ElasticSearch 文档的添加、获取、更新、删除_05
文章目录新建文档获取文档批量获取文档更新查询更新删除文档批量操作新建文档首先新建一个索引。然后向索引中添加一个文档:PUT blog/_doc/1{"title":"6. ElasticSearch 文档基本操作","date":"2021-12-07","content":"首先新建一个索引。"}1 表示新建文档的 id。添加成功后,响应的 json 如下:{"_index" : "blog",
新建文档
首先新建一个索引。
然后向索引中添加一个文档:
PUT blog/_doc/1
{
"title":"6. ElasticSearch 文档基本操作",
"date":"2021-12-07",
"content":"首先新建一个索引。"
}
1 表示新建文档的 id。
添加成功后,响应的 json 如下:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
- _index 表示文档索引。
- _type 表示文档的类型。
- _id 表示文档的 id。
- _version 表示文档的版本(更新文档,版本会自动加 1,针对一个文档的)。
- result 表示执行结果。
- _shards 表示分片信息。
- _seq_no 和 _primary_term 这两个也是版本控制用的(针对当前 index)。
添加成功后,可以查看添加的文档:
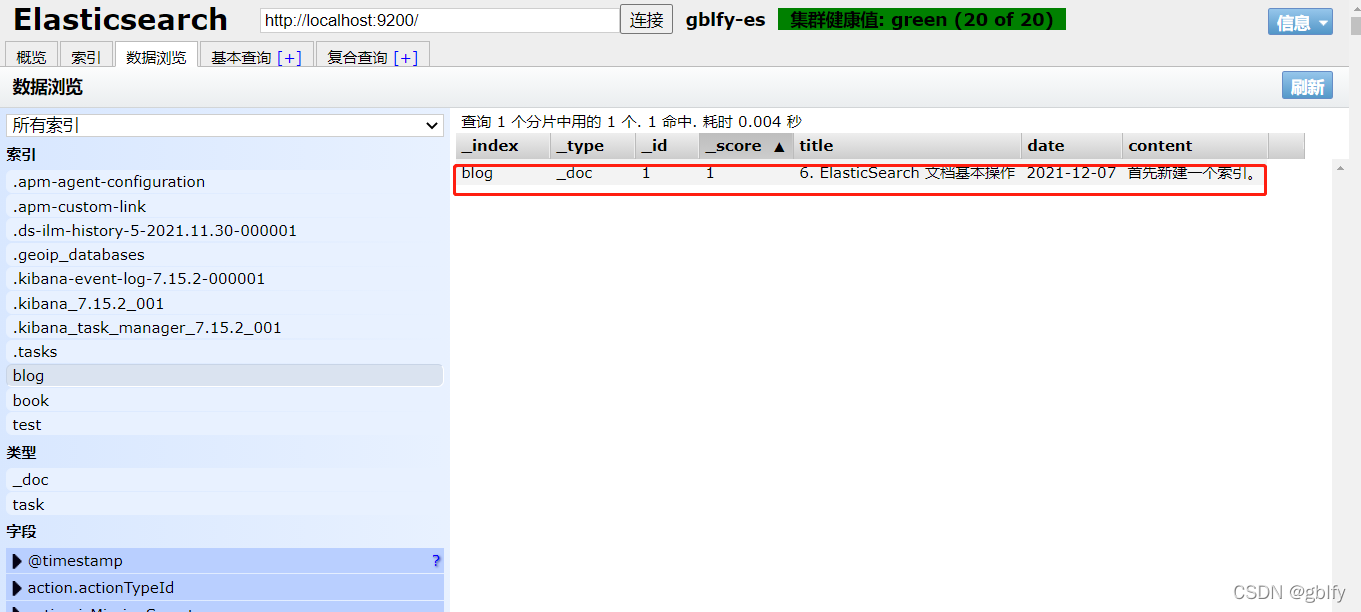
当然,添加文档时,也可以不指定 id,此时系统会默认给出一个 id,如果不指定 id,则需要使用 POST 请求,而不能使用 PUT 请求。
POST blog/_doc
{
"title":"666",
"date":"2020-11-05",
"content":"首先新建一个索引。"
}
获取文档
Es 中提供了 GET API 来查看存储在 es 中的文档。使用方式如下:
GET blog/_doc/1
上面这个命令表示获取一个 id 为 1 的文档。
如果获取不存在的文档,会返回如下信息:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "6. ElasticSearch 文档基本操作",
"date" : "2021-12-07",
"content" : "首先新建一个索引。"
}
}
如果仅仅只是想探测某一个文档是否存在,可以使用 head 请求:
如果文档不存在,响应如下:
HEAD blog/_doc/2

