大数据中台架构以及建设全流程一(Paas层设计)
设计背景当企业发展到一定规模时候有了不同的业务线以及数据规模,因为业务的快速发展。这个时候一些数据问题就会出现。问题点1:数据脏乱差,各部门生产线数据重复冗余,还不可:复用用存在数据孤岛2:数据开发部门的业务来自各部门各产品线,需求不明确,每天业务量繁复,日常工作可能成了sqlboy到处捞数据,而且在业务方面还没有业务部门了解的深入,有点缘木求鱼的意思。这个时候数据中台也就应运...
目录
实时存储平台----------->KAFKA(未来pulsar也不错)
设计背景
当企业发展到一定规模时候有了不同的业务线以及数据规模,因为业务的快速发展。这个时候一些数据问题就会出现。
问题点
1:数据脏乱差,各部门生产线数据重复冗余,还不可:复用用存在数据孤岛
2:数据开发部门的业务来自各部门各产品线,需求不明确,每天业务量繁复,日常工作可能成了sqlboy到处捞数据,而且在业务方面还没有业务部门了解的深入,有点缘木求鱼的意思。
这个时候数据中台也就应运而生。
中台目标
复用,赋能,降本增效
1:面向业务,数据进行建模。
2:数据整合避免烟囱式开发解决数据孤岛问题。
3:赋能给各个业务部门,将能力下放将数据的使用权限赋予各个部门,减少数据开发部门繁琐的数据sql业务。
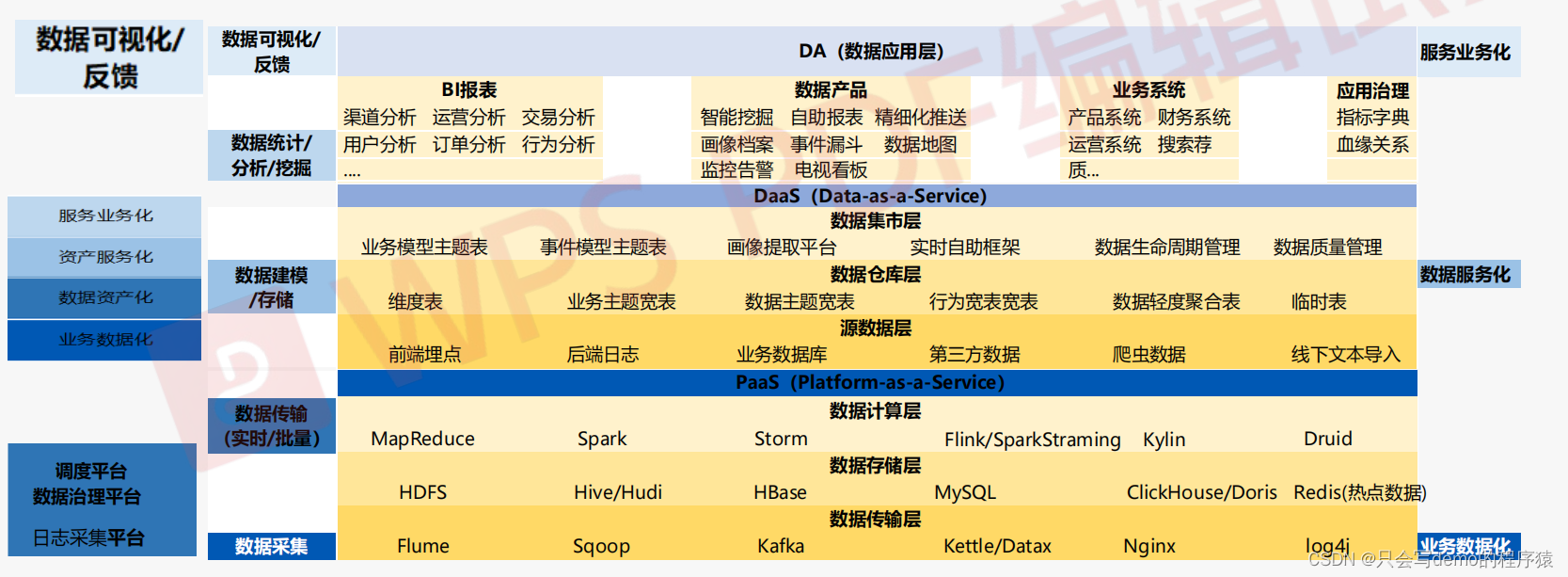
中台整体架构

