kafka Java客户端之consumer 流量控制 以及 Rebalance解析
Consumer 流量控制为了避免Kafka中的流量剧增导致过大的流量打到Consumer端将Consumer给压垮的情况,我们就需要针对Consumer进行限流。例如,当处理的数据量达到某个阈值时暂停消费,低于阈值时则恢复消费,这就可以让Consumer保持一定的速率去消费数据,从而避免流量剧增时将Consumer给压垮。大体思路如下:在poll到数据之后,先去令牌桶中拿取令牌如果获取到令牌,则
Consumer 流量控制
为了避免Kafka中的流量剧增导致过大的流量打到Consumer端将Consumer给压垮的情况,我们就需要针对Consumer进行限流。例如,当处理的数据量达到某个阈值时暂停消费,低于阈值时则恢复消费,这就可以让Consumer保持一定的速率去消费数据,从而避免流量剧增时将Consumer给压垮。
还有的情况就是一个消费者分配了多个分区,并同时消费所有的分区,这些分区具有相同的优先级。在一些情况下,消费者需要首先消费一些指定的分区,当指定的分区有少量或者已经没有可消费的数据时,则开始消费其他分区。
例如流处理,当处理器从2个topic获取消息并把这两个topic的消息合并,当其中一个topic长时间落后另一个,则暂停消费,以便落后的赶上来。
kafka支持动态控制消费流量,分别在future的poll(long)中使用pause(Collection) 和 resume(Collection) 来暂停消费指定分配的分区,重新开始消费指定暂停的分区。
结合令牌桶来对kafka consumer实现限流:
- 在poll到数据之后,先去令牌桶中拿取令牌
- 如果获取到令牌,则继续业务处理
- 如果获取不到令牌,则调用pause方法暂停Consumer,等待令牌
- 当令牌桶中的令牌足够,则调用resume方法恢复Consumer的消费状态
接下来编写具体的代码案例简单演示一下这个限流思路,令牌桶算法使用Guava里内置的,所以需要在项目中添加对Guava的依赖。单机限流可以直接使用 Google Guava 自带的限流工具类 RateLimiter 。 RateLimiter 基于令牌桶算法,可以应对突发流量。
除了最基本的令牌桶算法(平滑突发限流)实现之外,Guava 的RateLimiter还提供了 平滑预热限流 的算法实现。 平滑突发限流就是按照指定的速率放令牌到桶里,而平滑预热限流会有一段预热时间,预热时间之内,速率会逐渐提升到配置的速率。
添加的依赖项如下:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
<!-- or, for Android: -->
<!-- <version>31.0.1-android</version>-->
</dependency>
然后我们就可以使用Guava的限流器对Consumer进行限流了,测试代码如下
/*
流量控制 - 限流
*/
private static void controlPause() {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "81.68.82.48:9092");
properties.setProperty("group.id", "groupxt");
properties.setProperty("enable.auto.commit", "false");
properties.setProperty("auto.commit.interval.ms", "1000");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer(properties);
TopicPartition p0 = new TopicPartition(TOPIC_NAME, 0);
TopicPartition p1 = new TopicPartition(TOPIC_NAME, 1);
TopicPartition p2 = new TopicPartition(TOPIC_NAME,2);
/*** 令牌生成速率,单位为秒 */
//分别控制每个partition的消费速度
final int permitsPerSecond1 = 5;
final int permitsPerSecond2 = 3;
final int permitsPerSecond3 = 6;
/*** 限流器 */
final RateLimiter LIMITER = RateLimiter.create(permitsPerSecond1);
final RateLimiter LIMITER2 = RateLimiter.create(permitsPerSecond2);
final RateLimiter LIMITER3 = RateLimiter.create(permitsPerSecond3);
// 消费订阅某个Topic的某个分区或多个
consumer.assign(Arrays.asList(p0,p1,p2));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));
//如果没有拉取到消息,重新拉取
if (records.isEmpty()) {
continue;
}
// 每个partition单独处理
for(TopicPartition partition : records.partitions()){
