Flink大数据实时标签实时ETL -- 项目介绍1
Flink实时标签,实时ETL
1、前言
随着互联网3.0的到来,数据也井喷式爆发。随着大数据的到来,谁能拿到数据,用好数据也就成了重中之重。本次文章与大家分享的一个实际生产中的实时计算实时ETL项目。
2、背景
想必大家也都知道离线计算的标签。离线标签采用的是T+1的形式。这就具有一个很大的滞后性,对于新用户的一些策略以及营销就不好精准触达。基于这样的场景以及实时标签以及实时ETL需求项目也就出现了。
3、项目介绍
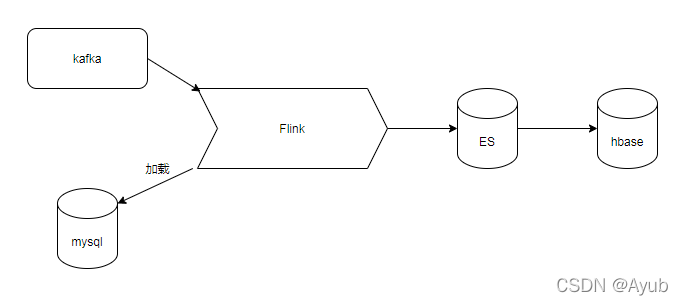
1、用户的操作日志数据(埋点数据),发送至kafka (其实埋点数据也是有一个合并Flink程序)。
2、运营人员在大数据平台配置好规则(如新用户,浏览了某一个页面...),存入mysql。
3、Flink代码定时(新增规则也能及时加载)加载mysql规则广播状态,根据规则处理日志。
4、将满足规则的数据存入ES(clickhouse)中,这是为了使用SQL进行统计。
5、Flink同时在根据mysql定义的规则处理数据(如新用户,浏览...),同时需要结合ES(clickhouse)查询。将满足要求的用户打上标签(特定规则有特定的标签)存入hbase中。
6、搭建API接口,开放给其他平台使用。
7、整个流程就是加载规则和处理规则,存入满足规则的用户,打上标签。
8、整个项目给运营人员提供了较好时效决策。
4、项目架构
Kafka + Flink + ElasticSearch(clickhouse) + Mysql + Hbase
5、数据流程图
6、项目展示
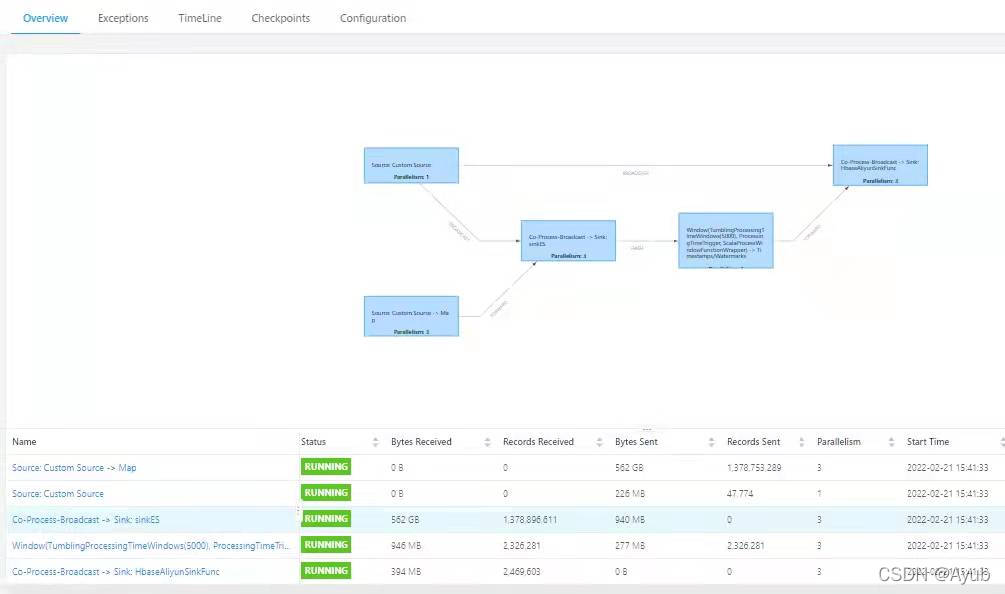
数据处理支持上百G,并行度3。代码中可以优化状态重试判断,触发器等
7、传送门
下面我将通过主类进行逐个介绍代码的实现。
Flink大数据实时标签实时ETL -- 主类代码介绍2![]() https://blog.csdn.net/AyubLIbra/article/details/116277519
https://blog.csdn.net/AyubLIbra/article/details/116277519
Flink大数据实时标签实时ETL --03加载规则类 (source Mysql)![]() https://blog.csdn.net/AyubLIbra/article/details/116278064
https://blog.csdn.net/AyubLIbra/article/details/116278064
后续在更新,同时也会展示代码,静待后面代码。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)