【HBase之轨迹】(1)使用 Docker 搭建 HBase 集群
继 hadoop 和 zookeeper 之后,再次使用 docker 搭建 hbase 集群,详细说明搭建过程以及 docker 搭建过程中会才踩到的坑。同时
前言(贫穷使我见多识广)
前边经历了 Hadoop,Zookeeper,Kafka,他们的集群,全都是使用 Docker 搭建的
一开始的我认为,把容器看成是一台台独立的服务器就好啦
也确实是这样,但端口映射问题,让我一路以来磕碰了太多太多,直到现在的 HBase,更是将 Docker 集群所附带的挑战性,放大到了极致(目前是如此,往后,凭着我积累下来的理解,再难也是如此,不会,再继续艰难下去了)
虽然在真实开发环境中绝不会使用 Docker 搭建集群,我所习得的这些貌似只是白费功夫,但其实正因为这样,我更加明白了每一个技术背后的通讯是怎么样的,各个端口之间是怎么连接的,集群中的每一个个体,是如何工作的,等等如此
如果你的集群不是 Docker 搭建的,这篇博客依旧合适,只需要忽略那些额外的端口映射配置即可,但我相信,如果你将他们也掠过一遍,对这些技术的理解将会更加深刻
那接下来,就切入正题吧
0. 前置准备
HBase 依赖于 Hadoop 和 Zookeeper,所以需要先将这两个集群搭建起来
其中 HBase 利用了 Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)
来提供分布式数据存储,表中的数据都存放在这里
同时还依赖了 Zookeeper,来管理数据库中的元数据,以及实现高可用
- 还不熟悉 Docker 的,可以参考这里:
【Docker之轨迹】Docker 入门使用(穿插踩坑经历) - Docker 搭建 Hadoop 集群,可参见:
【Docker x Hadoop】使用 Docker 搭建 Hadoop 集群(从零开始保姆级) - Docker 搭建 Zookeeper 集群,可参见:
【Zookeeper之轨迹】Zookeeper 入门使用(集群使用 Docker 模拟)
1. 下载安装
可以从官网里下载:https://www.apache.org/dyn/closer.lua/hbase/2.3.7/hbase-2.3.7-bin.tar.gz
也可以直接单击下载:https://dlcdn.apache.org/hbase/2.3.7/hbase-2.3.7-bin.tar.gz
上传到服务器解压,然后上传到集群中的任意一个容器(如果是虚拟机的话直接上传到对应虚拟机即可)
scp -r hbase-2.3.7 root@hadoop001:/xxx/<目标路径>
2. 配置(重)
接着在该容器中进行配置:
需要配置的文件有 hbase-env.sh, hbase-site.xml 和 regionservers
1) 首先编辑 hbase-env.sh
下面的操作均在该文件中修改,一般都是注释掉的,将注释打开再修改成要的即可
vim conf/hbase-env.sh
2) 查看 JAVA_HOME 路径
echo $JAVA_HOME
3) 修改 JAVA_HOME 配置
export JAVA_HOME=/usr/local/jdk1.8.0_291
4) 不使用 HBase 自带的 zookeeper(用我们自己的方便查看)
export HBASE_MANAGES_ZK=false
修改完如下图:

1) 然后是 hbase-site.xml 文件
vim conf/hbase-site.xml
2) 下边是我的配置供参考
| 首先在这里预先解释几个重要的配置(也是我后边才逐渐理解清楚的) ① hbase.master.port 连接 Master 的端口,在新版本中默认为 16000,0.98之前为 60000 ② hbase.master.info.port 访问 Master 在 web 界面的端口,新版本默认为 16010,0.98之前为 60010 ③ hbase.regionserver.port 连接 RegionServer 的端口,新版本默认为 16020,0.98 之前为 60020 ④ hbase.regionserver.info.port 访问 RegionServer 在 web 界面的端口,新版本默认为 16030,0.98之前为 60030 (超小声)一开始我一直理解为 16010 是访问服务器 hadoop001 的端口,而 16020 是访问 hadoop002 的端口,等到后面设置端口映射的时候屡屡碰壁,才发现原理啊不是这么一回事 |
| 写给使用虚拟机或者有多台服务器的 如果你使用的集群是上边两个之一搭建的,而不是 Docker 搭建的,那么下边这些端口映射的问题通通不存在,可以很丝滑地使用默认配置(可以跳过下边蓝紫色框框) 在下边给出的示例配置文件中,只需要删除端口映射所需要的 4 个自定义配置(即上边提到的那 4 个),就可以正常使用啦 |
| Docker 集群配置说明(Docker 搭建的集群,真的好麻烦啊啊啊,真想买多台服务器呢) 首先经过了对上边几个端口的了解,不难发现 每台服务器都有自己的 master 访问端口和 regionserver 访问端口 但由于我的集群是用 Docker 搭建的,就使得服务器主机中的 1 个 16010 端口无法映射到 3 个容器的 16010 端口,同样 1 个 16020 端口也无法映射到 3 个容器的 16020 端口,16030 同理 所以,就必须 分别用主机的 3 个端口去映射容器的 3 个端口 才能保证每个容器都能正常访问(是真的好麻烦啊啊啊,161xx 端口找了好久才找到这个不冲突的) 我将 3 个容器的 16010 端口分别设置成了 16110, 16111, 16112,然后分别用主机的这三个端口进行映射,即 16110 -> hadoop001:16110, 16111->hadoop002:16111, 16112->hadoop003:16112 同理 3 个容器的 16020 分别设置成了 16120, 16121, 16122,再使用主机端口映射,16030 也一样 最后,由于主机中的 16000 端口貌似已经有东西了,所以我将其改成了 16100,其他两个容器依次为 16101 16102 下面是我 hadoop001 的配置示例,其余两个容器的配置规则就如上边所说,为 hadoop001 的递增 (16101 16111 16121 16131 / 16102 16112 16122 16132 ) |
