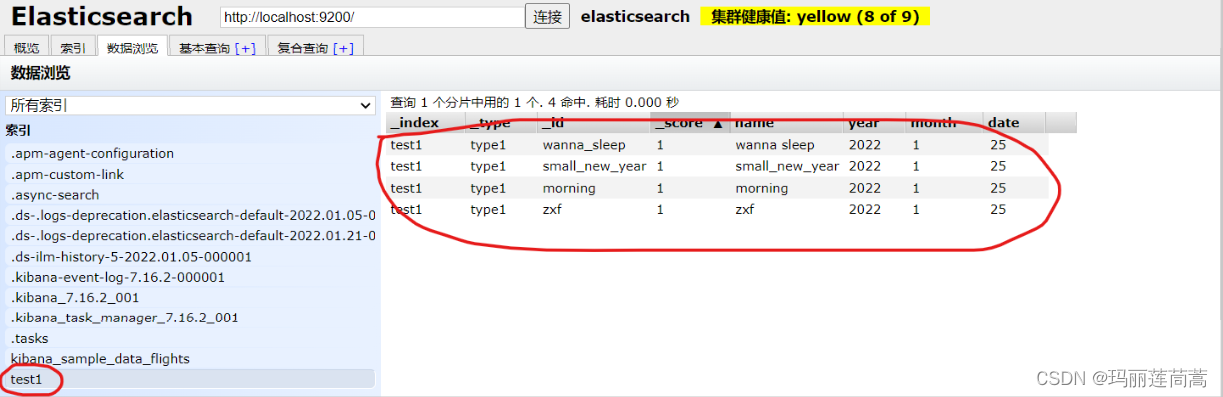
在Elastic(7.0以上的版本访问5601端口打开的不是kibana的页面了,改成Elastic了)的Discover中也能看到。
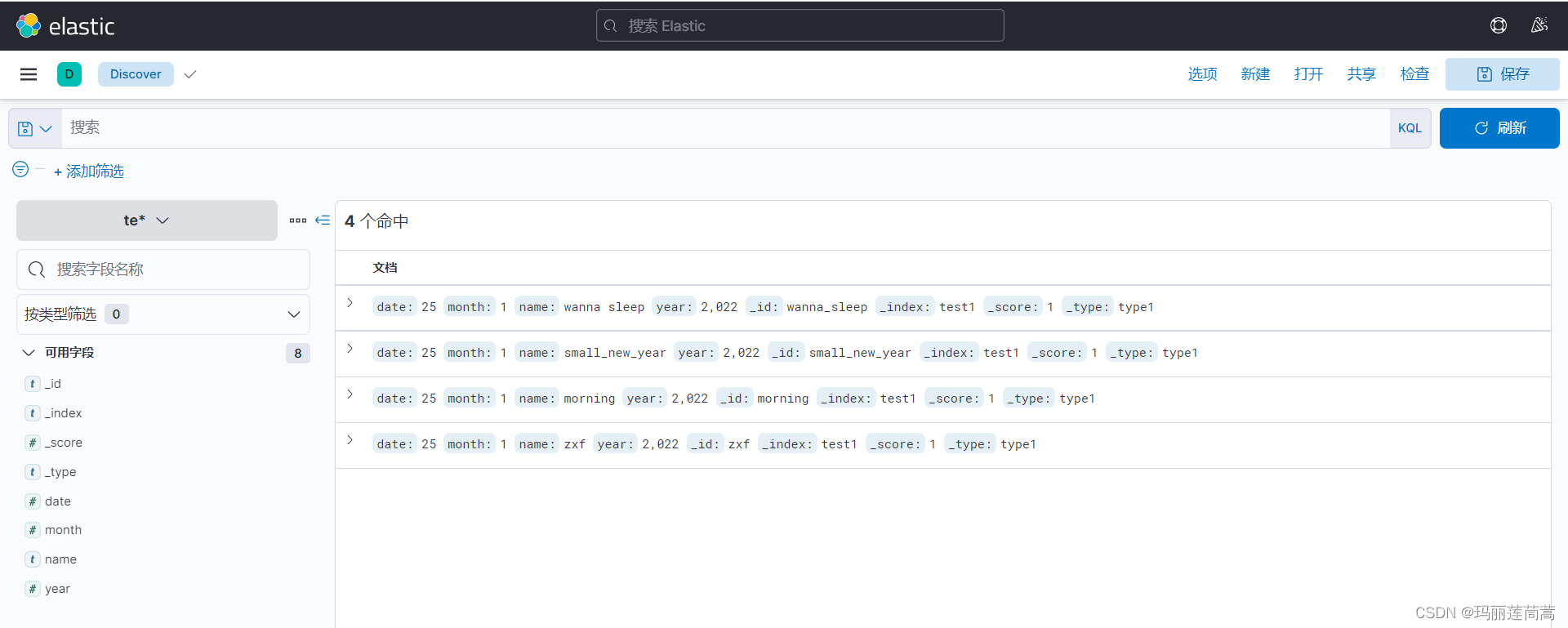
