Sqoop笔记 —— MySQL与Hive、HBase、Hdfs的数据导入和导出
sqoop是一个开源工具,主要用处是在Hadoop(hive,hdfs,hbase)与传统的数据库(mysql,Oracle)之间进行数据的传递MySQL到hdfs的默认加载首先在mysql里面建表并加载数据然后创建一个文件夹,在里面创建编写conf文件import--connectjdbc:mysql://master:3306/student?useSSL=false--usernameroo
sqoop是一个开源工具,主要用处是在Hadoop(hive,hdfs,hbase)与传统的数据库(mysql,Oracle)之间进行数据的传递
import:数据从传统数据库到Hadoop里面
export:数据从Hadoop到传统数据库里面
MySQL到hdfs的默认加载
首先在mysql里面建表并加载数据
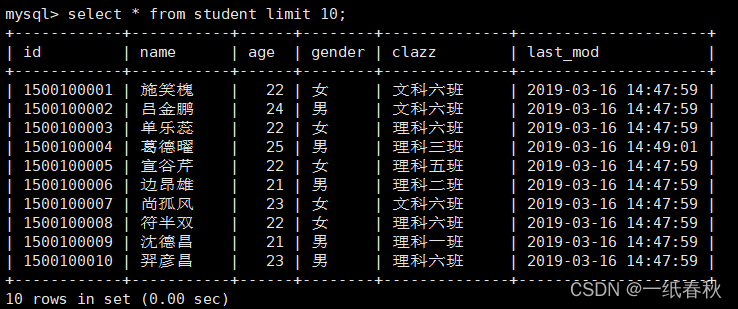
然后创建一个文件夹,在里面创建编写conf文件

import
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
student
--target-dir
/sqoop/data/student
--fields-terminated-by
','
import:说明是数据导入,这里是Mysql的数据到hdfs
connect:连接mysql数据库
username:数据库用户名
password:数据库密码
table:要导入到hdfs里面的数据库的表名
target-dir:hdfs路径,数据被导入到这个文件夹下面,如果没有会自动创建
fields-terminated-by :字段值之间的分隔符
然后在linux终端输入
sqoop --options-file MysqlToHdfs.conf
看一下加载过程中的日志信息
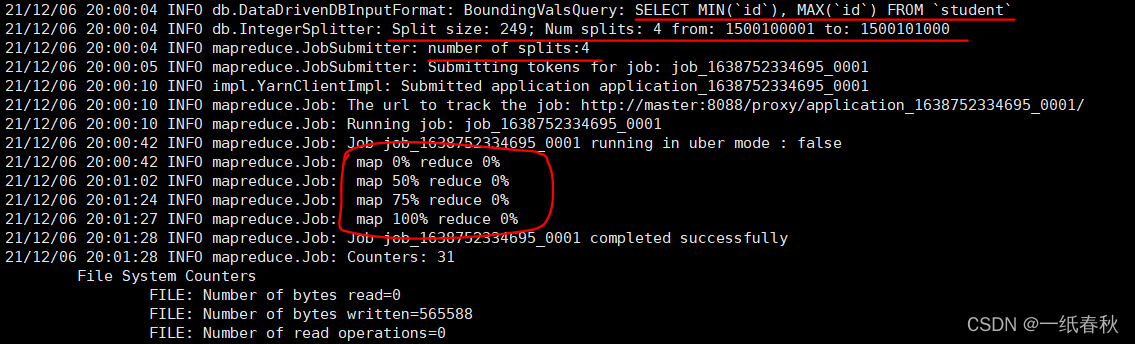
按照图上我画红线的地方依次说明一下,首先是一条sql语句,SELECT MIN(id), MAX(id) FROM student 这条sql语句用来获取student表中的主键字段,id这一列的全部值。为什么要获取全部数据的主键字段值呢,来看下一句
下一句开头就说了 Split size :249,这个是划分的体积大小,后面跟着划分的全部范围是1500100001到1500101000,这个范围是id的最小值到id的最大值。再下一句就给出了最终的划分个数,4个,那么最终生成的文件也应该是四个,与划分的个数对应
这里是因为没有给定map任务,也没有给出划分依据的字段,所以默认按照主键字段的范围进行划分。
再往下面来看,画圈的部分,这里很明显是MapReduce任务,说明Sqoop将mysql数据导入到hdfs里面,底层调用的是MapReduce,这里只有Map是100%,而Reduce是0%,说明只需要Map任务即可写入完成,没有Reduce任务
