Redis实用功能汇总
redis实用功能
特征
- k-v型数据库,value支持多种不同的数据结构,功能丰富
- 单线程,每个命令具有原子性
- 低延迟,速度快(基于内存,io多路复用,良好的编码)
- 支持数据的持久化
- 支持主从集群,分片集群
- 支持多语言客户端
Redis命令
redis客户端
redis-cli -h 192.168.150.101 -p 6379 -a 密码
redis数据类型
key为string类型,但是value类型多种多样
基本类型
- string类型:hello world
- hash类型:{“name”:“Tom”,age:21}
- List类型:[A,B,C]
- Set类型:{A,B,C}
- SortedSet类型:{A:1,B:2,C:3}
特殊类型
- GEO:{A:(1,2)}
- BitMap:01011001
- HyperLog:01011001
redis命令
key命令
- 查询所有key
keys *
- 删除key
DEL k1 k2 k3 k4
- 判断key是否存在
EXISTS key
- 给key设置有效期
EXPIRE key second
- 查看key有效期
TTL key
String类型value命令
- set设置键值对
set name Tom
- get获取键值对
get name
- mset批量设置键值对
mset k1 v1 k2 v2
- mget批量获取键值对
mset k1 v1 k2 v2
- incr 让整型的key自增1
incr key
- incrby 让整型的key自增指定步长
incrby key 3
- setnx 添加一个String类型的键值对,若key存在则不执行
setnx key value
- setex 添加一个String类型的键值对,并设置有效期
setex key second value
key的层级格式
有时候会遇到这样的问题,商品存在id,角色存在id,那么key如果都叫id的话没有办法进行区分。这边统一做了个命名规范,用:来进行层级划分。
如:项目名:业务名:类型:id
| key | value |
|---|---|
| tdx:user:1 | {id:1,name:Tom,age:19} |
| tdx:product:1 | {id:1,name:xiaomi11,price:4999} |
hash类型value命令
- hset 添加hash类型的key的field值
hset key field value
- hget 获取hash类型的key的field值
hget key field
- hmset 批量添加hash类型的key的field值
hmset key f1 v1 f2 v2
- hmget 批量查看hash类型的key的field值
hmget key f1 f2 f3
- hgetall 获取key下的所有键值对
hgetall key
- hkeys 获取hash类型key中所有field
hkeys key
- hvals 获取hash类型key中所有values
hvals key
- hsetnx 添加一个hash类型的key的field值,前提是field不存在,否则不执行
hsetnx key field value
List类型value命令
list可以看成数据结构中的双向链表
- lpush key element… 向列表左侧插入1个或者多个元素
- lpop key 移除并返回列表左侧的第一个元素,没有则返回nil
- rpush key element… 向列表右侧插入1个或者多个元素
- rpop key 移除并返回列表右侧的第一个元素
- lrange key start end 返回角标范围内所有元素
Set类型value命令
可以看成java中hashset的结构
- saad key member… 向set中添加一个或者多个元素
- srem key member… 移除set中指定元素
- scard key 返回set中元素的个数
- sismember key member 判断元素是否在集合中
- smembers 获取set中的所有元素
- sinter key1 key2 求key1与key2的交集
- sdiff key1 key2 求key1与key2的差集
SortedSet类型value命令
特性:
- 可排序
- 元素不重复
- 查询速度快
每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
- zaad key score member… 添加一个或者多个元素到SortedSet中,如果已存在则更新score值
- zrem key member… 移除SortedSet中指定元素
- zscore key member 获取SortedSet中指定score值
- zrank key member 获取SortedSet中指定元素排名
- zcard key 获取SortedSet中元素的个数
- scard key 返回set中元素的个数
- zcount key min max 统计score在指定范围内的所有元素个数
- zrange key min max 按照score排序后返回指定排名范围内元素
- zrangebyscore key min max 按照score排序后返回指定score范围内元素
- zdiff , zinter, zunion 求差集、交集、并集
缓存更新策略
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不需要自己维护,可以直接利用redis内存淘汰机制 | 给缓存添加ttl | 编写业务逻辑,更新数据库时候主动更新缓存 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
主动更新策略一般有如下方案:
- cache aside pattern:由缓存调用者在更新数据库的时候同时更新缓存。
- read/write through pattern:缓存与数据库整合为1个服务,由服务来维护一致性。
- write behind caching pattern:调用者之操作缓存,同步数据库操作由定时任务异步执行。
cache aside pattern
问题1:更新数据库时删除缓存还是更新缓存?