现在我们知道,索引创建成功。
(3)在kibana中点击“创建索引模式”。
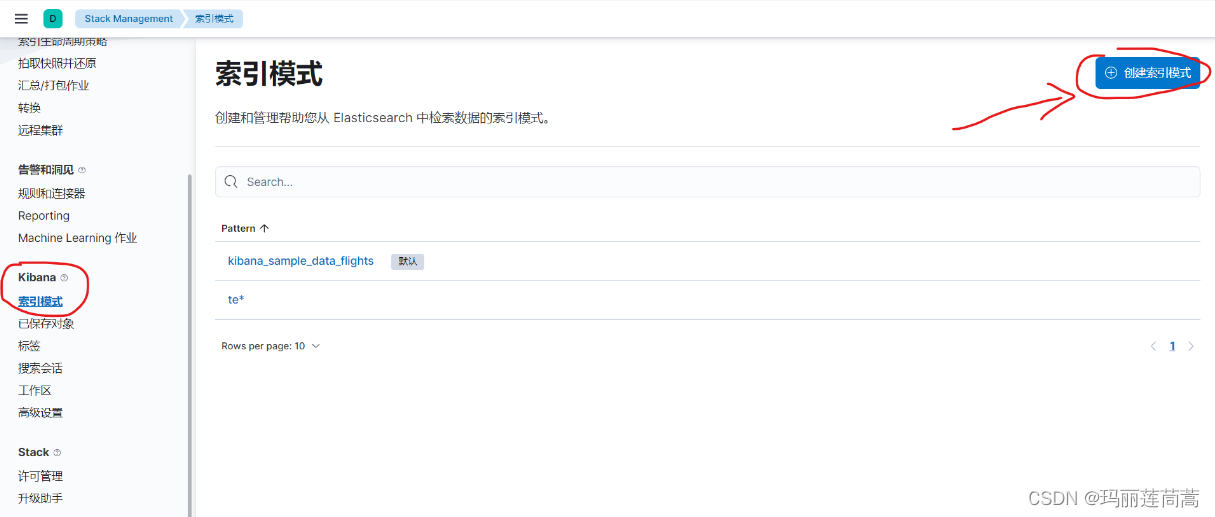
输入索引名称,以匹配我们刚刚创建的索引源。然后点击“创建索引模式”
