使用Ubuntu平台安装和配置Pig系统环境
P.S.这里斗胆纠正一下书上的小问题(可能不是错只是单纯的不适合),书上建议是下载pig-0.17.0.-src.tar.gz文件(这是源码文件),如果按照书本上的文件下载,会在最后运行Pig的时候出现摘不到某文件位置的报错。关于pig-0.17.0.-src.tar.gz和pig-0.17.0.tar.gz的区别,简单的说。一定要找准蓝色划横线地方的路径是自己的机子上对应的(路径+名称)本次操作
(一)一些tips
-
本次操作的是在Ununtu16.04.7的基础上进行安装的
-
需要已经预先安装好Hadoop、Hbase、配置好JAVA环境等
-
本优化步骤主要针对于 《数据采集与预处理》P19的第一步安装文件的纠错,并对一些步骤进一步详解
(二)具体步骤
(1)直接在Ubuntu系统上的浏览器进行搜索安装
-
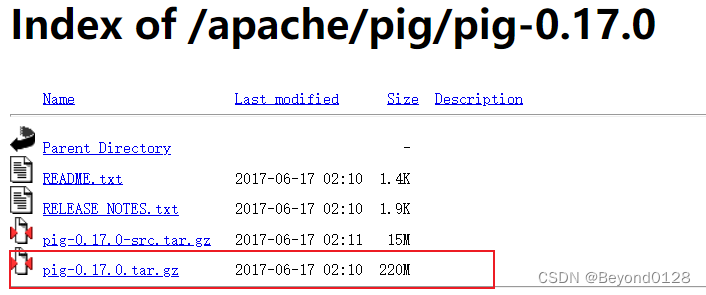
用Ubuntu浏览器打开如下链接,该链接是使用清华源镜像,相对下载较快
https://mirrors.tuna.tsinghua.edu.cn/apache/pig/pig-0.17.0/
选择如下pig-0.17.0.tar.gz进行下载
-
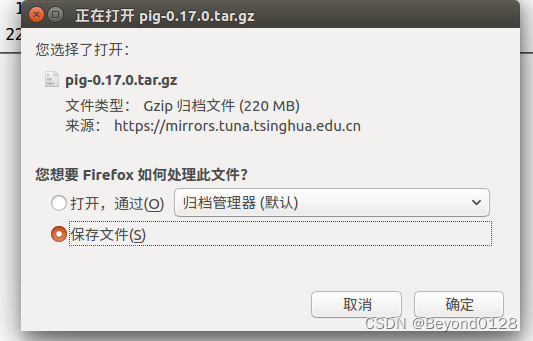
P.S.这里斗胆纠正一下书上的小问题(可能不是错只是单纯的不适合),书上建议是下载pig-0.17.0.-src.tar.gz文件(这是源码文件),如果按照书本上的文件下载,会在最后运行Pig的时候出现摘不到某文件位置的报错。

因此我们这里选择pig-0.17.0.tar.gz进行下载
关于pig-0.17.0.-src.tar.gz和pig-0.17.0.tar.gz的区别,简单的说

(2)点击下载并在下载目录下查看
(3)将文件进行解压和重命名
此处文件不可直接右击解压或者重命名,因为未具有权限,因此需要终端进行操作
-
进入到文件存放目录,然后将文件解压到指定目录下(默认为/usr/local)

-
转到解压好的文件目录下后,进行重命名为pig

(4)对于环境配置文件的改写,较容易出错!!
首先再终端里输入
sudo vim ~/.bashrc
跳出文件,该文件有比较固定的输入和修改方式

因此,首先输入 i
输入如下的内容

一定要找准蓝色划横线地方的路径是自己的机子上对应的(路径+名称)
之后按Esc,再输入:wq,并回车即保存退出
最后再继续在终端里出入
source ~/.bashrc
无报错即可。
(5)验证Pig安装是否成功
两个终端分别输入
pig -x local 以及 pig -x mapreduce
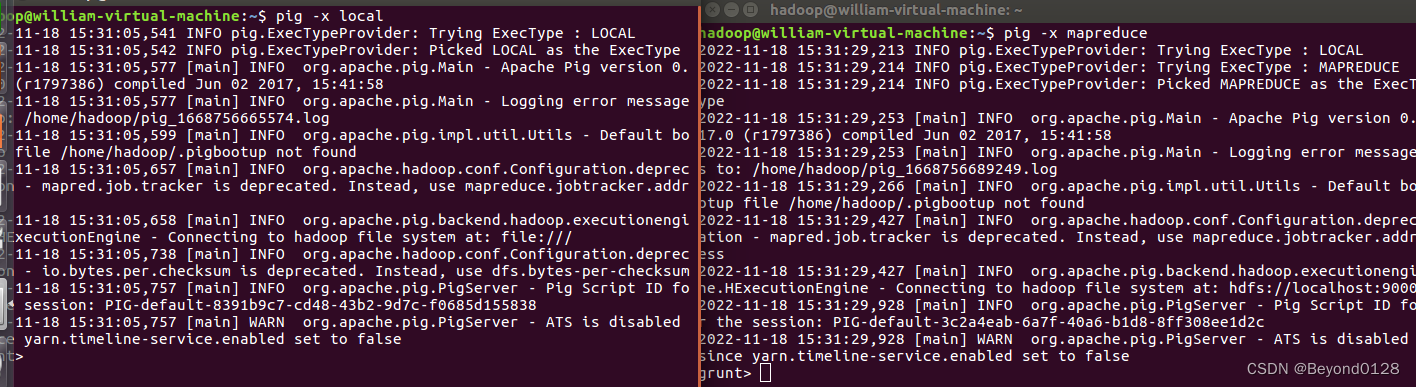
搞定~

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)