Pass层技术选型
实时存储平台----------->KAFKA(未来pulsar也不错)
0.8版本标志着kafaka成熟
0.9版本提供了安全模块,偏移量也由zk转移到自己的topic进行管理了
0.10版本提供了流计算,生产者优化(提供了批次发送,默认16k发送一次),提供了机架感知
0.11版本生产者提供了幂等性和事物
1.x没啥特别优化
2.x优化stream,安全力度更细
所以0.11版本后都可以,版本太高也要考虑兼容性问题
tips:kafka因为内存是页存储,磁盘是顺序读写,因为顺序读写速度不亚于内存。所以kafka对于是内存还是磁盘需求不大
样例:假设平台每天接受一亿次实时请求,kafka如何hold住?

内存:假如一个集群有3个topic,这3个topic的partition的数据在os cache里效果当然是最好的。3个topic,一个topic有假如30个partition。那么 总共会有90个partition。每个partition的Log文件大小是1G,我们有 3个副本,也就是说要把90个topic的partition数据都驻留在内存里需 要270G的内存。我们现在有3台服务器,所以平均下来每天服务器需 要90G的内存,但是其实partition的数据我们没必要所有的都要驻留 在内存里面,10-20%的数据在内存就非常好了,90G * 0.2 = 18G就 可以了。所以64g内存的服务 器也非常够用了。
cpu:主要是看Kafka进程里会有多少个线程,线程主要是依托多核CPU来执行的,如果线程特别多,但是 CPU核很少,就会导致CPU负载很高,会导致整体工作线程执行的效率不太高。 来Kafka内部有100多个线程,4个cpu core,一般来说几十个线程,在高峰期CPU几乎都快打满了。8个cpu ,能够比较宽裕的 支撑几十个线程繁忙的工作。所以Kafka的服务器一般是建议16核,基本上可以hold住一两百线程的工作。当然如果可以给到32 cpu 那就更加的宽裕。
网卡:
离线存储平台(Hadoop系列)
Hadoop选型
1:Apache社区版本
a:开源,免费
b:更新快,新特性多
c: Bug多,需考虑各组件兼容性
2:Cloudera
a:分开源,免费版本。目前都要收费了
b:稳定,不需要考虑兼容性问题
c:有clouderaManager管理工具可视化界面很友好
d: 版本因为稳定,更新慢。新特性尝鲜少。且收费(!这点估计很多都不会选择)
3:Hortonworks
a:万全开源免费
b:稳定,不需要考虑兼容性问题
c:有集群管理工具可视化界面很友好
d: 流行度不高
TIPS:
1.x 稳定版本
2.0支持高可用,支持联邦
2.7x流行度广比较稳定,建议2.7.5以后
3.x HA支持多个namenode,增加纠删码功能。可以减少副本,文件块里面存了一部分压缩元数据,另外一部分用于存储校验数据可以用于数据恢复。就可以减少副本存储数。当然也可以多副本和纠删码同时开启。但是缺乏数据本地性问题
机架感知
硬件选型(PB级)
cpu:推荐4路32核等,主频至少2-2.5GHz
内存:推荐64-256GB
磁盘:分为2组,系统盘和数据盘,系统盘2T*2,做raid1,数据盘2-10T左右(SSD,SAS)磁盘当然选择ssd性能更好,但是价格偏贵。每个数据盘在2-10T左右不宜太大,数据量太大读写慢,寻址慢。比如磁盘坏了或者导数据,磁盘数据量太大就很麻烦。
网卡:万兆网卡(光纤卡),很有钱十万兆网卡也可以。
电源:均配置冗余电源,有条件的可以具备发电能力。
内存配置
NameNode
资源计算
关键参数
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--指定hdfs的nameservice为zzhadoop,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>nxhadoop</value>
</property>
<!-- zzhadoop下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.zzhadoop</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.zzhadoop.nn1</name>
<value>hadoop01:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.zzhadoop.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- dn 与 nn的rpc端口-->
<property>
<name>dfs.namenode.servicerpc-address.zzhadoop.nn1</name>
<value>hadoop01:53310</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.zzhadoop.nn2</name>
<value>hadoop02:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.zzhadoop.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.zzhadoop.nn2</name>
<value>hadoop02:53310</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop03:8485;hadoop04:8485;hadoop05:8485/zzhadoop-joural</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/zdp/hadoop/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.zzhadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(zdp:22)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>1000</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/zdp/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/zdp/hadoop/hdfs/dfs.namenode.name.dir</value>
</property>
<!-- 多块磁盘的话可以把fsimage与edits分开
<property>
