es的使用
ElasticSearch学习笔记
ES是什么
ElasticSearch 是一个高可用开源全文检索和分析的组件,官方解释说它是一个分布式、可扩展、实时的搜索与数据分析引擎。提供存储服务,搜索服务,大数据准实时分析等。一般用于提供一些提供复杂搜索的应用。
为什么要用它
使用es,是因为数据量大的时候,如果所有数据存入关系型数据库,会出现,难以全文检索,效率低,难以完成数据库分析的问题。所以,为了提供查询效率,同时实现全文检索,所以我们采用了ES。
ES主要解决问题
- 全文检索相关数据:
(1) 搜索“UK”应该返回包含“United Kingdom”的相关文档;
(2) 搜索“jump”应该返回包含“JUMP”、“jumped”、“jumps”、“jumping”甚至是“leap”的文档;
(3) 搜索“johnny walker”应该匹配包含“Johnnie Walker”的文档;
-
返回统计结果;
-
速度快;
实现原理
- 存储数据时按有序存储;
- 将数据和索引分离;
- 压缩数据;
ES具体是什么原理
-
首先,排除上面的那种功能定义,我们再对ES进行一个新的定义:ES是一个封装了Lucene的东西,Lucene则是一个高性能的、可扩展的信息检索(IR)工具库(Java库),可以带来很好的查询和全文检索,分析数据功能。但是,它的使用非常复杂,你对数据的增删改查都要你自己手动写代码啥的,完成操作。所以,Elasticsearch就有了可乘之机。ES是一个搜索组件,它可以让用户输入非常简单的restful命令,即可解析为操作Lucene的代码,让它建立起数据库底层的结构和索引。同时,也提供了很好的返回数据展示。
-
ES当中的特殊定义:
-
索引Index:索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。(这个索引结构相当于数据库,其实类似mysql中说的B+树结构构成数据库。本质上,表是抽象出来的,数据的存储在计算机看来,就是存在某种结构里面的。mysql是B+树,但是b+树不好理解,所以对使用者抽象出了”表“这个概念。而ES是索引结构(底层可能是hash,也可能就是b+树,有待了解),只不过它就直接叫索引了,没有称其为表)本质上,索引结构是一种数据结构,它允许对存储在其中的单词进行快速随机访问。
-
类型Type:类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义,所以可以理解为一个表。
-
文档:相当于数据库中的一行数据。文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。
-
域:相当于mysql中的一列。ES的最小查询单位虽然是文档,但是实际索引的时候是对域建立起来的索引树中找文档的。所以,域的值则是真正被搜索的内容。每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。
-
前三者关系:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2gZxhSh9-1621945828027)(C:\Users\lucienpeng\AppData\Roaming\Typora\typora-user-images\image-20210427165630222.png)]
-
-
ES当前的一些策略:
-
分片(Shard)和副本(Replica):ES默认在集群模式会把数据分片到五个机子上面,然后每个分片都有双机热备(就是有副本(Replica shard)是Primary Shard的副本,用于冗余数据及提高搜索性能。)。专业术语来说:ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
-
ES的精确度:就是查询出来的数据,和你搜索的关键词相关程度。参看Rank-k。
-
ES的full-text,全文检索效果:
- 搜索“UK”应该返回包含“United Kingdom”的相关文档;
- 搜索“jump”应该返回包含“JUMP”、“jumped”、“jumps”、“jumping”甚至是“leap”的文档;
- 搜索“johnny walker”应该匹配包含“Johnnie Walker”的文档;
-
全文检索实现原理:为了完成此类full-text域的搜索,ES必须首先分析文本并将其构建成为倒排索引(inverted index),倒排索引由各文档中出现的单词列表组成,列表中的各单词不能重复且需要指向其所在的各文档。(一个set,只不过每个值指向了多个文档)
-
如何创建倒排索引:在文档建立的时候,需要先将各文档中域的值切分为独立的单词(称为term或token),而后将之创建为一个无重复的有序单词列表。这个过程称之为**“分词(tokenization)”**。
倒排索引和分词之间的关系如下:
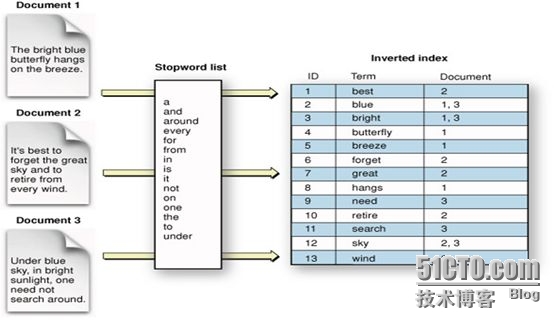
存入的json的各个域被解析为单词,形成一个list,而后每个list的值,又会被存储到倒排索引中,每个索引会指向文档的地址。以此完成全文检索的功能。
-
-
ES插入数据和查询数据的流程:
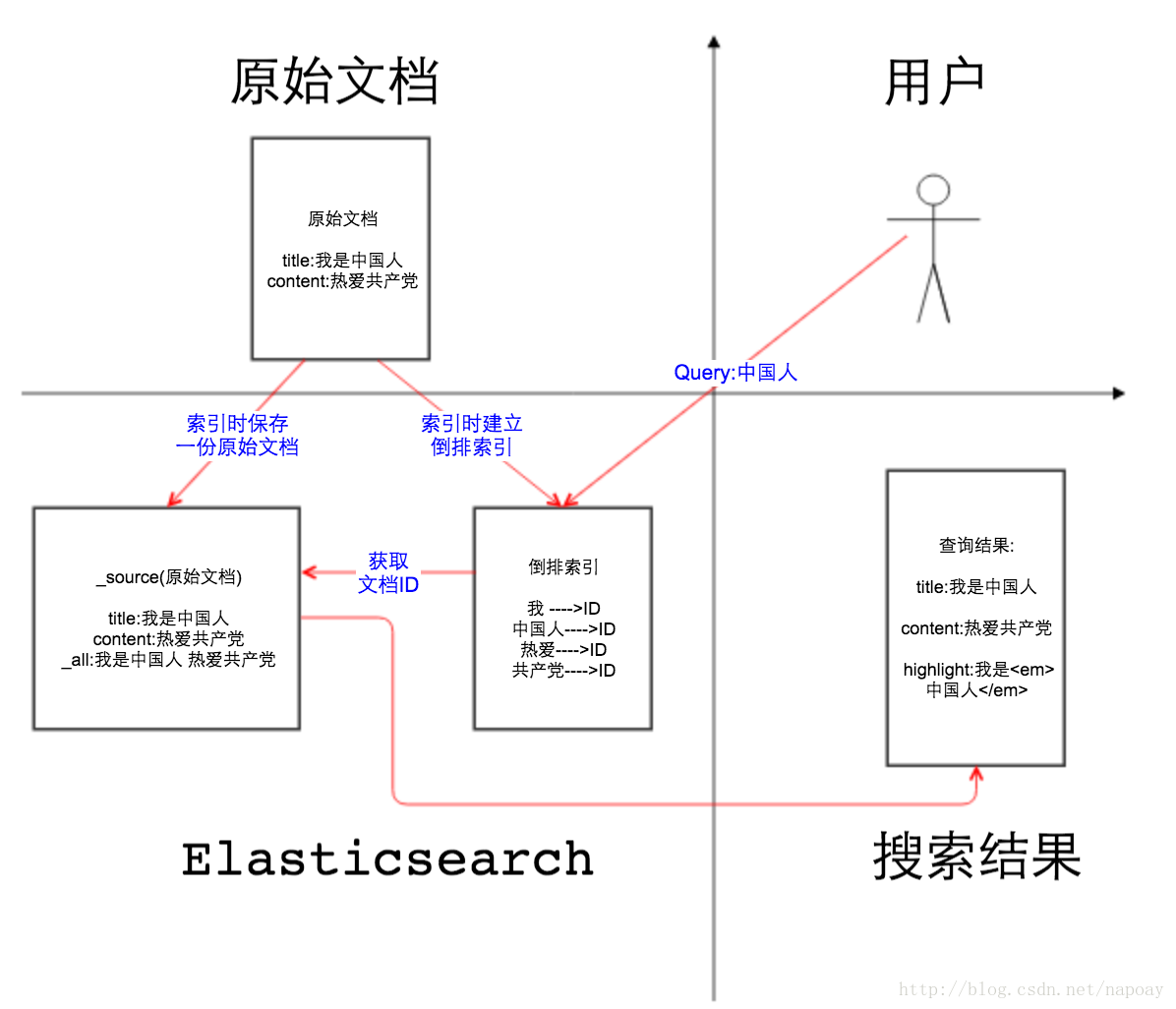