- 更新:每次更新数据库更新缓存,无效写操作多
- 删除:更新数据库时让缓存失效,查询时再更新缓存(推荐)
问题2:如何保证数据库操作和缓存操作同时成功或者失败?
- 单体:将缓存与数据库操作放在同一个事物
- 分布式:利用TCC等分布式事务的方案
问题3:如何保证线程安全问题?
- 先写数据库再写缓存,这种方案出现线程安全问题的概率小。
read/write through pattern
本质也是自己实现一个cache aside pattern服务
优点:解耦,支持分布式场景
缺点:维护成本比较高
write behind caching pattern
优点:读写速度快
缺点:异步会导致缓存与数据库数据不一致
缓存穿透
定义:指的是客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求全部都打到数据库。
解决方案:
-
缓存空对象:一旦业务逻辑识别到缓存与数据库中都不存在,那么缓存中该key存空值
- 优点:实现简单,维护方便
- 缺点:
- 额外内存消耗
- 可能造成短期不一致
-
布隆过滤
https://blog.csdn.net/qq_40124555/article/details/122810154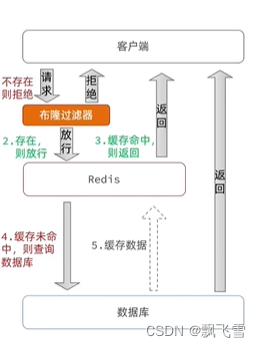
一般使用方案1
缓存雪崩
定义:同一时段大量缓存的key同时失效或者redis服务宕机,导致大量请求到达数据库带来压力。
解决方案:
- 不同key的ttl添加随机值
- 利用redis集群提高服务可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
定义:也称为热点key问题,一个被高并发访问并且缓存重建业务较复杂的key突然失效,无数的请求访问会在瞬间给数据库带来巨大的冲击。
解决方案:
- 设置热点数据永远不过期(可以判断当前key快要过期时,通过后台异步线程在重新构建缓存)
- 接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些服务不可用时候,进行熔断,失败快速返回机制。
- 设置互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
(可以使用 Redis 分布式锁)