然后到hdfs这里来看看结果
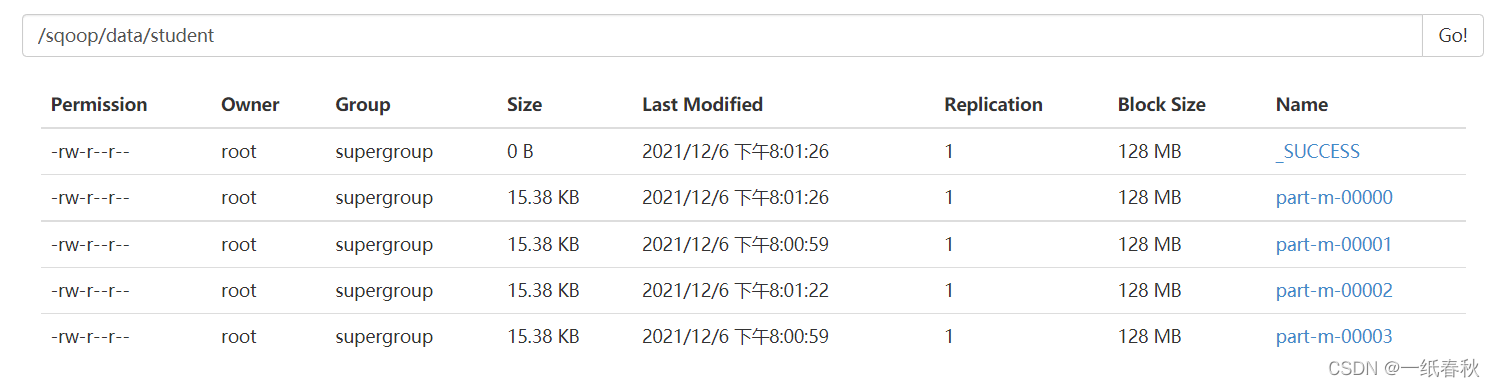
发现与上面分析的一致,确实生成了四个文件
来看一下文件里面的内容
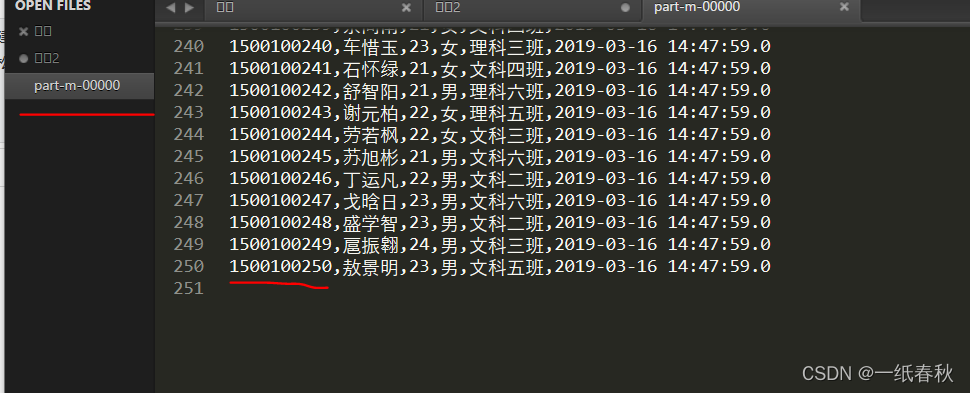
左边是 part-m-00000,不是以前的part-r-00000,这样也说明了只用到了Map任务,没有Reduce任务
然后这个文件的最后一行的id是1500100250
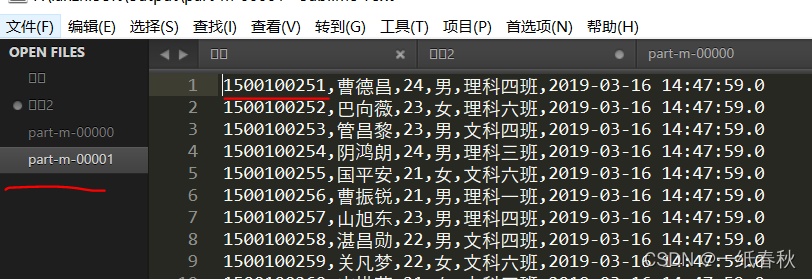
下一个文件,00001文件的第一行的id就是1500100251,正好与上一个文件的id连上,说明确实是按照id划分
Mysql到hdfs的具体加载
import
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
student
--m
2
--split-by
age
--target-dir
/sqoop/data/student1
--fields-terminated-by
','
--delete-target-dir
m : 表示有几个Map任务
split-by:表示按照什么字段切分
delete-target-dir:如果target-dir目录已经存在则删除

再来看加载时的日志信息,就很明显划分的字段变成了age,而是划分的范围依旧是age的最小值到age的最大值。而number of splits划分的个数,变成了2个,这里是与Map任务个数一致,也就是 --m 设置的2

注意:
- –m用来指定有几个Map任务,但是不是越多越好,因为MySQL Server的承载能力有限
- 如果没有用split-by 指定分割字段,那么默认是主键。如果要手动指定,需要指定数字类型的字段,最好是主键。另外指定时需要考虑数据分布问题,避免发生Map端的”数据倾斜“,即一个Map任务处理过多的数据
- 编写脚本文件时注意规范,像-- password 与 123456 就不能写在同一行
- sqoop读取mysql数据时用的是JDBC的方式
sqoop导入导出数据时,底层调用的是MapReduce,不过只有Map任务,没有Reduce任务 - 每个Map任务都会生成一个文件
如果没有指定Map任务个数,那么会自动按照范围,用Split size来划分文件个数
更多参数可以在sqoop官网查看
https://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html
Mysql到Hive
import
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
student
--fields-terminated-by
"\t"
--lines-terminated-by