- 插入数据:发送一串数据到es中,es会对数据进行解析,依靠分词形成一个列表,依靠列表再构成倒排索引(如上图)。形成了索引后,再将原有的数据存入到硬盘,完成存储过程。
- 查询数据:例如,用户输入搜索内容“title:elasticsearch”时,则表示搜索“标题”域值中包含单词“elasticsearch”的所有文档。es会去title的倒排索引中查询,找到索引,然后根据指向,找到对应的document,计算精确度,分析一些列的数据,返回给调用者一个结果,json字符串。
- 插入和查询的过程如下图:
要怎么用
使用的一些规范
-
不同的 Type 应该有相似的结构(schema),举例来说,
id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。原因:es中同一个index中不同type是存储在同一个索引中的(lucene的索引文件),因此不同type中相同名字的字段的定义(mapping)必须一致。
强行绕过: _ type字段用来和文档的_ id字段联合生成_ uid字段,所以有着相同_ id的不同类型的文档可以存在同一个索引里。
了解了原理以后,那么我们就开始实际操作了。
实际操作
es7以后很多东西变了,想要详细了解操作,可以直接看:
- restful请求:http://blog.itpub.net/29715045/viewspace-2653369/
- kibana使用:https://www.cnblogs.com/chenqionghe/p/12503181.html?utm_source=tuicool&utm_medium=referral
- kibana使用,腾讯版本:https://cloud.tencent.com/document/product/845/19541
-
es7版本的基本增删改查:
//创建index //1.插入数据的时候,如果没有指定的index,自动创建,并且格式mapping也建立好来了 PUT student/_doc/1 { "name":"star.mai", "age":30, "interest":["football","elec-game"] } //1.2 简单创建index,没有结构那种 PUT /customer?pretty //2. 删除index //3 查询所有的index GET /_cat/indices?v //创建type结构(_doc) put /test { "mappings":{ "properties":{ "name":{"type":"text"}, "age":{"type":"long"}, "birthday":{"type":"date"} } } } //插入数据到index //1 指定id的插入方式,此时如果已有数据,就是修改了 POST movie/_doc/1 { "name":"Titanic", "type":"romance", "country":"America", "director":"James", "date":"1997-12-19" } //2 不指定id的方式 POST movie/_doc { "name":"lulu", "type":"romance", "country":"America", "director":"James-Cameron", "date":"1997-2-19" } //批量插入 POST _bulk { "index" : { "_index" : "weibo" } } {"user":"飞飞是大王","message":"今天天气真好!","city":"北京","country":"中国","province":"北京","uid":1,"address":"中国北京市朝阳区","location":{"lat":"39.970798","lon":"116.325747"}} { "index" : { "_index" : "weibo" } } {"user":"小不小图图","message":"好想喝奶茶~","city":"北京","country":"中国","province":"北京","uid":2,"address":"中国北京市朝阳区","location":{"lat":"39.9904313","lon":"116.412754"}} { "index" : { "_index" : "weibo" } } {"user":"勤劳的小蜜蜂","message":"又是充实的一天!","city":"北京","country":"中国","province":"北京","uid":3,"address":"中国北京市海淀区","location":{"lat":"39.893801","lon":"116.408986"}} { "index" : { "_index" : "weibo" } } {"user":"炸鸡狂热爱好者","message":"今天的炸鸡安排上了","city":"北京","country":"中国","province":"北京","uid":4,"address":"中国北京市东城区","location":{"lat":"39.718256","lon":"116.367910"}} { "index" : { "_index" : "weibo" } } {"user":"电影试探员","message":"李安的双子杀手超赞!","city":"北京","country":"中国","province":"北京","uid":5,"address":"中国北京市通州区","location":{"lat":"39.918256","lon":"116.467910"}} //修改数据 //1. 