(1) 就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db。
(2) 先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个互斥锁。
(3) 当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key;
(4) 当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。
分布式锁
实现原理
实现分布式锁的基本方法:
-
获取锁
setnx lock thread1
设置超时时间,保证服务挂了后不至于死锁
set lock thread1 EX 10 NX -
释放锁
del lock
redis实现分布式锁主要依赖的是redis命令原子性的特性
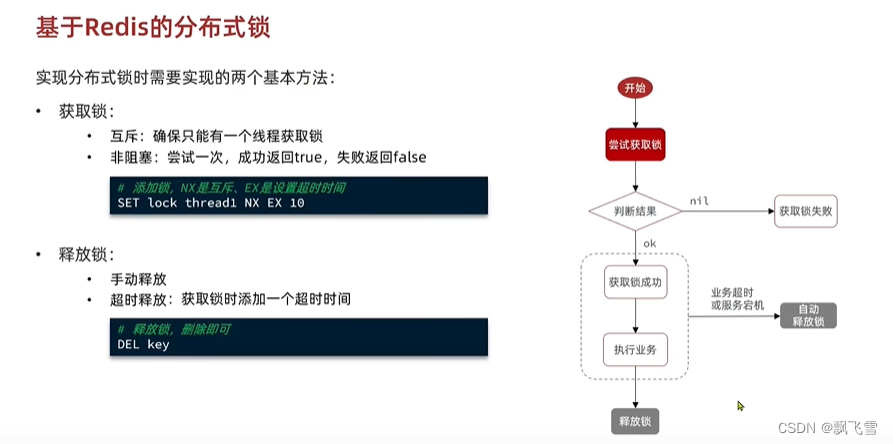
但是这么实现分布式锁存在问题, 也就是超时释放锁的逻辑,假如线程阻塞了,在ttl时间内业务没有执行完就把锁给释放了,就存在问题了。
所以解决这个问题的关键在于释放锁的时候,锁的标识是否与线程的一致。
实现方案是在获取锁的时候存入线程id,在释放锁的时候先判断当前线程id与存的id是否一致,如果一直则进行锁释放,如果不一致则不释放锁
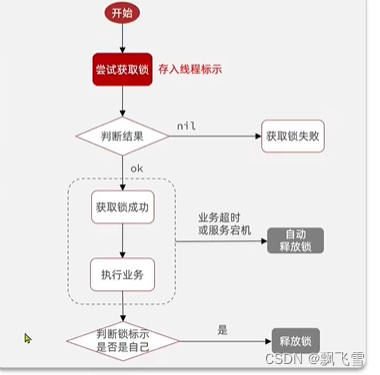
到这边还不够,判断锁标识和释放锁这两个动作必须是原子操作。
解决方案:
- 业务代码给这两个动作加锁(不推荐,消耗资源特别大)
- redis提供的lua脚本编写多条redis命令,确保多条命令执行的原子性。(推荐)写好脚本后,使用eval命令来调用脚本

通用包
如java语言redission
消息队列
消息队列:存储和管理消息,也称为消息代理。
生产者:发送消息到消息队列。
消费者:从消息队列获取消息并处理消息。
redis提供3种不同方式实现消息队列:
- list:基于list实现消息队列
- PubSub:基于点对点的消息模型
- Stream:比较完善的消息模型
List消息队列
- 阻塞版本实现:使用LPUSH+BRPOP命令进行实现
- 非阻塞版本实现:使用LPUSH+RPOP命令进行实现
优点:
- 基于redis持久化机制,数据安全性有保障
- 可以满足消息的有序性
缺点:
- 无法避免消息的丢失
