phoenix使用详解
phoenix和hive类似,它也是一个工具,hive是在hadoop之上,phoenix是在hbase之上,也是Apache基金的顶级项目。phoenix是构建在HBase上的一个SQL层,能让我们用标椎的JDBC APIs而不是HBase客户端APIs来创建表、和对HBase数据进行CRUD。Phoenix完全使用java编写,作为HBase内嵌的JDBC驱动,Phoenix查询引擎会将SQL
phoenix使用详解
一、phoenix是什么
我前面文章说过一个观点:“懒人改变世界”,phoenix的出现也验证来它的准确性。
phoenix和hive类似,它也是一个工具,hive是在hadoop之上,phoenix是在hbase之上,也是Apache基金的顶级项目。
phoenix是构建在HBase上的一个SQL层,能让我们用标椎的JDBC APIs而不是HBase客户端APIs来创建表、和对HBase数据进行CRUD。
Phoenix完全使用java编写,作为HBase内嵌的JDBC驱动,Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描(Scan),并编排执行以生成标椎的JDBC结果集。
Phoenix通过以下方式减少我们的代码量,提高生产效率,并且性能比我们自己写代码更好:
1、将SQL编译成原生的HBase scan;
2、确定scan关键字的最佳开始和结束;
3、让scan并行执行。
二、phoenix架构
架构图:
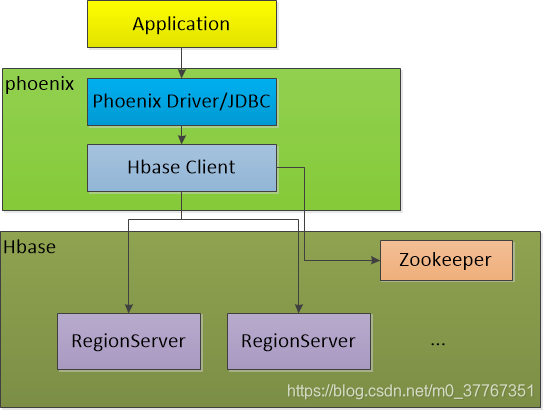
phoenix架构图如上,我们应用通过phoenix驱动通过jdbc方式连接Hbase,其中phoenix驱动会用到hbase的client。phoenix把我们熟知的sql编译转换成hbase原生的shell语法,再通过hbase client去访问hbase,后续到了hbase的流程可参考我前面文章《HBase详解》的介绍。
三、phoenix表与hbase表对应关系
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的。
如果要在phoenix中操作由hbase创建的表,则需要在phoenix中进行表的映射。
映射方式有两种:视图映射和表映射
假设Hbase中已创建表test,test有两个列簇name、company
视图映射:
Phoenix创建的视图是**【只读】**的,只能用来做查询,无法通过视图对源数据进行修改等操作。
create view "test"(
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname" varchar,
"company"."name" varchar,
"company"."address" varchar
);
表映射
(1)、把create view改为create table即可
(2)、当HBase中不存在表时,使用create table指令创的表,系统将会自动在Phoenix和HBase中创建表,并会根据指令内的参数对表结构进行初始化。
create table "test"(
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname" varchar,
"company"."name" varchar,
"company"."address" varchar
);
四、phoenix基本语法
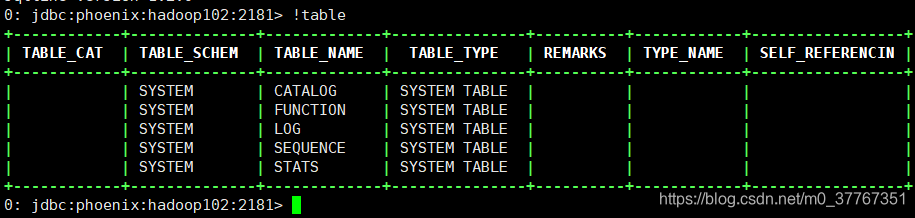
!table查看表信息
!describe tablename可以查看表字段信息
SELECT
SELECT * FROM TEST where colum = '123' LIMIT 10 OFFSET 10;
UPSERT VALUES
UPSERT INTO TEST(NAME,ID) VALUES('foo',123);
UPSERT SELECT
UPSERT INTO test.targetTable(col1, col2) SELECT col3, col4 FROM test.sourceTable WHERE col5 < 100
DELETE
DELETE FROM TEST WHERE ID=123;
CREATE TABLE
CREATE TABLE my_schema.my_table ( id BIGINT not null primary key, date Date)
DROP TABLE
DROP TABLE my_schema.my_table;
ALTER
ALTER TABLE my_table ADD dept_name char(50);
CREATE INDEX
CREATE INDEX my_idx ON sales.opportunity(last_updated_date DESC)
CREATE INDEX my_idx ON log.event(created_date DESC) INCLUDE (name, payload) SALT_BUCKETS=10
DROP INDEX
DROP INDEX my_idx ON sales.opportunity
phoenix字段类型
| 类型 | java 类型 | 长度 |
|---|---|---|
| INTEGER | java.lang.Integer | -2147483648 to 2147483647 |
| UNSIGNED_INT | java.lang.Integer | 0 to 2147483647 |
| BIGINT | java.lang.Long | -9223372036854775807 to 9223372036854775807 |
| UNSIGNED_LONG | java.lang.Long | 0 to 9223372036854775807 |
