第四章 kafka专题之kafka文件详细描述(最全)
kafka文件概述(最全)
1、kafka文件概述
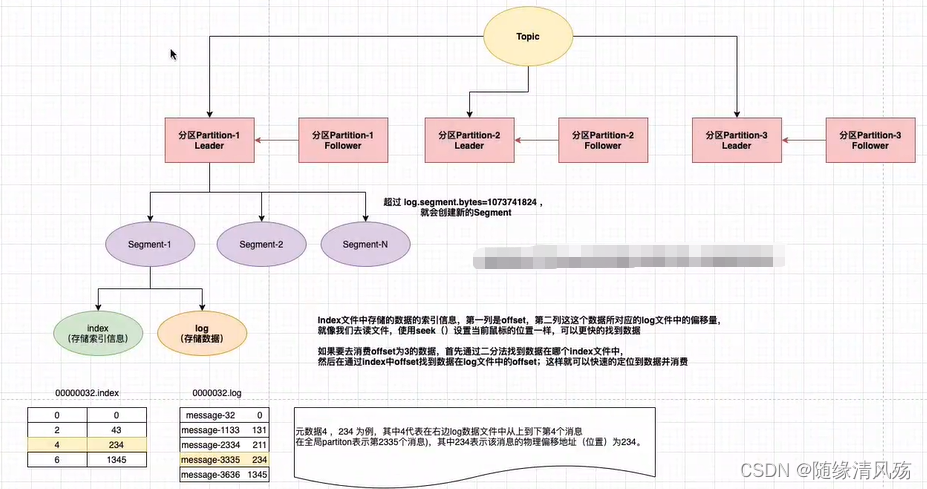
- 路径查看:server.properties中的log.dirs
(1)文件目录命名:topic-partition

(2)四个topic相关文件:
- .log:数据文件
- .index:索引文件
- .timeindex:时间索引文件
- leader-epoch-checkpoint:

(3)offset相关目录

2、Partition
- topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列

- 以文件夹的形式存储在具体Broker上
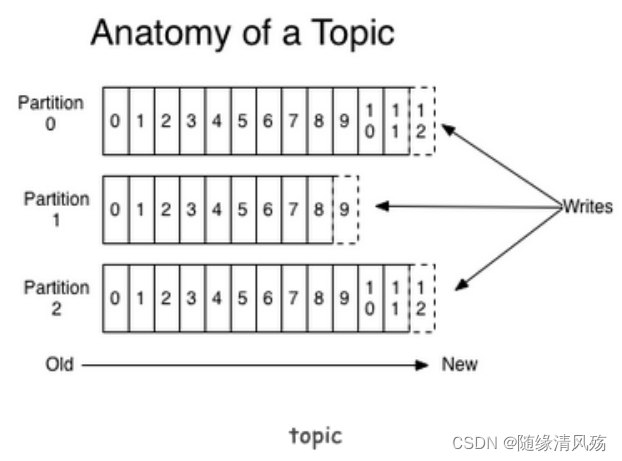
(1)每个 Parition 都会有个序号, 序号从 0 开始
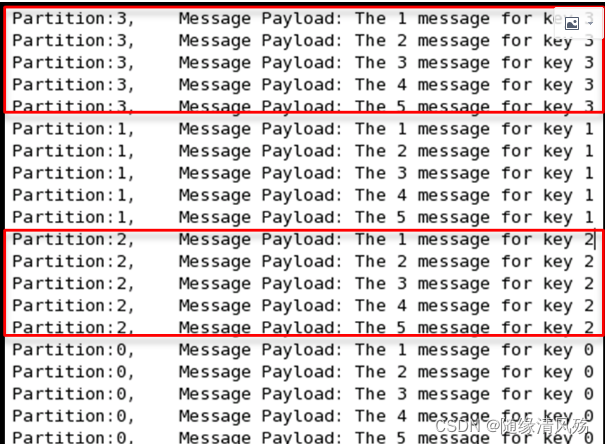
(2) key 相同的消息会被发送并存储到同一个 partition 里,而且 key 的序号正好和 Partition 序号相同。
3、Segment
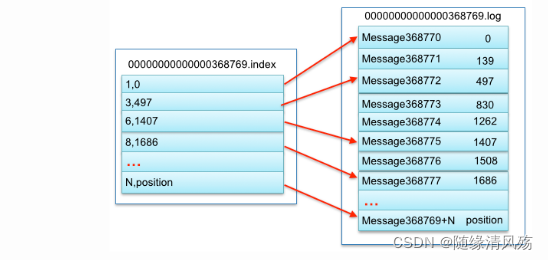
- 每个Partition由多个Segment file组成,Segment file由index文件和log文件组成。
- 逻辑组成