List<ConsumerRecord<String, String>> pRecord = records.records(partition);
for (ConsumerRecord<String, String> record : pRecord) {
//执行业务操作,consumer 拉取消息会堵塞在此处,要等其他业务处理完这些消息,consumer才会拉取下一批消息
System.out.printf("patition = %d , offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
/*
1、接收到record信息以后,去令牌桶中拿取令牌
2、如果获取到令牌,则继续业务处理
3、如果获取不到令牌, 则pause等待令牌
4、当令牌桶中的令牌足够, 则将consumer置为resume状态
*/
// 限流partition 0
if (!LIMITER.tryAcquire()) {
System.out.println("无法获取到p0令牌,暂停消费p0");
consumer.pause(Arrays.asList( p0));
} else {
System.out.println("获取到p0令牌,恢复消费p0");
consumer.resume(Arrays.asList(p0));
}
// 限流partition 1
if (!LIMITER2.tryAcquire()) {
System.out.println("无法获取到p1令牌,暂停消费p1");
consumer.pause(Arrays.asList(p1));
} else {
System.out.println("获取到p1令牌,恢复消费p1");
consumer.resume(Arrays.asList(p1));
}
// 限流partition 2
if (!LIMITER3.tryAcquire()) {
System.out.println("无法获取到p2令牌,暂停消费p2");
consumer.pause(Arrays.asList(p2));
} else {
System.out.println("获取到p2令牌,恢复消费p2");
consumer.resume(Arrays.asList(p2));
}
}
long lastOffset = pRecord.get(pRecord.size() -1).offset();
// 单个partition中的offset,并且进行提交
Map<TopicPartition, OffsetAndMetadata> offset = new HashMap<>();
offset.put(partition,new OffsetAndMetadata(lastOffset+1));
// 提交offset
consumer.commitSync(offset);
System.out.println("=============partition - "+ partition +" end================");
}
}
}
也可以使用其他一些限流的库,比如 Bucket4j 是一个非常不错的基于令牌/漏桶算法的限流库。 相对于,Guava 的限流工具类来说,Bucket4j 提供的限流功能更加全面。不仅支持单机限流和分布式限流,还可以集成监控,搭配 Prometheus 和 Grafana 使用。 不过,毕竟 Guava 也只是一个功能全面的工具类库,其提供的开箱即用的限流功能在很多单机场景下还是比较实用的。
Spring Cloud Gateway 中自带的单机限流的早期版本就是基于 Bucket4j 实现的。后来,替换成了 Resilience4j。 Resilience4j 是一个轻量级的容错组件,其灵感来自于 Hystrix。自Netflix 宣布不再积极开发 Hystrix (opens new window) 之后,Spring 官方和 Netflix 都更推荐使用 Resilience4j 来做限流熔断。
一般情况下,为了保证系统的高可用,项目的限流和熔断都是要一起做的。 Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重试等保障系统高可用开箱即用的功能。并且,Resilience4j 的生态也更好,很多网关都使用 Resilience4j 来做限流熔断的。 因此,在绝大部分场景下 Resilience4j 或许会是更好的选择。如果是一些比较简单的限流场景的话,Guava 或者 Bucket4j 也是不错的选择。
分布式限流
分布式限流常见的方案:
- 借助中间件架限流 :可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
- 网关层限流 :比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现RedisRateLimiter就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
如果你要基于 Redis 来手动实现限流逻辑的话,建议配合 Lua 脚本来做。 网上也有很多现成的脚本供你参考,就比如 Apache 网关项目 ShenYu 的 RateLimiter 限流插件就基于 Redis + Lua 实现了令牌桶算法/并发令牌桶算法、漏桶算法、滑动窗口算法。
Consumer 消费控制
上面讲到了kafka的流量控制,避免拉取过多的消息而导致服务被压崩。但是有时候我们需要及时迅速的消费掉生产者生产的消息,避免造成消费积压问题。那应该怎么做呢?