| TINYINT | java.lang.Byte | -128 to 127 |
| UNSIGNED_TINYINT | java.lang.Byte | 0 to 127 |
| SMALLINT | java.lang.Short | -32768 to 32767 |
| UNSIGNED_SMALLINT | java.lang.Short | 0 to 32767 |
| FLOAT | java. lang.Float | -3.402823466 E + 38 to 3.402823466 E + 38 |
| UNSIGNED_FLOAT | java.lang.Float | -3.402823466 E + 38 to 3.402823466 E + 38 |
| DOUBLE | java.lang.Double | -1.7976931348623158 E+308 to 1.7976931348623158 E+308 |
| UNSIGNED_DOUBLE | java.lang.Double | 0 to 1.7976931348623158 E + 308 |
| DECIMAL | java.math.BigDecimal | 38 digits |
| BOOLEAN | java.lang.Boolean | |
| TIME | java.sql.Time | |
| DATE | java.sql.Date | |
| TIMESTAMP | java.sql.Timestamp | |
| UNSIGNED_TIME | java.sql.Time | |
| UNSIGNED_DATE | java.sql.Date | |
| UNSIGNED_TIMESTAMP | java.sql.Timestamp | |
| VARCHAR( precisionInt ) | java.lang.String | |
| CHAR ( precisionInt ) | java.lang.String | |
| BINARY ( precisionInt ) | byte[] | |
| VARBINARY | byte[] |
五、phoenix加盐表
1. 什么是加盐?
在密码学中,加盐是指在散列之前将散列内容(例如:密码)的任意固定位置插入特定的字符串。其作用是让加盐后的散列结果和没有加盐的结果不相同,在不同的应用情景中,这个处理可以增加额外的安全性。而Phoenix中加盐是指对pk对应的byte数组插入特定的byte数据。
2. 加盐的好处?
加盐能解决HBASE读写热点问题,例如:单调递增rowkey数据的持续写入,使得负载集中在某一个RegionServer上引起的热点问题。均匀划分region,均匀打散数据分布。
3. 怎么对表加盐?
在创建表的时候指定属性值:SALT_BUCKETS,其值表示所分buckets(region)数量, 范围是1~256。
CREATE TABLE table (key VARCHAR PRIMARY KEY, col VARCHAR) SALT_BUCKETS = 8;
4. 加盐的原理是什么?
加盐的过程就是在原来key的基础上增加一个byte作为前缀,计算公式如下:
new_row_key = (++index % BUCKETS_NUMBER) + original_key
5、加盐加多少好
加盐要是hbase节点数的倍数,最少是1倍(3个节点的就是3)
根据表数据量大小增加加盐数
六、phoenix二级索引
phoenix的二级索引是一个很好用的功能,解决了hbase没有索引的缺陷。我们创建了二级索引其实是在hbase额外建了一张表,该表数据无需我们维护,用phoenix自动维护。
七、phoenix使用注意点
1.select语句禁止全表扫描,一定要走主键索引或者二级索引,可用explain查看sql执行计划。我们可以巧妙合理的设计我们的主键。
2、使用主键索引查询时,where条件的顺序一定要和建表定义主键的顺序一致,要不然走不到主键索引。
3.使用二级索引只能查主键字段和创建索引是INCLUDE后面添加的字段,禁止查额外字段,因为查了其它字段就不会走到二级索引,是全表扫。非要查额外字段可以查两次,先查出主键,再根据主键去查。
4.建表和索引是最好都提前做加盐。
八、java应用使用phoenix
1.引入架包
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>phoenix版本</version>
</dependency>
2.phoenix连接
phoenix连接我们连接普通关系型数据库一样,可以使用阿里巴巴的连接池com.alibaba.druid.pool.DruidDataSource
驱动:org.apache.phoenix.jdbc.PhoenixDriver
连接串dbUrl为:jdbc:phoenix:zk1,zk2:2181/hbase,其中zk为Zookeeper的ip,2181为Zookeeper端口,/hbase要看我们hbase的配置选填
3.使用
可以和关系型库那样愉快的使用mybatis框架访问hbase数据.
九、phoenix连接工具
1、服务器官网下载好phoenix,进入bin目录执行如下命令即可进去phoenix,就可以使用phoenix命令操作了。
./sqlline.py zk1,zk2:2181/hbase
2、图形化界面工具
DBeaver,SQuirrel等
更多phoenix相关内容请参考phoenix官网
http://phoenix.apache.org/
参考链接
https://blog.csdn.net/dz77dz/article/details/105784099
https://www.cnblogs.com/hbase-community/p/8727674.html

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)