"\n"
--m
3
--split-by
id
--hive-import
--hive-overwrite
--create-hive-table
--hive-database
studentsqoop
--hive-table
student
--delete-target-dir
前面的参数与mysql写入hdfs的参数差不多,然后来看看下面新增的参数
fields-terminated-by:读取数据时使用的字段分隔符
lines-terminated-by:读取数据时使用的行分隔符
hive-overwrite:表明数据的写入方式
create-hive-table:表明自动在hive中创建表
hive-database:表明写入到哪个数据库里面
hive-table:表明要写入的表名
执行语句
sqoop --options-file MysqlToHive.conf
加载完毕后到hive里面查看一下
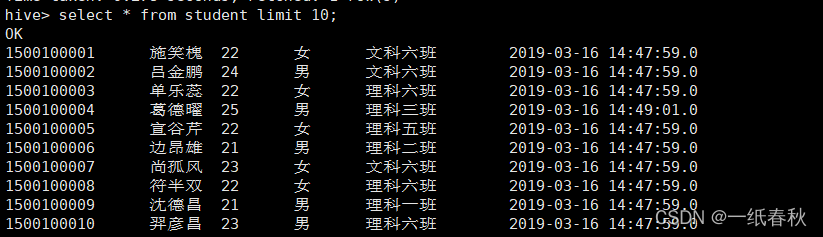
再计算一下count值,然后重新执行sqoop语句

再一次往student表里面写入数据,然后再计算依次count值
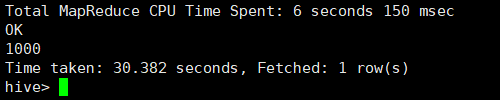
依旧是1000,说明了写入方式是overwrite,即覆盖原先的内容
注意1:
在执行mysql导入到hive的语句之前,需要
将HADOOP_CLASSPATH加入环境变量中
vim /etc/profile
# 加入如下内容
export HADOOP_CLASSPATH=$HADOOP_HOME/lib:$HIVE_HOME/lib/*
# 重新加载环境变量
source /etc/profile
将hive-site.xml放入SQOOP_HOME/conf/
cp /usr/local/soft/hive-1.2.1/conf/hive-site.xml /usr/local/soft/sqoop-1.4.7/conf/
注意2:
MySQL的数据导入Hive的步骤是:一开始从MySQL里面将数据取出来,然后数据先被存放在hdfs上的一个临时目录里,默认为:/user/用户名/表名。然后再将数据加载到Hive中,加载完成后,会将临时存放的目录删除。如果没有在hive中创建数据库就执行sqoop语句,那么前半部分从MySQL导出部分,也就是Map任务会正常执行,但是执行完毕后,将数据加载到hive里面时,就会报错。
–direct参数与–e参数的使用
加上–direct参数,可以在导出MySQL数据的时候,使用MySQL提供的导出工具mysqldump,加快导出速度,提高效率
使用这个参数之前需要将master上的/usr/bin/mysqldump分发至 node1、node2的/usr/bin目录下
scp /usr/bin/mysqldump node1:/usr/bin/