消费太慢
增加Topic的分区数,并且同时提升消费组的消费者数量,然后多线程消费消息从而提升消费速度,消费者最多的时候可以一个消费者消费一个分区
消费太快
可以采用上面的令牌桶等限流的方法,也可以调整kafka自己的参数
调整参数:
- fetch.max.bytes:单次获取数据的最大消息数。
- max.poll.records <= 吞吐量 :单次poll调用返回的最大消息数,如果处理逻辑很轻量,可以适当提高该值。默认值为500
一次从kafka中poll出来的数据条数,max.poll.records条数据需要在在session.timeout.ms这个时间内处理完
consumer.poll(1000)
新版本的Consumer的Poll方法使用了类似于Select I/O机制,因此所有相关事件(包括reblance,消息获取等)都发生在一个事件循环之中。
1000是一个超时时间,一旦拿到足够多的数据(参数设置),consumer.poll(1000)会立即返回 ConsumerRecords<String, String> records。
如果没有拿到足够多的数据,会阻塞1000ms,但不会超过1000ms就会返回。
Consumer Rebalance解析
Consumer有个Rebalance的特性,即重新负载均衡,该特性依赖于一个协调器来实现。每当Consumer Group中有Consumer退出或有新的Consumer加入都会触发Rebalance。
之所以要重新负载均衡,是为了将退出的Consumer所负责处理的数据再重新分配到组内的其他Consumer上进行处理。或当有新加入的Consumer时,将组内其他Consumer的负载压力,重新进均匀分配,而不会说新加入一个Consumer就闲在那。
下面就用几张图简单描述一下,各种情况触发Rebalance时,组内成员是如何与协调器进行交互的。
1、新成员加入组(member join):
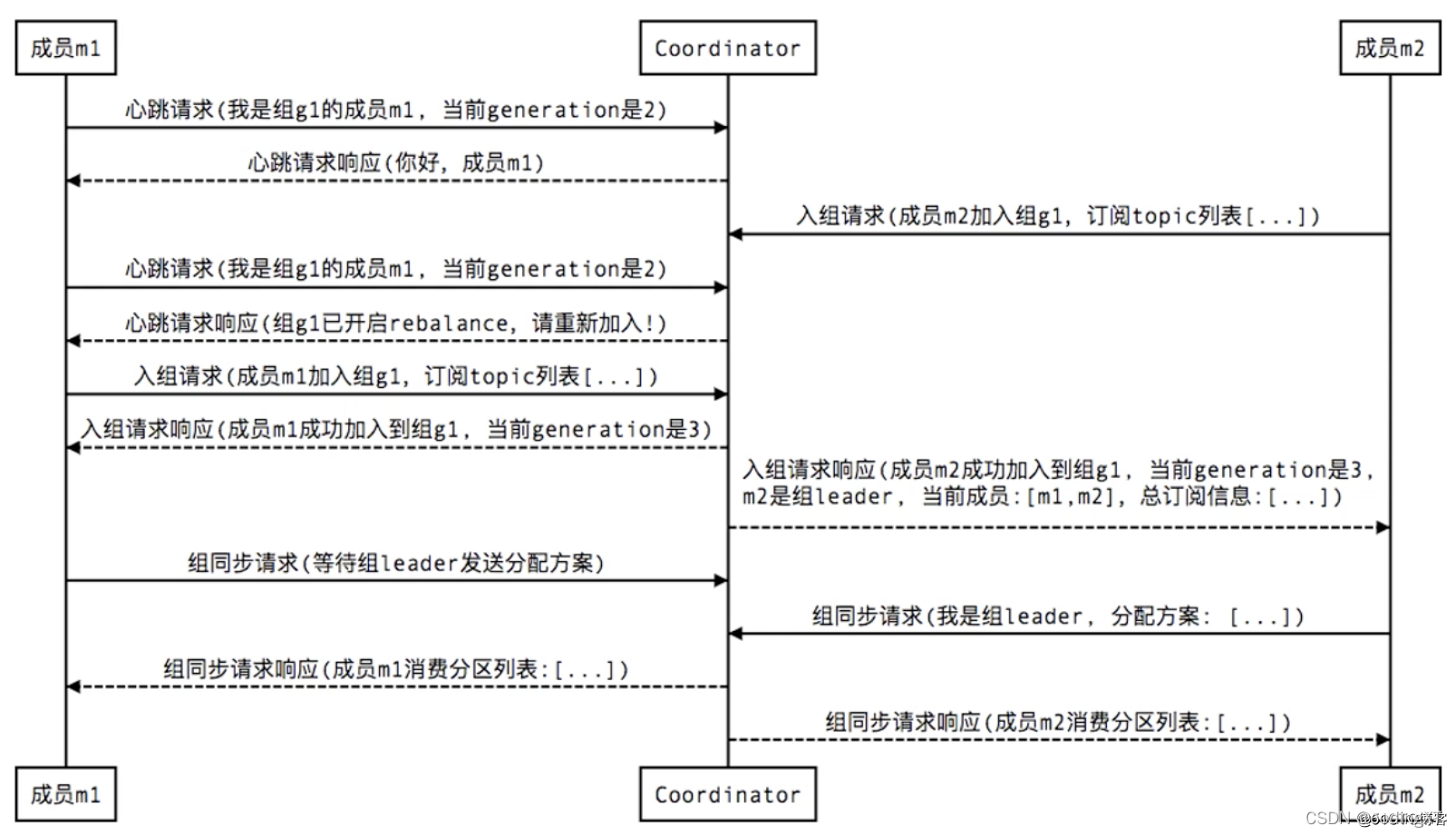