HEAD blog/_doc/1
如果文档存在,响应如下:

批量获取
当然也可以批量获取文档。
GET blog/_mget
{
"ids":["1","2"]
}
文档更新
- 普通更新
注意,文档更新一次,version 就会自增 1。
可以直接更新整个文档:
PUT blog/_doc/1
{
"title":"666"
}
这种方式,更新的文档会覆盖掉原文档。
- 大多数时候,我们只是想更新文档字段,这个可以通过脚本来实现。
POST blog/_update/1
{
"script": {
"lang": "painless",
"source":"ctx._source.title=params.title",
"params": {
"title":"666666"
}
}
}
更新的请求格式:POST {index}/_update/{id}
在脚本中,lang 表示脚本语言,painless 是 es 内置的一种脚本语言。source 表示具体执行的脚本,ctx 是一个上下文对象,通过 ctx 可以访问到 _source、_title 等。
也可以向文档中添加字段:
POST blog/_update/1
{
"script": {
"lang": "painless",
"source":"ctx._source.tags=[\"java\",\"php\"]"
}
}
GET blog/_doc/1

通过脚本语言,也可以修改数组。例如再增加一个 tag:
POST blog/_update/1
{
"script":{
"lang": "painless",
"source":"ctx._source.tags.add(\"js\")"
}
}
当然,也可以使用 if else 构造稍微复杂一点的逻辑。
POST blog/_update/1
{
"script": {
"lang": "painless",
"source": "if (ctx._source.tags.contains(\"java\")){ctx.op=\"delete\"}else{ctx.op=\"none\"}"
}
}
查询更新
通过条件查询找到文档,然后再去更新。
例如将 title 中包含 666 的文档的 content 修改为 888。
POST blog/_update_by_query
{
"script": {
"source": "ctx._source.content=\"888\"",
"lang": "painless"
},
"query": {
"term": {
"title":"666"
}
}
}
删除文档
- 根据 id 删除
从索引中删除一个文档。
删除一个 id 为 1的文档。
DELETE blog/_doc/1
如果在添加文档时指定了路由,则删除文档时也需要指定路由,否则删除失败。
- 查询删除
查询删除是 POST 请求。
例如删除 title 中包含 666 的文档
POST blog/_delete_by_query
{
"query":{
"term":{
"title":"666"
}
}
}
也可以删除某一个索引下的所有文档:
POST blog/_delete_by_query
{
"query":{
"match_all":{
}
}
}
批量操作
es 中通过 Bulk API 可以执行批量索引、批量删除、批量更新等操作。
首先需要将所有的批量操作写入一个 JSON 文件中,然后通过 POST 请求将该 JSON 文件上传并执行。
例如新建一个名为 aaa.json 的文件,内容如下:

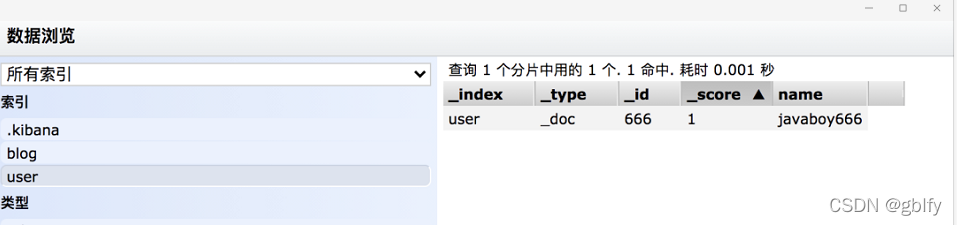
首先第一行:index 表示要执行一个索引操作(这个表示一个 action,其他的 action 还有 create,delete,update)。_index 定义了索引名称,这里表示要创建一个名为 user 的索引,_id 表示新建文档的 id 为 666。
第二行是第一行操作的参数。
第三行的 update 则表示要更新。
第四行是第三行的参数。
注意,结尾要空出一行。
aaa.json 文件创建成功后,在该目录下,执行请求命令,如下:
curl -XPOST "http://localhost:9200/user/_bulk" -H "content-type:application/json" --data-binary @aaa.json
执行完成后,就会创建一个名为 user 的索引,同时向该索引中添加一条记录,再修改该记录,最终结果如下:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)