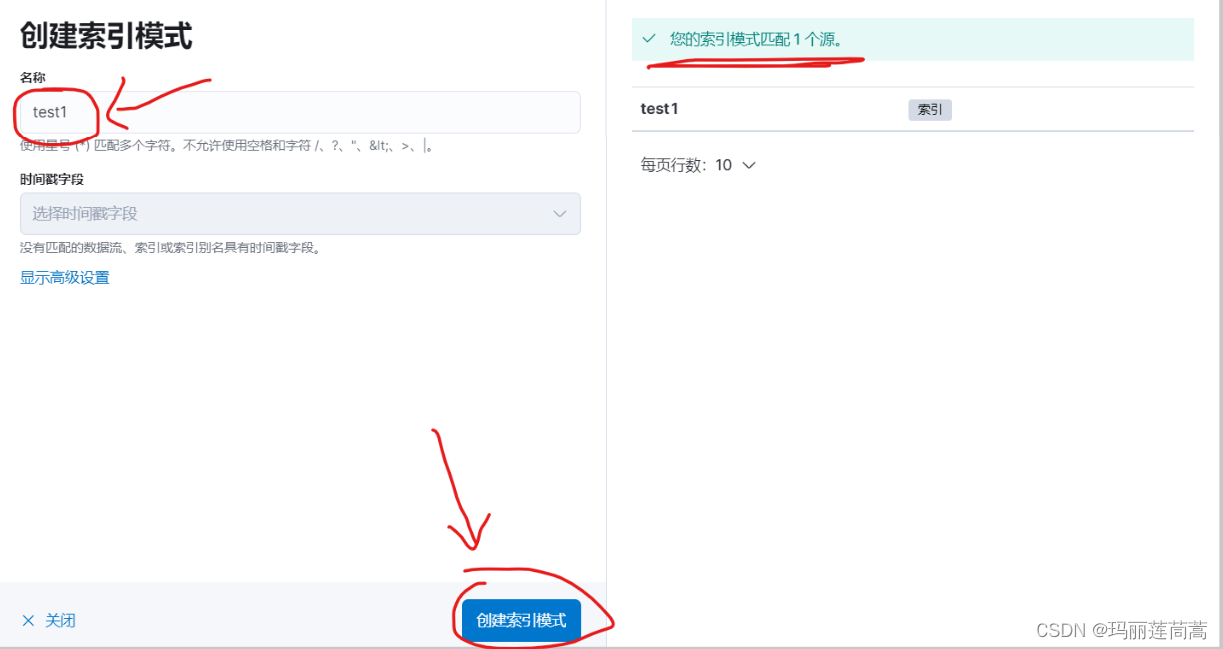
返回创建成功的页面
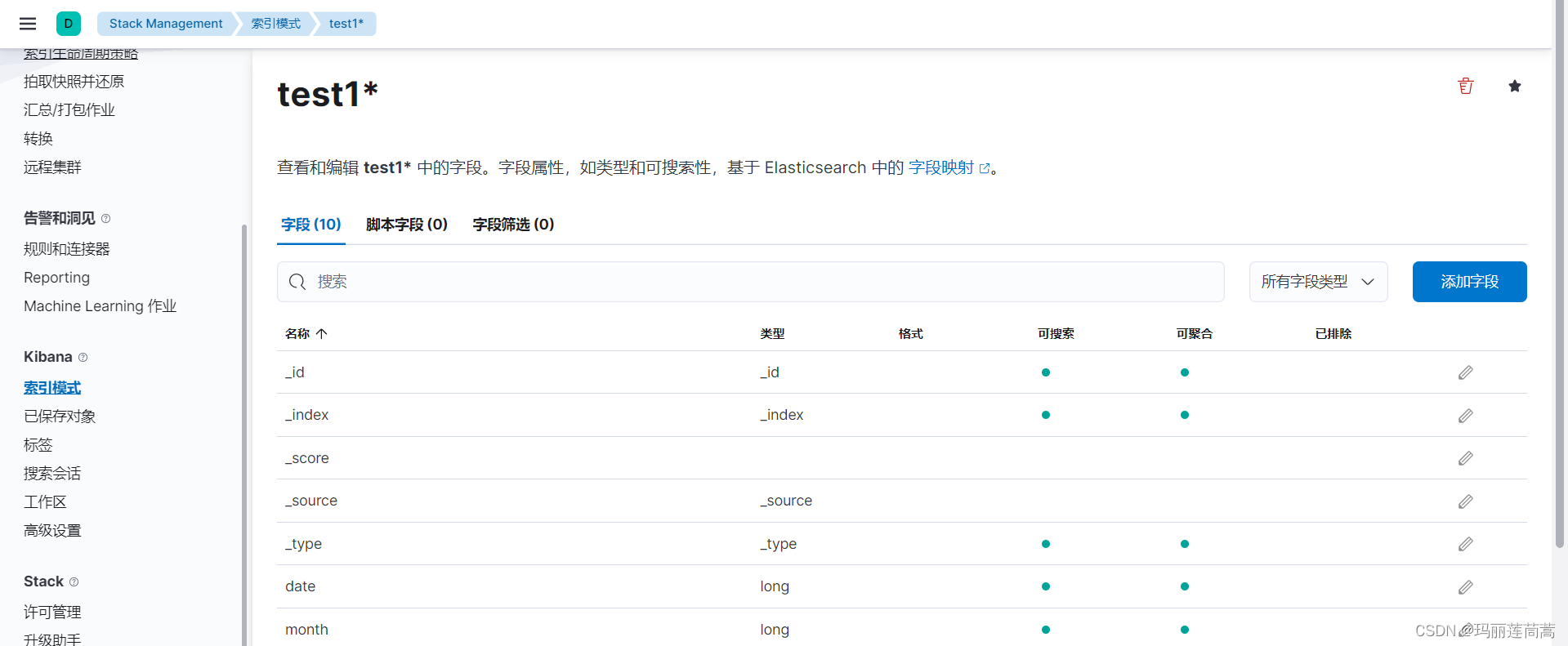
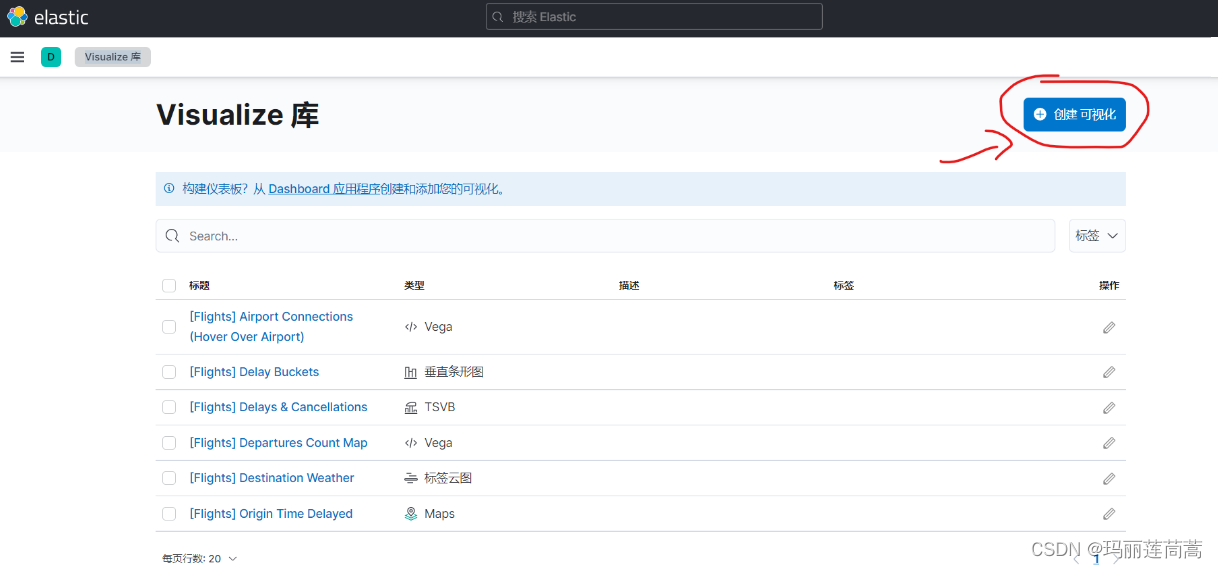