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop001:8020/HBase</value>
</property>
<!-- master 连接端口 -->
<property>
<name>hbase.master.port</name>
<value>16100</value>
</property>
<!-- master web 界面端口 -->
<property>
<name>hbase.master.info.port</name>
<value>16110</value>
</property>
<!-- regionserver 连接端口 -->
<property>
<name>hbase.regionserver.port</name>
<value>16120</value>
</property>
<!-- regionserver web 界面端口 -->
<property>
<name>hbase.regionserver.info.port</name>
<value>16130</value>
</property>
<!-- 是否为集群模式,默认为 false 即单机模式,这里需要修改 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- zookeeper 集群地址配置,这里加上了来自 Docker 集群的所需的端口映射,默认的 2181 可不显示声明端口 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop001,hadoop002,hadoop003</value>
</property>
<!-- zookeeper 存放数据的目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper-3.5.7/data</value>
</property>
<!-- 临时数据目录 -->
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
配置完,将其分发到各个服务器,再修改对应的端口配置即可(Docker 玩家)
xsync hbase-site.xml
3) 软连接 hadoop 的配置文件到 HBase
ln -s /xxx/hadoop-3.1.3/etc/hadoop/core-site.xml /xxx/hbase-2.3.7/conf/core-site.xml
ln -s /xxx/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /xxx/hbase-2.3.7/conf/hdfs-site.xml
最后配置 regionservers
该文件是用来群起 HBase 的,里边存放集群中各个服务器的 IP 地址
这里我使用的是 docker 容器,就填写 docker 容器的地址,参考如下:(已经做过映射了)
hadoop001
hadoop001
hadoop003
配置完毕,最后分发到各个服务器中
xsync hbase-2.3.7
| 最后的最后,也是对于 Docker 玩家来说最重要的:端口映射配置 总体来说就是:服务器打开防火墙,进行端口映射 ① 打开防火墙的命令如下: firewall-cmd --zone=public --add-port=16100/tcp --permanent firewall-cmd --zone=public --add-port=16110-16112/tcp --permanent firewall-cmd --zone=public --add-port=16120-16122/tcp --permanent firewall-cmd --zone=public --add-port=16130-16132/tcp --permanent ② 端口映射,这里送给大家一份自制的 shel 脚本,大家可以直接跑 可循环利用的哦,不过里边一些 IP 之类的,要自己改好 往后我也会出一个合集,专门分享这些集成的 shell 脚本 然后使用 chmod 700 xxx 赋予执行权限,再执行 ./xxx iptables hadoop001便表示以 hadoop001 为 master,对集群进行上述端口映射 |
#!/bin/bash
# 基本提示信息
function execMessage() {
if [ $? -eq 0 ]; then echo -e '\033[1;32m--> '${1}' 成功\033[39;49;0m'
else echo -e '\033[1;31m!!! '${1}' 失败\033[39;49;0m'
fi
}
# 动态添加端口映射
function addPort() {
realPort=$2
if [ $2 == 'hadoop001' ]; then realPort="172.16.10.10"
elif [ $2 == 'hadoop002' ]; then realPort="172.16.10.11"
