Kafka集群详解(一)
kafka特性:1、kafka的数据只会顺序append,不支持随机写,顺序读写的性能非常高效2、数据的删除策略是累积到一定程度或者超过一定时间再删除 (默认是7天)3、Kafka另一个独特的地方是将消费者信息保存在客户端而不是MQ服务器 (zookeeper)4、消息的投递过程也是采用客户端主动pull的模型5、客户端在pull数据的时候,尽量以zero-copy(nio)的方式传输, 利用se
kafka特性:
1、kafka的数据只会顺序append,不支持随机写,顺序读写的性能非常高效
2、数据的删除策略是累积到一定程度或者超过一定时间再删除 (默认是7天)
3、Kafka另一个独特的地方是将消费者信息保存在客户端而不是MQ服务器 (zookeeper)
4、消息的投递过程也是采用客户端主动pull的模型
5、客户端在pull数据的时候,尽量以zero-copy(nio)的方式传输, 利用sendfile(对应java里的 FileChannel.transferTo/transferFrom)这样的高级IO函数来减少拷贝开销

Kafka存储策略
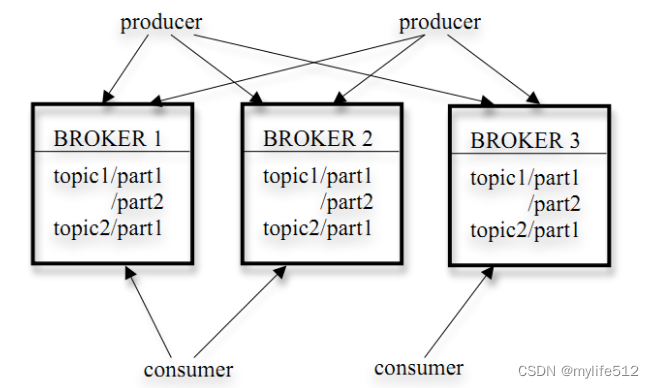
1. kafka以topic来进行消息管理,每个topic包含多个part(ition),每个part对应一个逻辑log,有多个segment组成。
2. 每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
3. 每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
4. 发布者发到某个topic的消息会被均匀的分布到多个part上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应part的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)