搜索进入“Visualize 库” ,点击“创建可视化”
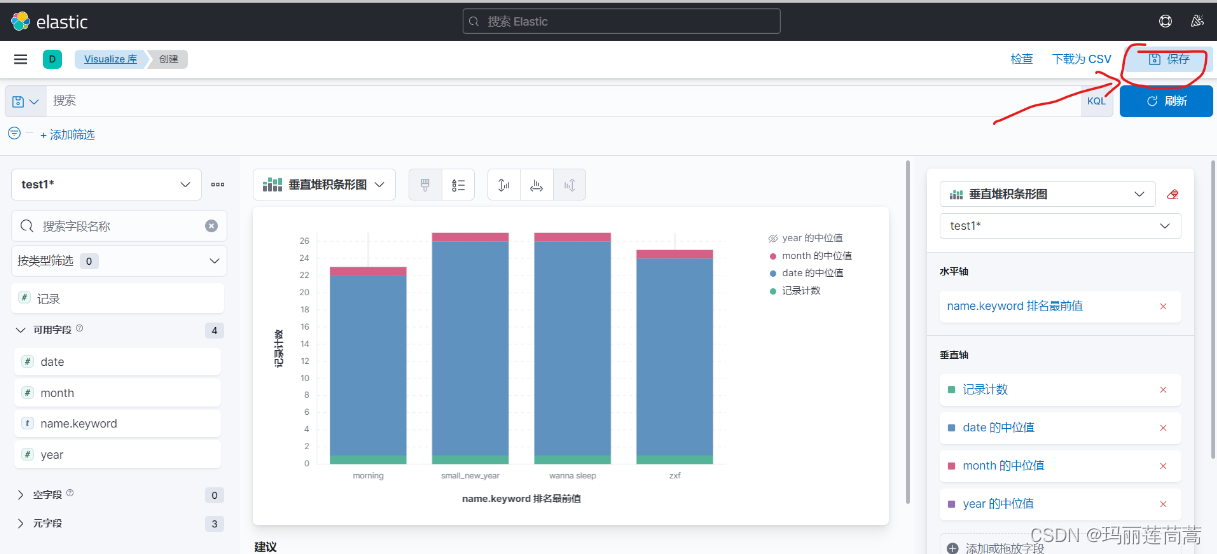
自行创建可视化图标,然后点击右上角保存
选择新建一个仪表盘
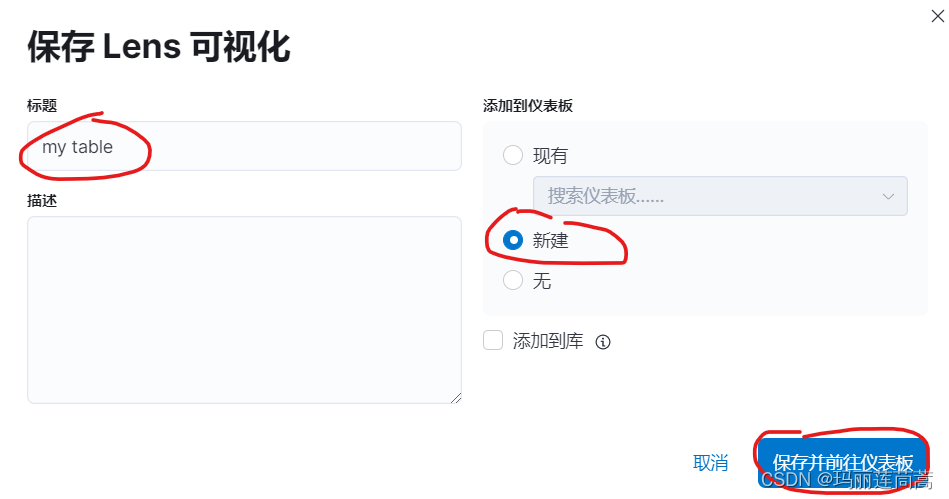