根据指定id,进行覆盖的修改方式。 POST movie/_doc/1 { "name":"Titanic", "type":"romance", "country":"America", "director":"James-Cameron", "date":"1997-12-19" } //2. _update指令来修改特定字段的方式 POST movie/_update/2 { "doc": { "director":"Luc-Besson" } } //3. 根据特定查询条件找到数据再修改:通过name=“Forrest Gump”的条件来更新director字段信息(可能是批量的) POST movie/_update_by_query { "script":{ "lang": "painless", "source": "ctx._source.director = params.director;", "params":{ "director": "Robert-Zemeckis" } }, "query":{ "match":{ "name": "Forrest Gump" } } } //删除数据 //1.根据id删除数据 DELETE movie/_doc/1 //查询 //1. 查询数据Byid get movie/_doc/1 //2. 查询所有index内的数据 GET movie/_search //3. 查询所有数据,并按照日期降序排列 GET movie/_search { "query": { "match_all": {} }, "sort": [ { "date": { "order": "desc" } } ] } //4. 模糊匹配特定字段 GET movie/_search //模糊查询匹配name为“Titanic”的数据 { "query": { "match": { "name": "Titanic" } } } //5. 精准查询 //只匹配leon字段 GET movie/_search { "query": { "match_phrase": { "name": "leon" } } } GET movie/_search { "query": { "bool": { "filter": { "terms": { "date": [ "1994-09-14" ] } } } } } //6.多字段匹配查询 感觉比较少用(name和sex都包含女的数据)。 GET people/_search { "query": { "multi_match": { "query": "女", "fields": ["name","sex"] } } } //7. 字段级别查询 sex为男或女的数据。由此可以指导,数组内放的数据都是or的关系 GET people/_search { "query": { "terms": { "sex": [ "男", "女" ] } } } //8. 时间的范围查询 GET movie/_search { "query": { "range": { "date": { "gte": "1995-01-01", "lte": "2000-01-01" } } } } //8. or查询 查询name为"leon"或type为“romance”的数据 GET movie/_search { "query": { "bool": { "should": [ { "match": { "name": "leon" } }, { "match": { "type": "romance" } } ] } } } //9 and查询:查询name为“leon”并且type为“action”的数据 { "query": { "bool": { "must": [ { "match": { "name": "leon" } }, { "match": { "type": "action" } } ] } } } //10 不等于查询: 查询type不是“romance”的所有数据、 GET movie/_search { "query": { "bool": { "must_not": [ { "match": { "type": "romance" } } ] } } } //11 查询对应数据并且只返回部分数据 GET movie/_search { "query": { "match": { "name": "泰坦尼克号" } } }, "_source":"name" } //12 limit查询实现 GET movie/_search { "query": { "match": { "name": "泰坦尼克号" } } }, "from":0, "size":1 } //13 查找到的数据进行比大小过滤:gt:大于 gte:大于等于 lt:小于 lte:小于等于 //查询姓张的,年龄在10到30之间的人 GET people/_search { "query": { "match": { "name": "张" } }, "filter":{ "range":{ "age":{ "gte":10, "lte":30 } } } } } //14 全文模糊检索,按照输入法的方式,or连接各个输入的词 GET movie/_search { "query": { "match": { "tags": "钱 单身" } } } }注意:
- term查询时条件不会经过分词,而text类型的属性会被分词存储在索引中,所以只有当值为"hi"时能走索引,查询到结果
- 类型为keyword类型的属性,不会经过分词,match查询时条件会经过分词,所以只能当值为原值"hi single dog"时能查询到。
-
老版本的基本的增删改查
- index的增删改查操作:
//新建一个名叫weather的 Index。 curl -X PUT 'localhost:9200/weather' (PUT /weather?pretty) PUT twitter { "settings" : { "index" : { "number_of_shards" : 3, "number_of_replicas" : 2 } } } //返回结果 { "acknowledged":true, "shards_acknowledged":true } //删除这个 Index。 curl -X DELETE 'localhost:9200/weather' //查看当前所有的index curl -X GET 'http://localhost:9200/_cat/indices?v' (GET /_cat/indices?v)- type的增删改查:(现在type已经删除,结构更加简单,都是_ doc代替type,而也可以理解为_ doc就是唯一的type)
//type的查询 curl 'localhost:9200/_mapping?pretty=true' //新建一个type表,位置为accounts/person中 (新版已经废除) curl -X PUT 'localhost:9200/accounts' -d ' { "mappings": { "person": { "properties": { "user": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "desc": { "type": "text", "analyzer": "ik_max_word",//字段文本的分词器,ik_max_word是插件ik提供的 "search_analyzer": "ik_max_word" //搜索词的分词器 } } } } }' //内部包含3个字段,这三个字段都是中文,而且类型都是文本(text),所以需要指定中文分词器,不能使用默认的英文分词器。 //新版一个index只有一个唐渝鹏,叫做_doc curl -X PUT twitter { "mappings": { "_doc": { "properties": { "type": { "type": "keyword" }, "name": { "type": "text" }, "user_name": { "type": "keyword" }, "email": { "type": "keyword" }, "content": { "type": "text" }, "tweeted_at": { "type": "date" } } } } } //删除这个Type,其实是一次性删除Type下的所有数据内容。type依然残留 curl -X POST 'localhost:9200/accounts/person/_delete_by_query?conflicts=proceed' -d ' { "query": { "match_all": {} } }'- 具体数据的增删改查:
//插入 //插入一个数据到index的type中。最后的1是该条记录的 Id。 $ curl -X PUT 'localhost:9200/accounts/person/1' -d ' { "user": "张三", "title": "工程师", "desc": "数据库管理" }' //_doc代替了具体的type (curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d' { "name": "John Doe" } ') //返回结果: { "_index":"accounts", "_type":"person", "_id":"1", "_version":1, "result":"created", "_shards":{"total":2,"successful":1,"failed":0}, "created":true } //插入数据的时候,也可以不指定 Id,这时要改成 POST 请求 curl -X POST 'localhost:9200/accounts/person' -d ' { "user": "李四", "title": "工程师", "desc": "系统管理" }' //返回结果:id是一个随机值AV3qGfrC6jMbsbXb6k1p { "_index":"accounts", "_type":"person", "_id":"AV3qGfrC6jMbsbXb6k1p", "_version":1, "result":"created", "_shards":{"total":2,"successful":1,"failed":0}, "created":true } //查询 //查询ById curl 'localhost:9200/accounts/person/1?pretty=true' (curl -X GET "localhost:9200/customer/_doc/1?pretty") //返回结果: { "_index" : "accounts", "_type" : "person", "_id" : "1", "_version" : 1, "found" : true, //如果 Id 不正确,就查不到数据,found字段就是false。 "_source" : { "user" : "张三", "title" : "工程师", "desc" : "数据库管理" } } //查询Type中所有数据 $ curl 'localhost:9200/accounts/person/_search' (GET /accounts/_search?q=*&sort=name:asc&pretty)//不需要_doc了 //返回结果 { "took":2, "timed_out":false, "_shards":{"total":5,"successful":5,"failed":0}, "hits":{ //hits字段表示命中的记录,max_score是匹配程度 "total":2, "max_score":1.0, "hits":[ { "_index":"accounts", "_type":"person", "_id":"AV3qGfrC6jMbsbXb6k1p", "_score":1.0, "_source": { "user": "李四", "title": "工程师", "desc": "系统管理" } }, { "_index":"accounts", "_type":"person", "_id":"1", "_score":1.0, "_source": { "user" : "张三", "title" : "工程师", "desc" : "数据库管理,软件开发" } } ] } } //查询By某些字段:-d后面加上如下格式的body就可以了 curl 'localhost:9200/accounts/person/_search' -d ' { "query" : { "match" : { "desc" : "软件" }} , //使用 Match 查询,指定的匹配条件是desc字段里面包含"软件"这个词。 "size": 1 // Elastic 默认一次返回10条结果,可以通过size字段改变这个设置。还可以通过from字段,指定位移,从而实现分页查询 }' //返回数据 { "took":3, "timed_out":false, "_shards":{"total":5,"successful":5,"failed":0}, "hits":{ "total":1, "max_score":0.28582606, "hits":[ { "_index":"accounts", "_type":"person", "_id":"1", "_score":0.28582606, "_source": { "user" : "张三", "title" : "工程师", "desc" : "数据库管理,软件开发" } } ] } } //查询的逻辑运算,即:and,or //or查询 curl 'localhost:9200/accounts/person/_search' -d ' { "query" : { "match" : { "desc" : "软件 系统" }} //空格间隔开来,就表示or }' //and查询 curl 'localhost:9200/accounts/person/_search' -d ' { "query": { "bool": { //and搜索,必须使用布尔查询。 "must": [ { "match": { "desc": "软件" } }, { "match": { "desc": "系统" } } ] } } }' //删除 curl -X DELETE 'localhost:9200/accounts/person/1' //更新 //更新记录就是使用 PUT 请求,重新发送一次数据。 curl -X PUT 'localhost:9200/accounts/person/1' -d ' { "user" : "张三", "title" : "工程师", "desc" : "数据库管理,软件开发" }' //返回结果:记录的 Id 没变,但是版本(version)从1变成2,操作类型(result)从created变成updated,created字段变成false,因为这次不是新建记录。 { "_index":"accounts", "_type":"person", "_id":"1", "_version":2, "result":"updated", "_shards":{"total":2,"successful":1,"failed":0}, "created":false }-
