Elasticsearch生产集群健康状况为yellow原因分析和解决方案
问题描述:ES状态如下图所示,且新产生的日志发送至Elasticsearch失败问题分析:查看es集群的健康状态执行命令curl -X GEThttp://127.0.0.1:9200/_cluster/health -u elastic:nroadelastic,查看集群分片的情况,重点关注unassigned_shards没有正常分配的副本数量,返回信息如下:各返回字段描述:cluster_n
问题描述:
ES状态如下图所示,且新产生的日志发送至Elasticsearch失败

问题分析:
查看es集群的健康状态
执行命令curl -X GET http://127.0.0.1:9200/_cluster/health -u elastic:nroadelastic, 查看集群分片的情况,重点关注unassigned_shards没有正常分配的副本数量,返回信息如下:

各返回字段描述:
cluster_name---集群的名称。
status---集群的运行状况,基于其主要和副本分片的状态。状态为:
– green-所有分片均已分配。
– yellow-所有主分片均已分配,但未分配一个或多个副本分片。如果群集中的某个节点发生故障,则在修复该节点之前,某些数据可能不可用。
– red-未分配一个或多个主分片,因此某些数据不可用。在集群启动期间,这可能会短暂发生,因为已分配了主要分片。
timed_out---如果false响应在timeout参数指定的时间段内返回(30s默认情况下)。
number_of_nodes---集群中的节点数。
number_of_data_nodes---作为专用数据节点的节点数。
active_primary_shards---活动主分区的数量。
active_shards---活动主分区和副本分区的总数。
relocating_shards---正在重定位的分片的数量。
initializing_shards---正在初始化的分片数。
unassigned_shards---未分配的分片数。
delayed_unassigned_shards---其分配因超时设置而延迟的分片数。
number_of_pending_tasks---尚未执行的集群级别更改的数量。
number_of_in_flight_fetch---未完成的访存数量。
task_max_waiting_in_queue_millis---自最早的初始化任务等待执行以来的时间(以毫秒为单位)。
active_shards_percent_as_number—群集中活动碎片的比率,以百分比表示。找到问题索引
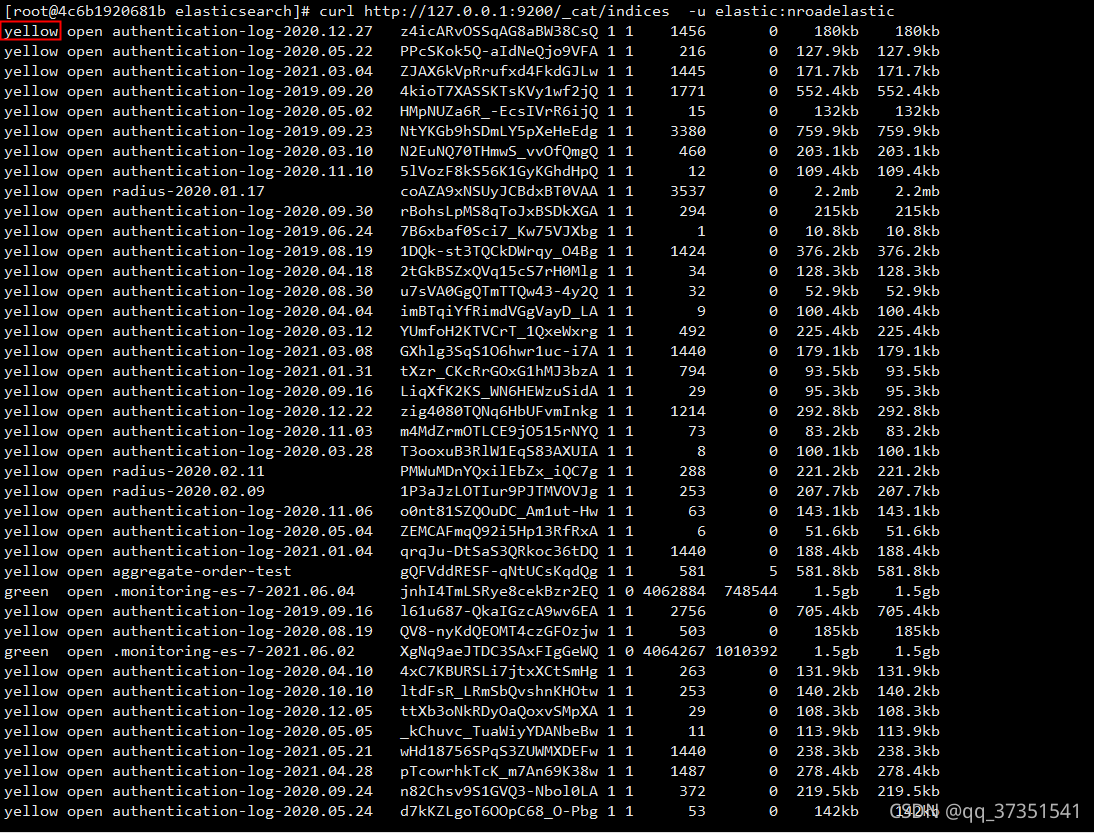
执行命令curl http://127.0.0.1:9200/_cat/indices -u elastic:nroadelastic ,获取所有异常索引(yellow),如图所示:
执行如下命令 curl http://127.0.0.1:9200/_cluster/allocation/explain -u elastic:nroadelastic ,获取索引异常原因:

如图所示,提示异常原因为:unassigned、the shard cannot be allocated to the same node on which a copy of the shard already exists和cannot allocate because allocation is not permitted to any of the nodes,是由于节点丢失导致无法进行副本复制导致的。
问题处理:
查看上述异常索引的settings:
curl http://127.0.0.1:9200/authentication-log-2020.09.02/_settings -u elastic:nroadelastic

当副本数大于或等于数据节点数时,那么每个分片只能最多有节点数量-1个副本,无法分配的副本数则为主分片数*(副本数-(节点数-1)),例如:假设节点数为3,主分片数为5,副本数为3,那么无法分配的副本数则为:5*(3-(3-1))=5。
而内网环境的ES是单节点,则副本分片为0,而索引settings中副本分片大小为1,那么此时只需要重新设置索引副本分片数即可,具体操作如下:
执行命令curl -X PUT -H "Content-Type: application/json" -d '{"number_of_replicas":"0"}' 'http://127.0.0.1:9200/authentication-log-2020.09.02/_settings' -u elastic:nroadelastic,返回true则修改成功,

再次查看该索引状态,状态已由yellow变为green:

重复上述步骤将异常索引依次处理,则Elasticsearch状态也将由yellow变为green,日志也可正常上传至Elasticsearch。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)