<name>dfs.namenode.edits.dir</name>
<value>${dfs.namenode.name.dir}</value>
</property>
-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data0/hdfs/dfs.data,file:///data1/hdfs/dfs.data,file:///data2/hdfs/dfs.data,file:///data3/hdfs/dfs.data,file:///data4/hdfs/dfs.data,file:///data5/hdfs/dfs.data,file:///data6/hdfs/dfs.data,file:///data7/hdfs/dfs.data,file:///data8/hdfs/dfs.data,file:///data9/hdfs/dfs.data,file:///data10/hdfs/dfs.data,file:///data11/hdfs/dfs.data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>31457280</value>
</property>
<!-- 磁盘访问策略 -->
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<property>
<name>dfs.datanode.failed.volumes.tolerated</name>
<value>2</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>6000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>107374182400</value>
</property>
<!--
<property>
<name>ha.health-monitor.rpc-timeout.ms</name>
<value>300000</value>
</property>
-->
<!-- 权限设置 -->
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>zdp</value>
</property>
<property>
<name>fs.permissions.umask-mode</name>
<value>022</value>
</property>
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
<!-- 1019 -->
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
</property>
<property>
<name>dfs.namenode.fs-limits.max-component-length</name>
<value>0</value>
</property>
</configuration>
core-site.xml样例如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop03:2181,hadoop04:2181,hadoop05:2181/hadoop</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/zdp/hadoop/hadoop_tmp/tmp</value>
<description>A base for other temporarydirectories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.BZip2Codec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>ipc.server.read.threadpool.size</name>
<value>3</value>
<description>
Reader thread num, rpc中reader线程个数
</description>
</property>
<!-- Rack Awareness -->
<property>
<name>net.topology.script.file.name</name>
<value>/opt/soft/zdp/hadoop-2.7.5/etc/hadoop/rack_awareness.py</value>
</property>
<property>
<name>net.topology.script.number.args</name>
<value>100</value>
</property>
<!-- 改变dr.who为superuser(即启动用户), 在页面上可以访问任意目录 -->
<!--
<property>
<name>hadoop.http.staticuser.user</name>
<value>work</value>
</property>
-->
<property>
<name>hadoop.proxyuser.zdp.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.zdp.groups</name>
<value>*</value>
</property>
<!-- 功能待验证 security.client.protocol.hosts -->
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
</configuration>
存储平台常见故障
1:下线DataNode
在HDFS集群中,Namenode主机上存储了所有的元数据信息,如果此信息丢失,那么整个HDFS上面的数据将不可用,而如果Namenode服务器发生了故障无法启动,
解决的方法分为两种情况:
如果Namenode做了高可用服务,那么在主Namenode故障后,Namenode服务会自动切换到备用的 Namenode上,这个过程是自动的,无需手工介入。
如果你的Namenode没做高可用服务,那么还可以借助于SecondaryNameNode服务,在 SecondaryNameNode主机上找到元数据信息,然后直接在此节点启动Namenode服务即可,种方式可能会丢失部分数据,因为SecondaryNameNode实现的是Namenode的冷备份。 由此可知,对Namenode进行容灾备份至关重要,在生产环境下,建议通过standby Namenode实现Namenode的高可用热备份。
4:yarn被标记为不健康
调度系统(Yarn)

