Elasticsearch是什么?
Elasticsearch系列(一)文章目录Elasticsearch系列(一)前言什么是全文检索?Elasticsearch如何检索?Lucene是什么?分词器倒排索引Elasticsearch总结前言如果读者打开这篇博文,我相信你一定和软件开发有关联,在说Elasticsearch是什么之前,我们先来回顾一下在日常开发中我们是如何存储数据?是的,你大脑肯定在思索传统数据库mysql,oracl
Elasticsearch系列(一)
前言
如果读者打开这篇博文,我相信你一定和软件开发有关联,在说Elasticsearch是什么之前,我们先来回顾一下在日常开发中我们是如何存储数据?是的,你大脑肯定在思索传统数据库mysql,oracle和nosql数据库redis,MongoDB,memcached等都可以存储数据啊,没错,但是它们都有一个特点就是只能处理结构化数据,面对非结构化数据就很难实现了,虽然mysql,oracle也有对应的全文检索功能但是面对海量数据,个性化的检索显得有点力不从心。然而现在是一个大数据时代,在这千钧一发之际分布式全文检索引擎诞生了,它就是Elasticsearch简称ES。它是一个支持PB数量级,近实时搜索的企业级引擎。官网解释:Elasticsearch 是一个分布式、可扩展、近实时的搜索与数据分析引擎。
什么是全文检索?
全文检索就是对整个文本文档进行全文匹配。比如现有10片文章,我想在10篇文章中搜索所有写到“李白”的文章,实现方法是对每一篇文章第一个个字到最后一个字进行全文匹配,只要存在“李白”两字说明是我们想要的文章。是不是很简单?是的,这样做如果文章字数小还实现,但要是有上千字甚至上万字,那这个工作量可想而知。
Elasticsearch如何检索?
Elasticsearch在PB数量级下任然能做到秒级查询,这也是它为何成为当前主流的搜索引擎之一。市场上以之对应的还有solr搜索引擎,但无论是性能还是使用上都比不上Elasticsearch。Elasticsearch是如何检索呢?在说原理之前我们先来说它的核心组件Lucene是什么?
Lucene是什么?
Lucene是用java语言写的搜索引擎库,是Apache开源框架,所以Lucene只能应用在java项目中,配置很复杂,不支持分布式的搜索引擎库。它是通过分词器和倒排索引相结合实现全文检索。如果想详细了解Lucene请移步官网
分词器
分词器很好理解,就是将一个文本按某种规则将所有文字拆分为多个关键字,词或句子。如默认分词器将文本以单个字或字母进行拆分,然后记录它们在文本中出现的位置和数量。
倒排索引
将所有文档根据分词器拆分的关键词条组成一个索引,这个就叫倒排索引。来一个栗子:假如现有三份数据文档,文档的内容如下分别是:
Java is the best programming language.
PHP is the best programming language.
Javascript is the best programming language.
如下事务数据结构就叫倒排索引
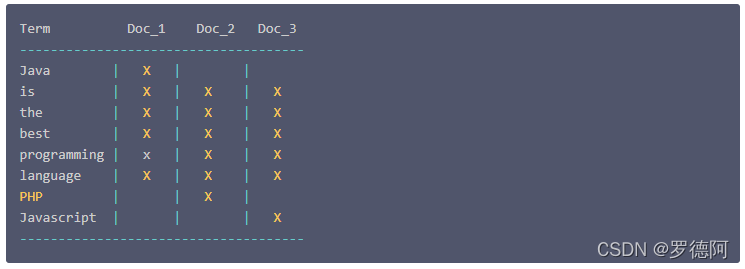
根据上面可知,当我们搜索java关键字时很快就能找到Doc_1,当我们搜索is关键字时很快就能找到Doc_1,Doc_2,Doc_3,只要能维护一个倒排索引,我们就能轻松实现全文检索。这就是全文检索的核心。
Elasticsearch
Elasticsearch是使用Lucene来实现的一个支持分布式,高可用和高性能的产品,它和语言无关通过restfull API来调用相关功能即可。天生支持数据分片(类似mysql的分库分表),多节点协调工作,自动故障转移等分布式特性,指之成为市场上最主流的全文搜索引擎。
总结
理解Elasticsearch是什么,首先要知道什么是搜索引擎?什么是分词器?什么是倒排索引?。有任何疑问请给博主留言,期待你宝贵的意见。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)