给仪表盘命名“my dashboard2”后,保存仪表盘。来到仪表盘页面查看,可以看到新建的仪表盘
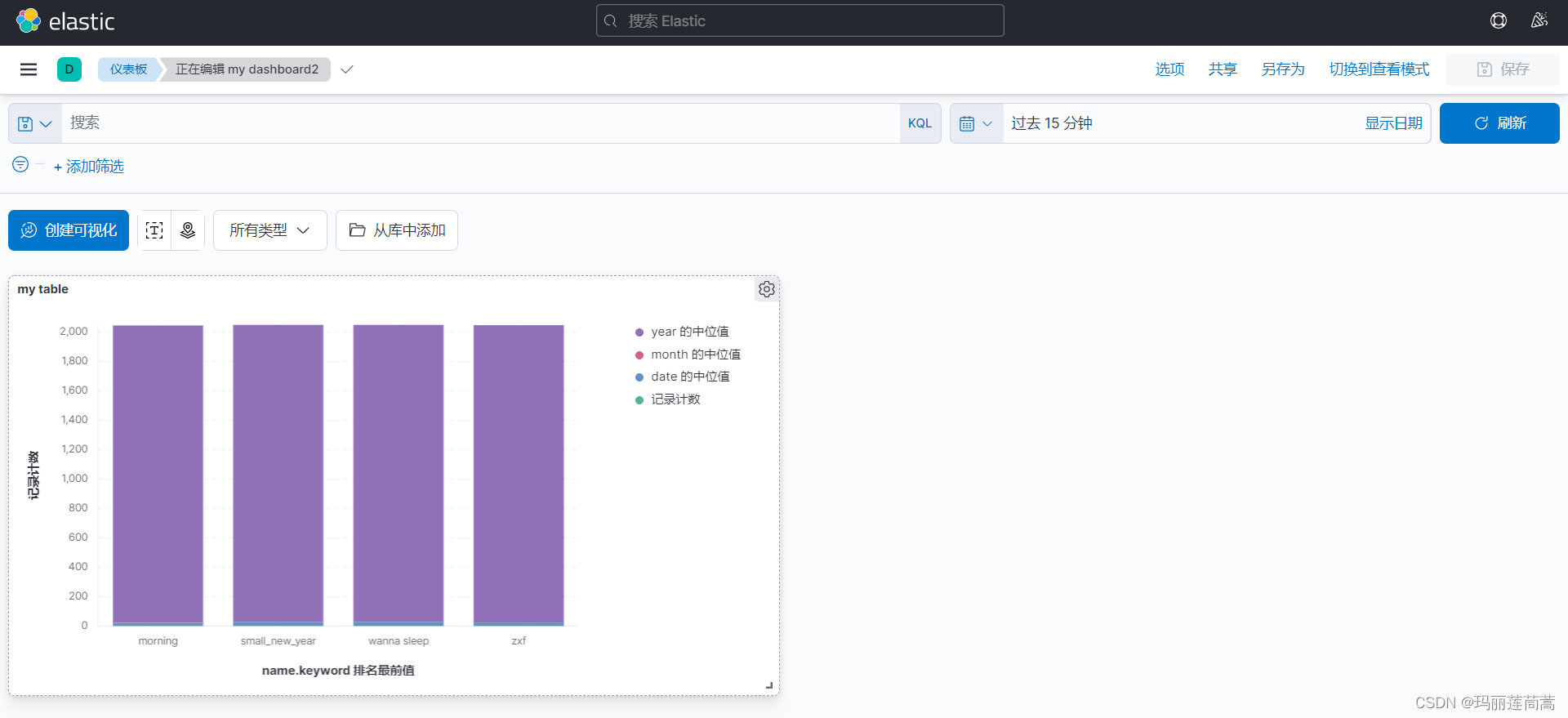
进入就可以看到对索引的可视化
四、学习到的内容
1. npm的作用,以及npm和node.js的关系
https://blog.csdn.net/qq_44886213/article/details/122401803
2.跨域请求

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)