yarn-site.xml参考配置如下
<?xml version="1.0"?>
<configuration>
<!--ha related configuration-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rm</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop2</value>
</property>
<!--rm1 address-->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop1:8088</value>
</property>
<!--rm2 address-->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hadoop2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop011:2181,hadoop012:2181,hadoop013:2181/zzhadoop</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_HOME/etc/hadoop/,
$HADOOP_HOME/share/hadoop/common/*,$HADOOP_HOME/share/hadoop/common/lib/*,
$HADOOP_HOME/share/hadoop/hdfs/*,$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOME/share/hadoop/mapreduce/*,$HADOOP_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,$HADOOP_HOME/share/hadoop/yarn/lib/*,
$HADOOP_HOME/share/hadoop/tools/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<!-- 配置多块磁盘目录,用逗号隔开 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///data0/yarn/nm-local-dir,file:///data1/yarn/nm-local-dir,file:///data2/yarn/nm-local-dir,file:///data3/yarn/nm-local-dir,file:///data4/yarn/nm-local-dir,file:///data5/yarn/nm-local-dir,file:///data6/yarn/nm-local-dir,file:///data7/yarn/nm-local-dir,file:///data8/yarn/nm-local-dir,file:///data9/yarn/nm-local-dir,file:///data10/yarn/nm-local-dir,file:///data11/yarn/nm-local-dir</value>
<description>
An application's localized file directory will be found in: ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}.
</description>
</property>
<!-- 配置多块磁盘目录,用逗号隔开 -->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///data0/yarn/userlogs,file:///data1/yarn/userlogs,file:///data2/yarn/userlogs,file:///data3/yarn/userlogs,file:///data4/yarn/userlogs,file:///data5/yarn/userlogs,file:///data6/yarn/userlogs,file:///data7/yarn/userlogs,file:///data8/yarn/userlogs,file:///data9/yarn/userlogs,file:///data10/yarn/userlogs,file:///data11/yarn/userlogs</value>
<description>
Where to store container logs. Each container directory will contain the files stderr, stdin, and syslog generated by that container.
</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<!-- 3days -->
</property>
<!-- hadoop hdfs目录 -->
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/yarn/apps/logs</value>
</property>
<!-- hadoop hdfs目录 -->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/yarn/staging</value>
</property>
<!-- for spark history server log-->
<property>
<name>yarn.log.server.url</name>
<value>http://nxhadoop011:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.resourcemanager.am.max-retries</name>
<value>3</value>
</property>
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>3</value>
</property>
<property>
<description>How long to wait until a node manager is considered dead.</description>
<name>yarn.nm.liveness-monitor.expiry-interval-ms</name>
<value>120000</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<property>
<name>yarn.am.liveness-monitor.expiry-interval-ms</name>
<value>120000</value>
</property>
<property>
<name>yarn.resourcemanager.rm.container-allocation.expiry-interval-ms</name>
<value>120000</value>
</property>
<property>
<description>Amount of physical memory, in MB, that can be allocated for containers.</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>102400</value>
</property>
<property>
<description>Number of CPU cores that can be allocated for containers.</description>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
<!-- fair scheduler-->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/opt/soft/zdp/hadoop/etc/hadoop/fair-scheduler.xml</value>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.sizebasedweight</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.assignmultiple</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.max.assign</name>
<value>3</value>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.continuous-scheduling-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>10</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>32768</value>
<description>
Maximum limit of memory to allocate to each container request at the Resource Manager.
In MBs.
According to my configuration,yarn.scheduler.maximum-allocation-mb > yarn.nodemanager.resource.memory-mb
</description>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>100</value>
</property>
<!--
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
-->
<!--执行yarn的账号 -->
<!--
<property>
<name>yarn.admin.acl</name>
<value>zdp</value>
</property>
-->
<property>
<name>rpc.engine.org.apache.hadoop.mapred.JobSubmissionProtocol</name>
<value>org.apache.hadoop.ipc.ProtobufRpcEngine</value>
</property>
<property>
<name>yarn.ipc.rpc.class</name>
<value>org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC</value>
</property>
<property>
<name>yarn.client.nodemanager-connect.max-wait-ms</name>
<value>20000</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>97.0</value>
</property>
<!-- 指定nm address端口,containermanager 端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>${yarn.nodemanager.hostname}:65033</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
</configuration>
管理平台
各个组件之间没有统一的 metric 可视化界面,比如说 hdfs 总共占用的磁盘空间、 IO 、运行状况等,. 平台健不健康也不知道。这个时候就需要一个可视化管理平台。
业内常见方案
Ambari
安装部署文档自取
链接:https://pan.baidu.com/s/1CRbKv5H4VdnPgvgJgQcbCg
提取码:18us
特点:
界面如图所示