查询所有的type
curl 'localhost:9200/_mapping?pretty=true' -
配置一些特殊的查询:
- _ index属性的用法:插入的时候,不是所有的域都会建立索引的,默认是建立索引,但是你发送的json字符串,是可以指定index的属性的。analyzed:是先分词,再建立索引;not_analyzed:是直接原样建立索引;no:是不建立索引。如果没有建立索引,自然就无法被查询了。这个要注意。
- 例子:设置test索引不保存_source,title字段索引但不分析,字段原始值写入索引,content字段为默认属性
DELETE test
PUT test
PUT test/test/_mapping
{
"test": {
"_source": {
"enabled": false
},
"properties": {
"title": {
"type": "string",
"index": "not_analyzed",
"store": "true"
},
"content": {
"type": "string"
}
}
}
}
- _ source字段的用法:该字段默认是存储的,禁用_ source以后查询结果中不会再返回文档原始内容
//禁用的情况
PUT test/test/_mapping
{
"test": {
"_source": {
"enabled": false
}
}
}POST test/test/1 { "title":"我是中国人", "content":"热爱" }
//返回数据没有字段了
GET test/_search
{
"query": {
"match": {
"title": "中国人"
}
}
}
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.30685282,
"hits": [
{
"_index": "test",
"_type": "test",
"_id": "1",
"_score": 0.30685282
}
]
}
}
//当存储的数据太大的时候,我们可以对一些不需要的数据进行禁用,以减少存储消耗。
//可以排除部分大的字段,让他们不会被存储,也不会建立倒排索引
{
"yourtype":{
"_source":{
"includes":["field1","field2"] //包括某些字段
"excludes":["field1","field2"] //排除某些字段:
},
"properties": {
...
}
}
}
- _ all字段的用法:默认是关闭的,如果要开启_all字段,索引增大是不言而喻的。它开启后,将会把传入的所有域合为一个大的域,再进行分词之类的。用于实现文档的搜索,而不是一个域的搜索(相当于一行数据有字段就查出来,而不是针对某一列进行筛选)
//开启all
"yourtype": {
"_all": {
"enabled": true
},
"properties": {
...
}
}
}
POST test/test/1 { "title":"我是中国人", "content":"热爱" }
//对_all字段进行搜索并高亮:
POST test/_search
{
"fields": ["_all"],
"query": {
"match": {
"_all": "中国人"
}
},
"highlight": {
"fields": {
"_all": {}
}
}
}
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.15342641,
"hits": [
{
"_index": "test",
"_type": "test",
"_id": "1",
"_score": 0.15342641,
"_all": "我是中国人 热爱 ",
"highlight": {
"_all": [
"我是<em>中国人</em> 热爱 "
]
}
}
]
}
}
//指定哪些字段合并为一个大域
{
"yourtype": {
"properties": {
"field1": {
"type": "string",
"include_in_all": false
},
"field2": {
"type": "string",
"include_in_all": true
}
}
}
}
- Elasticsearch中的query_string和simple_query_string默认就是查询_all字段,示例如下:
GET test/_search
{
"query": {
"query_string": {
"query": "公公公"
}
}
}
会怎么
可以实现快速查询,全文检索。
参考

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)