图中的Coordinator是协调器,有新的成员加入的时候,会要求所有成员断开,然后全部进行重连。而generation则类似于乐观锁中的版本号,每当成员入组成功就会更新,也是起到一个并发控制的作用,避免提交offset的脏数据,每次提交offset的时候要带着generation这个版本号,只有版本号对应上了,才认为提交的offset是有效的,才会接收这个提交
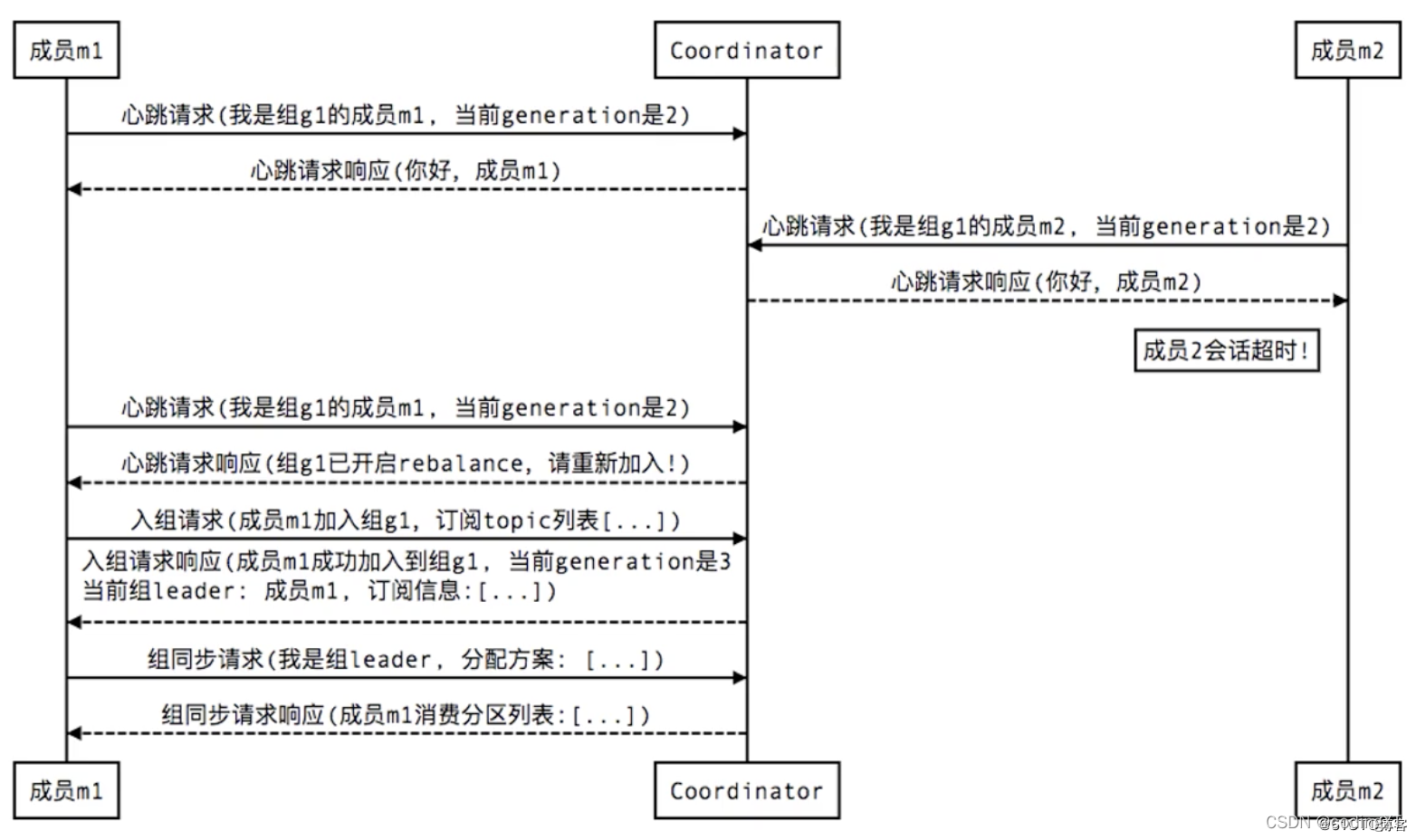
2、组成员崩溃/非正常退出(member failure):
如有有一个consumer宕机了,会重新rebalance一下,重新分配一下partition
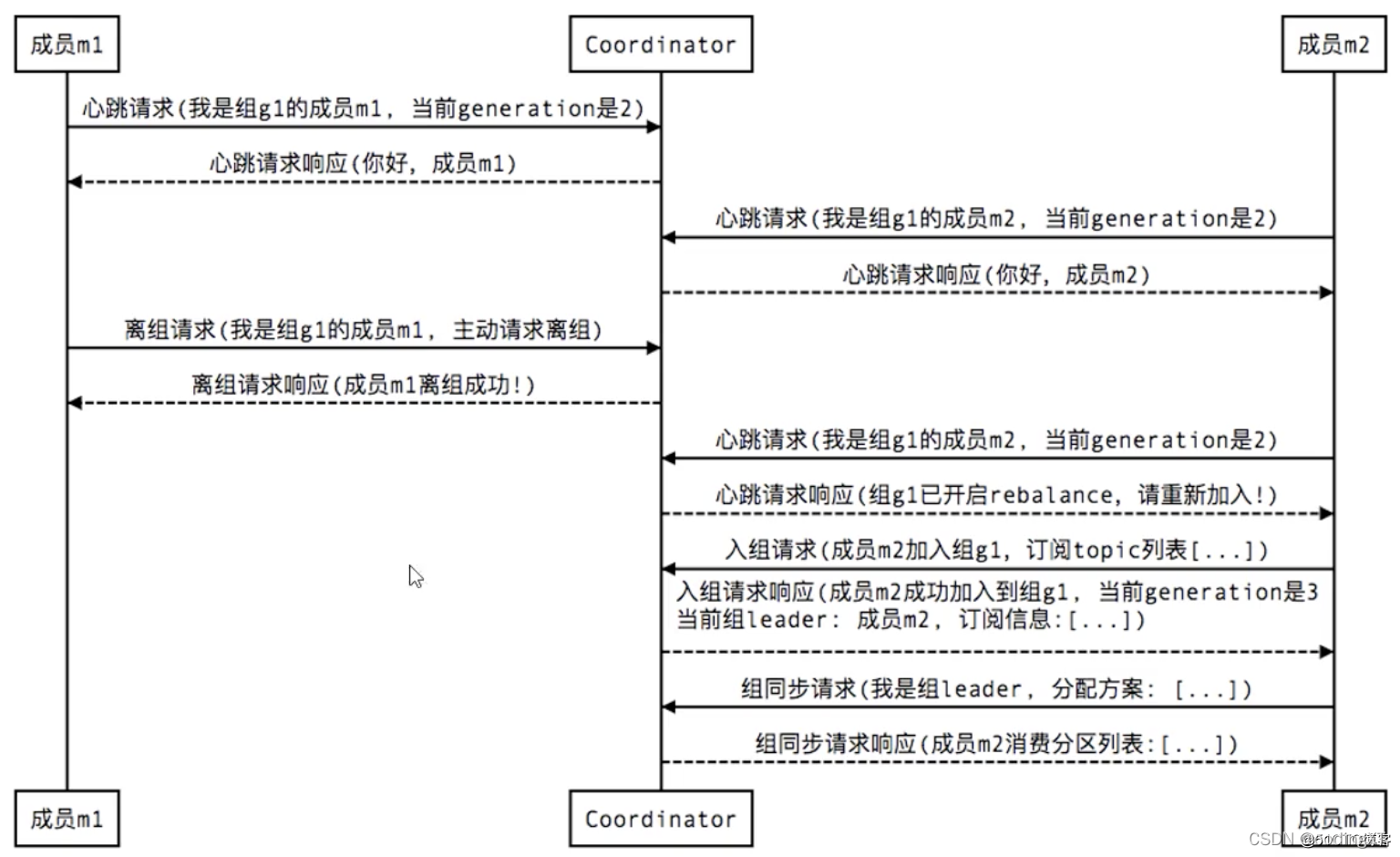
3、组成员主动离组/正常退出(member leave group):
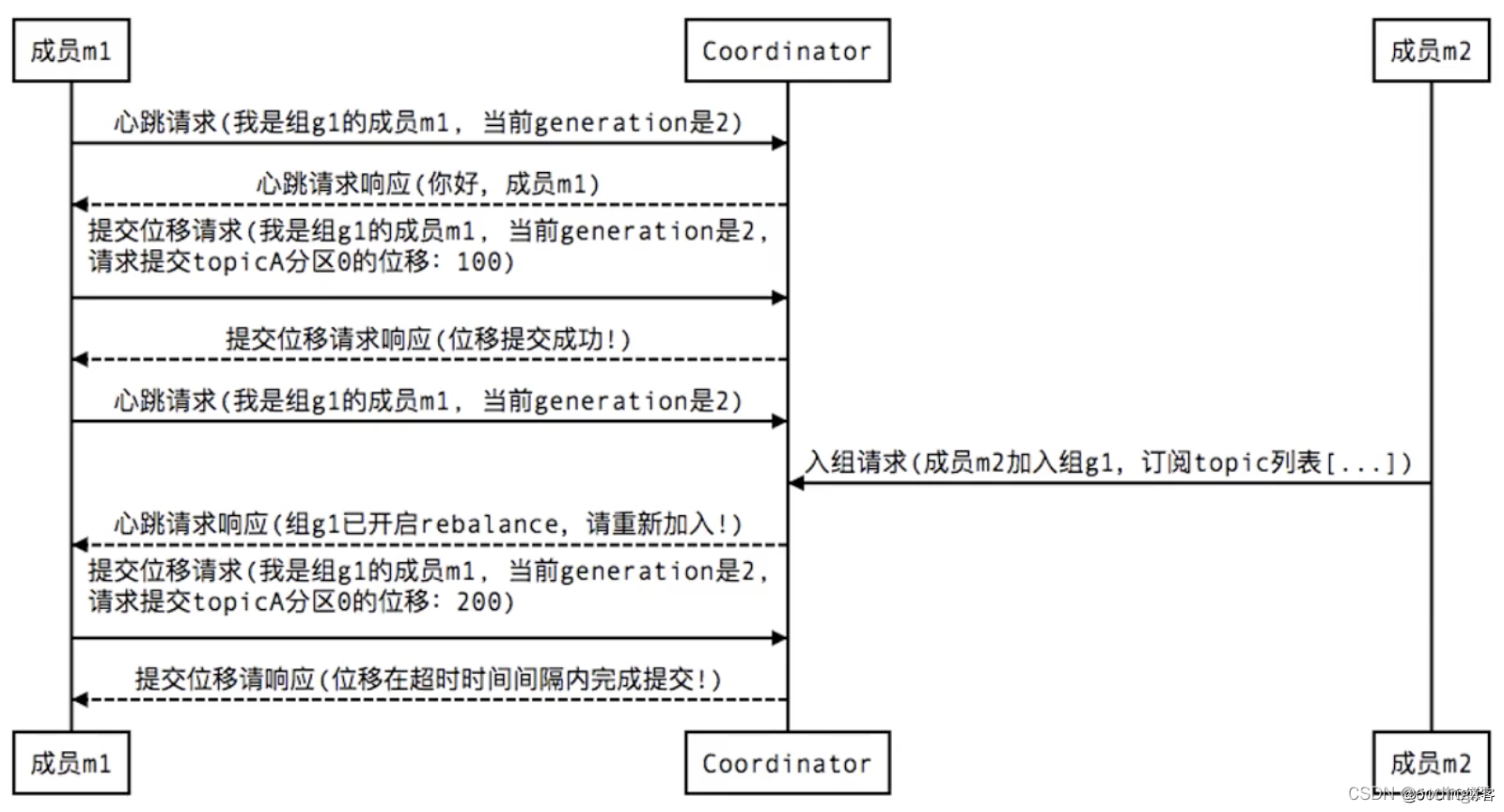
4、当Consumer提交位移(member commit offset)时,也会有类似的交互过程:
如果offset没有提交成功,但是业务又做了,可能就会导致重复消费问题
References:
- https://javaguide.cn/high-availability/limit-request/
- https://www.orchome.com/451#item-9
- https://blog.csdn.net/weixin_33797791/article/details/88003844?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase
- https://blog.51cto.com/zero01/2498017
- https://www.cnblogs.com/yangxusun9/p/13049132.html
(写博客主要是对自己学习的归纳整理,资料大部分来源于书籍、网络资料和自己的实践,整理不易,但是难免有不足之处,如有错误,请大家评论区批评指正。同时感谢广大博主和广大作者辛苦整理出来的资源和分享的知识。)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)