- 只支持单消费者
PubSub消息队列
PubSub是redis2.0版本引入的消息传递模型。消费者可以订阅多个channal,生产者向对应的channal发送消息后,所有订阅者都能收到相关消息。(发布订阅模型)
- subscriibe channel :订阅1个或者多个频道
- publish channel msg:向1个频道发送消息
- psubscriibe pattern:订阅与pattern格式匹配的所有频道
优点:
- 采用发布订阅模型,多生产多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
Stream单消费模式
Stream是redis5.0版本引入的新数据类型,可以实现很完善的消息队列
发送消息
读取消息
特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
Stream消费者组模式


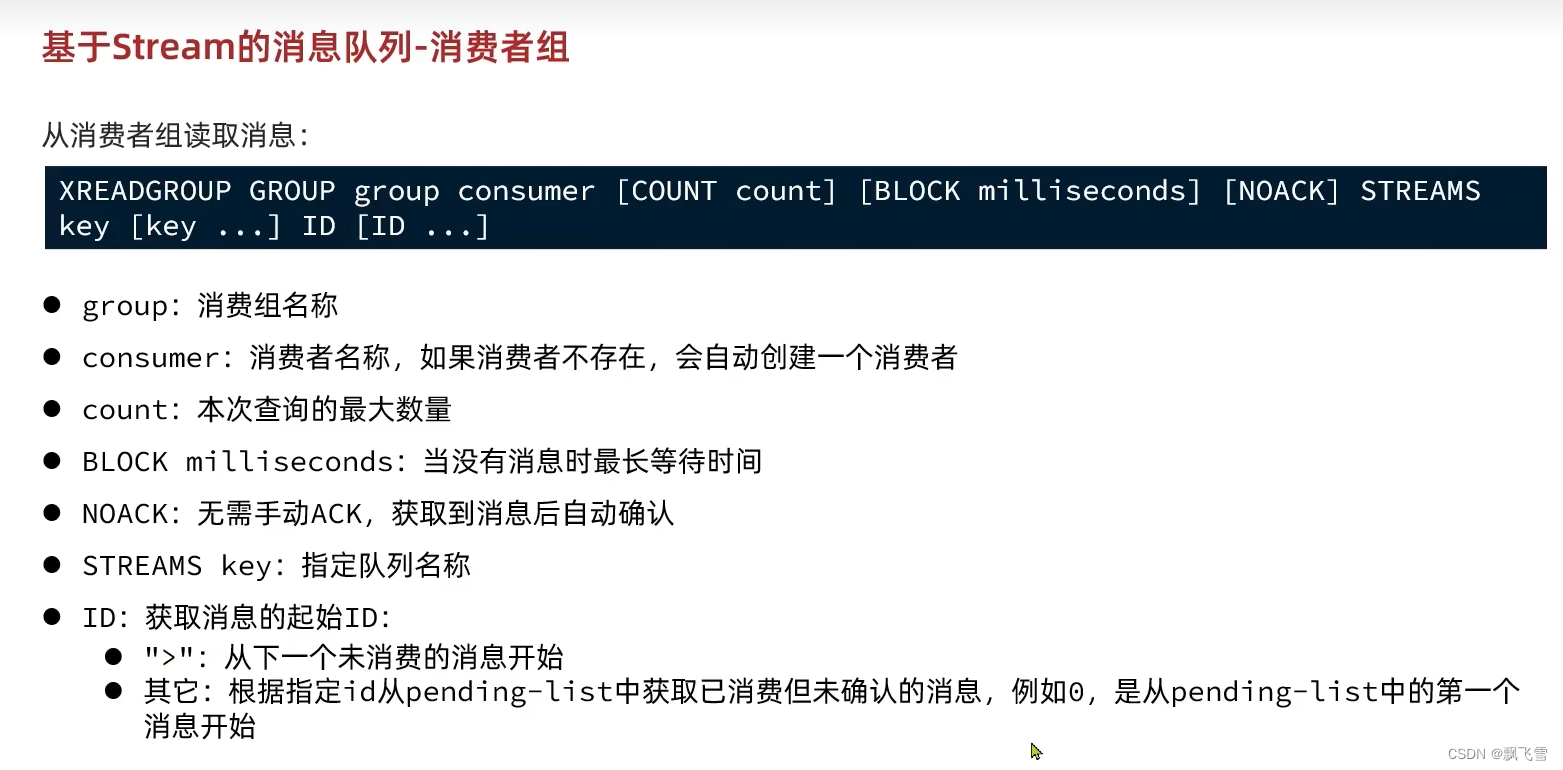
Redis持久化
RDB
RDB全称redis database backup file(redis数据备份文件),也被叫做redis数据快照。简单说就是把内存中所有数据存储到磁盘中。当redis实例故障重启后,从磁盘读取快照文件,恢复数据。
命令:
- save命令,由redis主进程来执行rdb,会阻塞所有命令
- bgsave命令,由后台执行save操作
save 900 1 # 900秒内,如果至少有1个key被修改,则执行bgsave

缺点:如果你对数据的完整性非常敏感,那么RDB 方式就不太适合你,因为即使你每5 分钟都持久化一次,当Redis 故障时,仍然会有近5 分钟的数据丢失。
AOF
AOF全称Append Only File(追加文件)。redis处理的每一个写命令都会记录在AOF文件中,可以看作是命令日志文件。

缺点:在同样数据规模的情况下,AOF文件要比RDB文件的体积大。而且,AOF 方式的恢复速度也要慢于RDB 方式。
主从哨兵机制
https://baijiahao.baidu.com/s?id=1708708753081996429&wfr=spider&for=pc

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)