关于redis哨兵集群依次启动sentinel 几秒钟后都出现 +sdown sentinel的解决方案
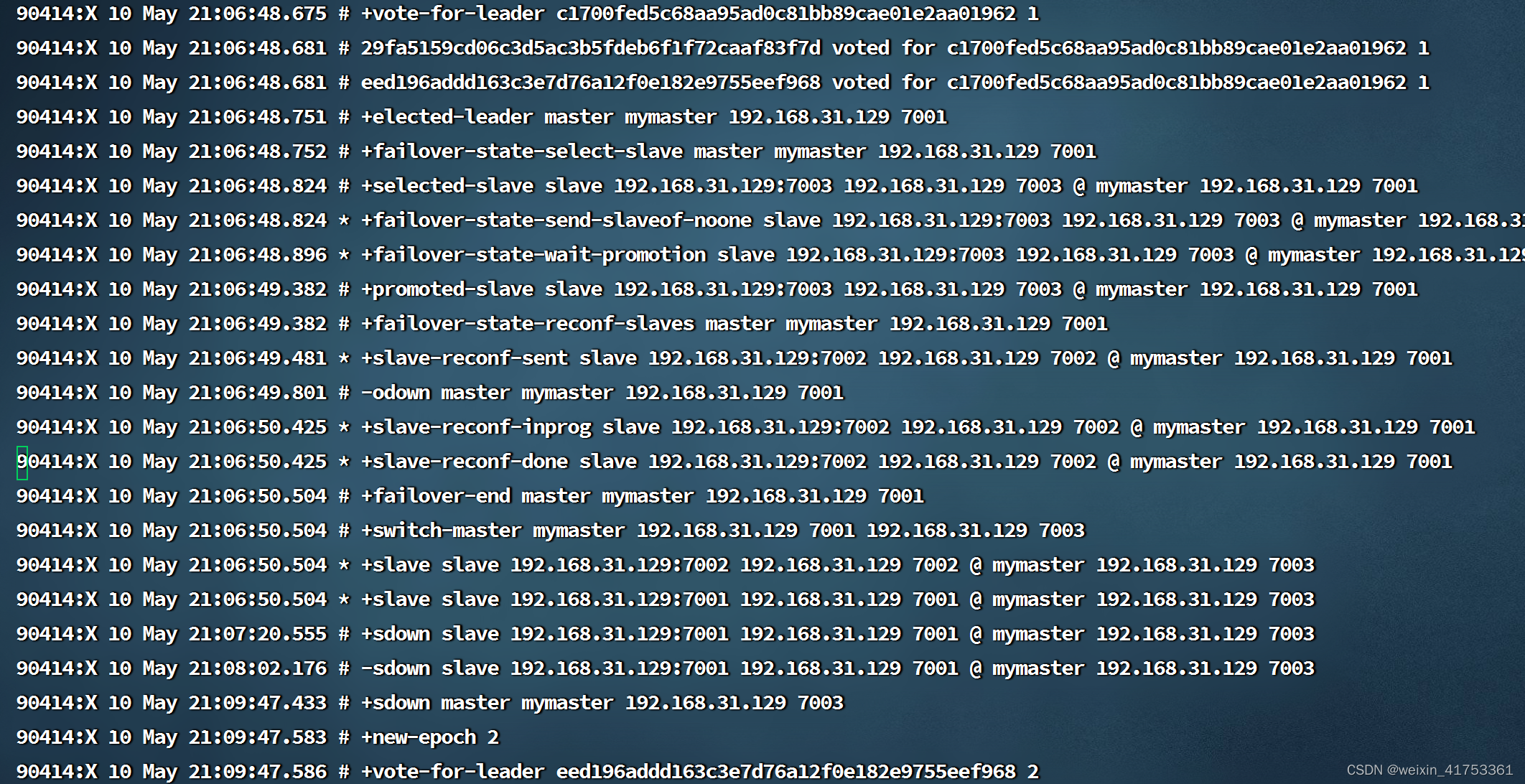
本文章主要是记录本人实战过程中遇到的问题。有雷同情况可供参考。应用场景:1.搭建redis主从集群(3个)2.搭建redis哨兵集群(3个)3.启动所有redis主从节点4.启动所有哨兵5.关闭redis主从集群中的主节点,查看哨兵日志是否会重新选举主节点问题就出现在这里:刚开始时我发现主节点停止后,每个哨兵都显示主节点sdown,也就是主观下线,但是没有一个哨兵节点显示oldown(客观下线),
本文章主要是记录本人实战过程中遇到的问题。有雷同情况可供参考。
应用场景:
1.搭建redis主从集群(3个)
2.搭建redis哨兵集群(3个)
3.启动所有redis主从节点
4.启动所有哨兵
5.关闭redis主从集群中的主节点,查看哨兵日志是否会重新选举主节点
问题就出现在这里:
刚开始时我发现主节点停止后,每个哨兵都显示主节点sdown,也就是主观下线,但是没有一个哨兵节点显示oldown(客观下线),这样也就不会进入重新选举主节点环节。
后来经过排查发现在所有哨兵启动成功后就出现了+sdown sentinel XXX的问题

也就是当前哨兵认为其他两个哨兵已经下线了,这样彼此之间就不能进行通讯了,所以一直达不到配置的quorum数量(我这里配置的2,因为彼此无法通讯,所以一直是1),这样就导致了无法进行重新选举。
那找到问题了所在,接下来就是解决问题,查了很多资料,后来对哨兵的sentinel.conf修改成了如下配置:
# bind 127.0.0.1 192.168.1.1
#关键所在
protected-mode no
#当前哨兵端口
port 27001
#本机ip,要配置
sentinel announce-ip 192.168.31.129
dir /root/application/redis-cluster/s1
sentinel monitor mymaster 192.168.31.129 7001 2
sentinel down-after-milliseconds mymaster 30000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
其他的哨兵配置修改下端口和目录位置即可。
这样再启动就可以了。
注意:哨兵的配置文件再启动后会写入和更改一些东西。建议清空里面的内容再复制上。
好了,就记录到这。有什么问题欢迎提问。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)