Cloudera ManagerCloud
提取码:wjfd

CM和Ambari对比如下

自研+开源组件
集群的部署和管理可以基于Ambari二次开发(管理Apache,CDH,HDP都可以)。
监控告警解决方案(cm和Ambari自带的监控粒度不过详细,一般会选择其他监控方案):

Nagios是一个监视系统运行状态和网络信息的监视系统。Nagios能监视所指定的本地或远程主机以及服务,同时提供异常通知功能等


推荐方案:Ambari(管理)+Opeca/Prometheus(自带的界面也没Grafana好看)+Granfana
实时Kafka监控告警
常用组件
kafka monitor

kafka manager

Eagle
管理比较完善,自带监控告警,还带kafka sql

如果想将告警信息统一可以采用如下设计方案。图中监控页面是上述三种组件中的任意一种。

使用开源组件或者自己读取kafka offset的topic进行监控
日志采集
案例:用户行为日志



全流程整体架构如下
调度平台
工作中很多任务需要定时调度最粗暴和简单直接的解决方案就是crontab。当然在机器少,任务不多,定时任务之间关联少的情况下,crontab效率还是比较高和便捷的。 随着集群的增多 ,任务的增多。crontab就开始出现管理混乱的情况,这个时候一个调度平台就非常重要。
业内常见组件
Oozie:
Oozie是一个用于管理Apache Hadoop作业的工作流调度程序系统。对于通用流程调度而言,不是一个非常 好的候选者,因为XML定义对于定义轻 量级作业非常冗长和繁琐。 它还需要相当多的外设设置。 Azkaban是由Linkedin开源的一个批 量工作流任务调度器。用于在一个工 作流内以一个特定的顺序运行一组工 作和流程。 需要通过打zip进行任务调度,任务依赖支持不灵活。
实时数据Sql查询平台
离线数据可以使用hsql或者spaqlsql进行分析出具处理,这对于一些其他部门只需要学习一下sql就可以上手。但是实时需求就非常麻烦需要很多技术栈需要开发人员才能进行分析。
要是能对实时数据进行sql类型的分析那就很棒,工作效率也会变高,学习成本也变低了。目前有开源的工具可以进行二次开发进行使用。

这个开源组件并没有形成产品化,只是提供了工具jar包。使用方式如下。plugins为该组件jar包目录。

要想将该组件产品化,需要搭配web使用,需要设计一个web任务提交保存页面,后端进行解析提交脚本。流程大致如下。

任务诊断

在任务管理平台里面,可以使用任务诊断的功能提出改善意见。


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)