elif [ $2 == 'hadoop003' ]; then realPort="172.16.10.12"
fi
iptables -t nat -A DOCKER -p tcp --dport $1 -j DNAT --to-destination $realPort:$3
execMessage "为 "$2" 添加 "$1" -> "$3" 端口映射"
}
operation=$1
master=$2
echo -e '\033[1;33m========= [IceClean] 执行' $operation '\033[39;49;0m'
case $operation in
"start") {
ssh $master /home/hadoop/hbase-2.3.7/bin/start-hbase.sh
execMessage "以 "$master" 为 Master 启动 HBase"
};;
"stop") {
ssh $master /home/hadoop/hbase-2.3.7/bin/stop-hbase.sh
execMessage "以 "$master" 为 Master 关闭 HBase"
};;
"iptables") {
addPort 16100 hadoop001 16100
addPort 16101 hadoop002 16101
addPort 16102 hadoop003 16102
addPort 16110 hadoop001 16110
addPort 16111 hadoop002 16111
addPort 16112 hadoop003 16112
addPort 16120 hadoop001 16120
addPort 16121 hadoop002 16121
addPort 16122 hadoop003 16122
addPort 16130 hadoop001 16130
addPort 16131 hadoop002 16131
addPort 16132 hadoop003 16132
};;
esac
最后可以使用 iptables -t nat -L DOCKER --line-numbers 查看端口映射是否正确,下图是我映射后的结果:

3. 启动与关闭
进入 bin,看到下图:
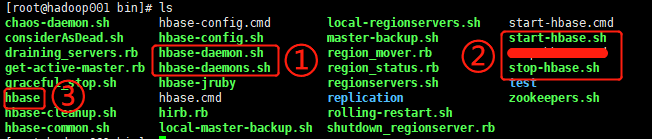
其中 ① 是用来单独启动 HBase 的,分别为单个单独启动和多个单独启动
② 是用来群起 HBase 集群的,分别为群起集群和关闭集群(与 regionservers 有关)
③ 为 HBase 的操作入口,在这里进行命令行的操作
这里以群起为例(再不哪个服务器执行群起,哪个服务器就是 Master)
./start-hbase.sh
也可以使用上边提供的脚本进行重启,后边接 hadoop001 表示以它为 Master
./xxx start hadoop001
启动完毕后,就可以在 Web 端访问到了,默认的访问端口是 16010
但如果是 Docker 玩家,再是上边的端口映射中我已经改成了 16110
启动完毕后,就可以在 Web 端访问该端口来访问 HBase 主页了

可以看到里边 3 个容器,同时显示它们 RegionServer 的连接端口是 16120,16121 和 16122
随便点一个进去,看到连接跳转的是 hadoop001:16130 或 hadoop002:16131 或 hadoop003:16132,表示全部端口映射正常!
关闭也是一样操作:
./stop-hbase.sh 或 ./xxx stop hadoop001
4. 搭建高可用 HBase
① 底层逻辑:
HBase 集群中的每个服务器都会启动一个 HMaster
在 Zookeeper 创建一个存储数据的临时结点
成功创建结点的 HMaster 则作为 Active Master 成为当前 Master
而其他 HMaster 则作为 Backup Master 继续监听(watch) Zookeeper 中该临时结点
一旦当前 Master 挂掉了,其创建的临时结点会被销毁
其他 HBase 就会监听到,同时去创建自己临时结点
创建成功的则成为新的 Active Master,其他继续作为 Backup Master 监听临时结点
② 搭建流程:
在 HBase 的 conf 目录下,创建 backup-masters 文件
将集群中除默认 master 以外的所有结点写入,示例如下:
这里是为 hadoop002 和 hadoop003 分配了虚拟 IP 的,如果是服务器真机的可以填服务器 IP 或者域名
hadoop002
hadoop003
然后分发的每个集群
xsync backup-masters
最后重启 HBase,即可实现高可用了
./stop-hbase.sh
./start-hbase.sh
对各个容器使用 jps,可以发现它们都运行了 HMaster
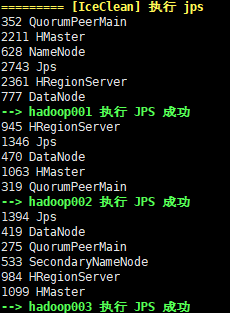
在 hadoop001 的 master web 界面中,可看到:

表示 hadoop002 和 hadoop003 都作为 Backup Master,随时准备顶替宕机后的 master 位置
可以试试将 hadop001 的 master 杀掉,可以观察到这两台会重新选出一个 master
最后,搭建完集群后,就可以使用 shell 命令行或者 JavaAPI 对 HBase 进行操作了
可继续阅读:【HBase之轨迹】(2)使用 hbase命令 和 JavaAPI 操作 HBase(包括复杂查询–过滤器,HBase 工具类)
行百里者半九十,剩下的十里是质的跃升(IceClean)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)