scp /usr/bin/mysqldump node2:/usr/bin/
–e参数
这个参数用sql语句来选择,具体将Mysql里面的哪些数据导入Hive里面
import
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--fields-terminated-by
"\t"
--lines-terminated-by
"\n"
--m
2
--split-by
id
--e
"select * from student where id=1500100259 and $CONDITIONS"
--target-dir
/sqoop/data/hive
--hive-import
--hive-overwrite
--create-hive-table
--hive-database
studentsqoop
--hive-table
student1
--direct
sqoop语句执行完毕后,查看一下hive里面生成的表

发现只有满足 --e 参数下面的sql语句的数据才被导入到了hive里面
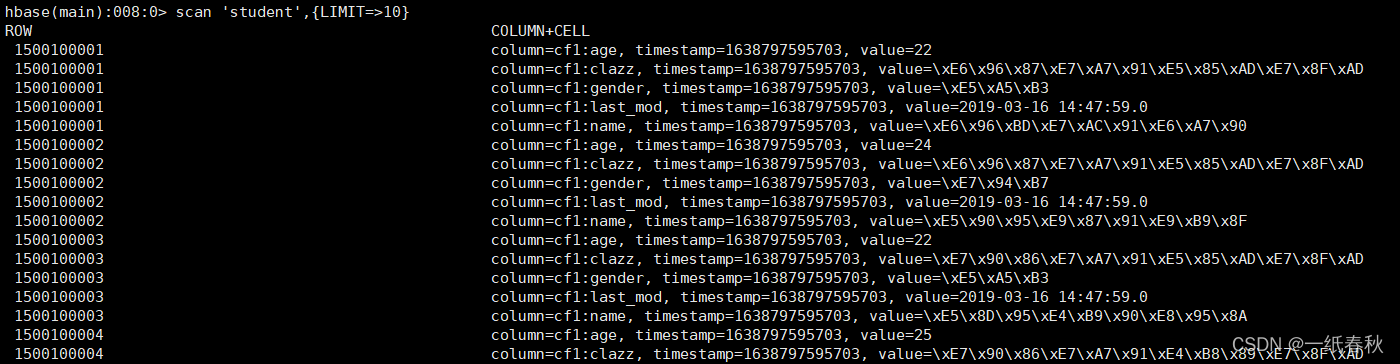
Mysql导入到Hbase
首先在hbase里面建表
create 'student','cf1'
然后编写脚本
import
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
student
--hbase-table
student
--hbase-create-table
--hbase-row-key
id
--m
1
--column-family
cf1
hdfs导出Mysql
[root@master data]# hdfs dfs -mkdir /data
[root@master data]# hdfs dfs -cp /sqoop/data/student/part-m-00000 /data
export
--connect
jdbc:mysql://master:3306/student?useSSL=false
--username
root
--password
123456
--table
student
-m
1
--columns
id,name,age,gender,clazz
--export-dir
/data
--fields-terminated-by
','
将hdfs里面的/data目录下的文件(文件数量可以不止一个)加载到mysql的student表里面
新建一个文件,传入hdfs里面的/data目录下
1500100259,关凡梦,22,女,文科六班
1500100263,姚昆鹏,22,男,理科二班
1500100263,姚昆鹏,22,男,理科二班
清空表里面的数据后,再执行sqoop语句

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)