- 物理存储

- segment中index<—->data file对应关系物理结构如下
4、Offset
- partition的每个消息都有一个连续的序号叫做offset,用于partition唯一标识一条消息。
5、log entriex序列
(1)物理存储的表现形式
每个日志文件都是一个 log entrie 序列,每个 log entrie 包含一个 4 字节整型数值(值为 N+5),1 个字节的 “magic value”,4 个字节的 CRC 校验码,其后跟 N 个字节的消息体。每条消息都有一个当前 Partition 下唯一的 64 字节的 offset,它指明了这条消息的起始位置。磁盘上存储的消息格式如下:
message length : 4 bytes (value: 1+4+n)
"magic" value : 1 byte
crc : 4 bytes
payload : n bytes
(2)这个 log entries 并非由一个文件构成,而是分成多个 segment,每个 segment 以该 segment 第一条消息的 offset 命名并以“.kafka”为后缀。另外会有一个索引文件,它标明了每个 segment 下包含的 log entry 的 offset 范围,如下图所示。
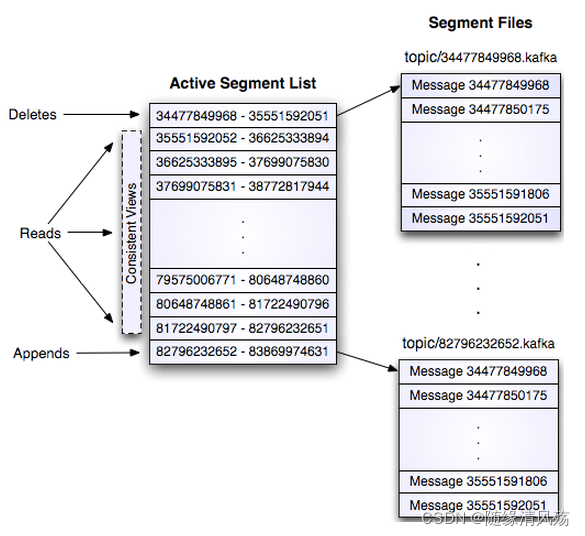
因为每条消息都被 append 到该 Partition 中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是 Kafka 高吞吐率的一个很重要的保证)。
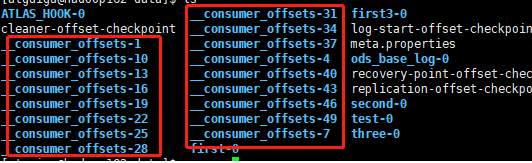
6、__consumer_offsets
- 默认50个分区目录,
- 数据产生: consumer在消费消息后,向broker中有个专门维护每个consumer的offset的topic生产一条消息,记录自己当前已读的消息的offset+1的值作为新的offset的消息
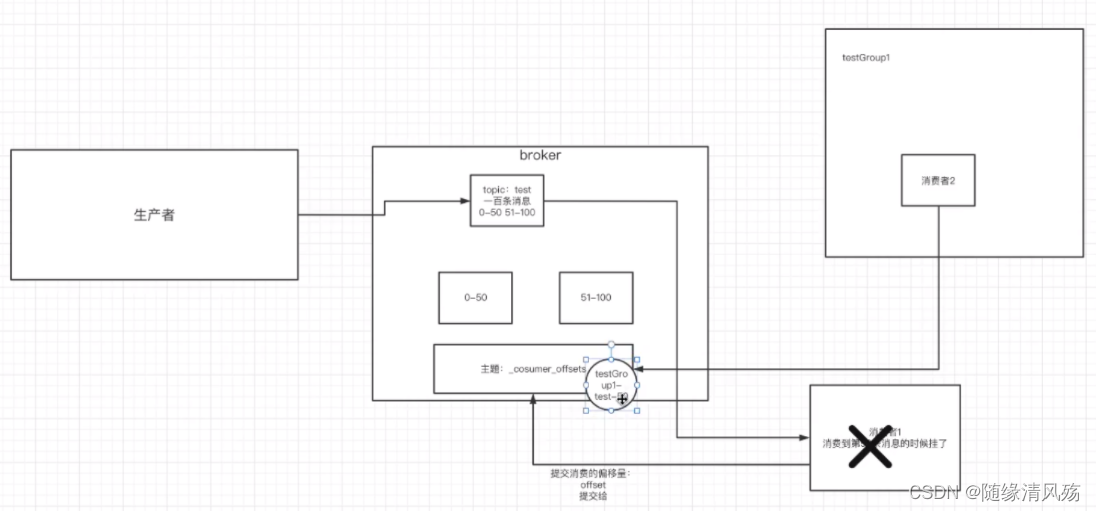
(1)Consumer消费消息后提交消费的偏移量到kafka集群的内部Topic:_consumer_offset
(2)提交格式:
- key = Consumer Group + topic+分区号
- value = offset值
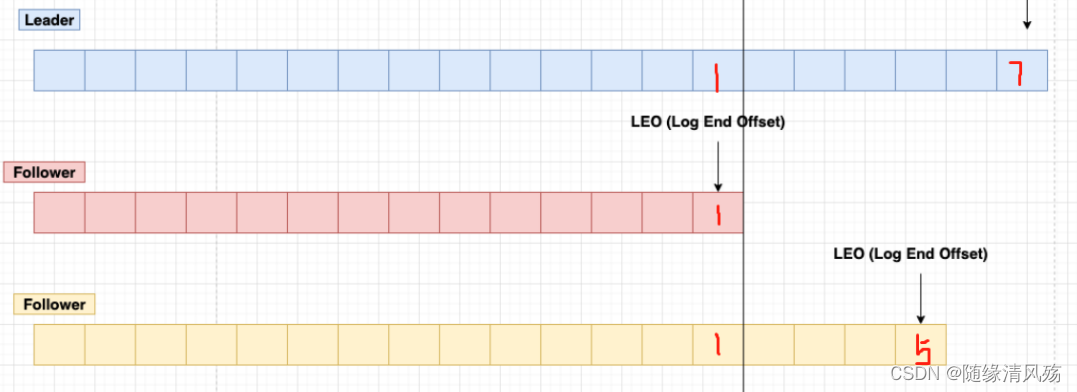
7、LEO&HW
(1)LEO:表示每个partition的log最后一条Message的位置
(2)HW:表示partition各个replicas数据见同步且一致的offset位置
-
如上图说明LEO
- leader的LEO为7
- follower1的LEO为1
- follower2的LEO为5
-
如上图说明HW,HW为1
- 消费者消费消息最多到1,之后的数据对消费者不可见
8、Kafka高效文件存储设计特点
(1)Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
(2)通过索引信息可以快速定位message和确定response的最大大小。
(3)通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
(4)通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)