kafka线上问题运维总结
1.kafka某节点kafka数据磁盘被写满现象:磁盘被写满后kafk挂掉无法启动。解决办法:如果有过期日志删除过去日志,再重启。如果没有过期日志,缩短此节点日志保存时间,删除不在保留时间内的日志。...
Kafka常用JMX监控指标整理
2.0版本
bin/kafka-run-class.sh kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://kafka1:9999/jmxrmi --object-name kafka.server:type=ReplicaManager,name=IsrShrinksPerSec
调优
技术实战 |《Apache Kafka实战》作者胡夕:Apache Kafka监控与调优
千亿级数据量kafka集群性能调优实战总结
kafka集群规划
kafka生产者Producer参数设置及参数调优建议
参考价值很大
kafka生产者Producer参数设置及参数调优建议-商业环境实战系列
1.kafka某节点kafka数据磁盘被写满
现象:磁盘被写满后kafk挂掉无法启动。
解决办法:如果有过期日志删除过去日志,再重启。如果没有过期日志,缩短此节点日志保存时间,删除不在保留时间内的日志。
2.客户端连接超时
1.根据异常内容定位客户端源码,分析客户端代码
2.抓包分析
kafka 通过tcp/ip协议建立链接,在linux使用tcpdump命令抓包然后用抓包工具(Wireshark)在windos上分析抓到的数据。
3.close wait过多导致broker网络不通,从而Kafka产生问题
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'

4.kafka 坏盘导致leader不存在问题分析
文档:kafka 坏盘导致leader不存在问题分析…
链接:http://note.youdao.com/noteshare?id=bdc2978c3b5148059f3067201085c8e4&sub=1D34AD65F05E40A4AABA5C2C75B44633
5.动态增加副本
Kafka动态增加Topic的副本
前提:acks=all,副本数=3
保证数据可靠性
生产者设置
acks=all
retries=2147483647
delivery.timeout.ms=2147483647
集群设定
unclean.leader.election.enable=false
default.replication.factor=3 # 默认创建topic的副本数
min.insync.replicas=2 #最小可是使用的isr数
offsets.topic.replication.factor=3 #内部topic __consumer_offsets 的副本数(默认50个分区,3个副本)
transaction.state.log.replication.factor=3
transaction.state.log.min.isr>=2
如果要提高数据的可靠性,在设置request.required.acks=-1的同时,也要min.insync.replicas这个参数(可以在broker或者topic层面进行设置)的配合,这样才能发挥最大的功效。min.insync.replicas这个参数设定ISR中的最小副本数是多少,默认值为1,当且仅当request.required.acks参数设置为-1时,此参数才生效。如果ISR中的副本数少于min.insync.replicas配置的数量时,客户端会返回异常:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
消费者设置
enable.auto.commit=false
6.kafka的broker id改变导致的问题
如果你想改kafka的broker id,比如第一遍写错了,应该遵循两个步骤:
- 改server.prorperties文件配置;
broker.id=121
log.dirs=/root/kafka-acl/kafka/data
- 改meta.properties,默认情况下,应该在/tmp/kafka-logs目录下;
同时需注意数据存在多个目录时,需要修改多个目录的meta.propertie。
vi /root/kafka-acl/kafka/data/meta.propertie
#Tue Dec 29 14:36:11 CST 2020
version=0
broker.id=121
7.kafka producer写入超时
现象:
kafka producer一开始写入正常,慢慢的会大量超时异常,偶尔正常写入;在callback函数打印异常信息为
org.apache.kafka.common.errors.TimeoutException: Expiring 2 record(s) for testTopic-0 due to 64534 ms has passed since batch creation plus linger time
原因:
producer send方法的callback函数执行缓慢导致;
producer往broker发送数据时是串行的,只有上次batch全部写入broker,并且全部callback函数执行完毕后,才会继续下一次发送。如果上一次发送全部callback函数执行时间超过了request.timeout.ms(30s),就会导致后续batch的message发送时间大于创建时间30s以上,然后被producer丢弃并抛出异常;
方法:
1.加大request.timeout.ms值;
2.调整callback,使得batch的callback执行时间在request.timeout.ms之内;
8.ISR抖动
现象:
无法消费kafka。
中往kafka写消息报错
查看集群:
ISR缺失严重
bin/kafka-topics.sh --zookeeper hdp1:2181/kafka --describe --under-replicated-partitions
2.0版本
bin/kafka-run-class.sh kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://hdp1:9999/jmxrmi --object-name kafka.server:type=ReplicaManager,name=IsrShrinksPerSec
调整副本同步leader数据的线程数
num.replica.fetchers #leader中进行复制的线程数,增大这个数值会增加relipca的IO
默认是单线程,当时增加到2或者4…
由于数据量比较庞大,且此broker正在重启,kafka server.log报错如下,属于正常
9.消费异常
现象:
在生产端割接后,数据量增大20%,消费速度直降,consumer.group脚本查询不出,无法得知lag等偏移量信息
jmx中指标中kafka空闲度低于30%,基本都在10%以下,更甚2%,1%,,证明kafka内部非常繁忙,调大JVM参数至40G依旧不见好转
排查集群:
网络空闲度:
查看平均网络处理空闲时间低于0.3
0.10版本
bin/kafka-run-class.sh kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://hdp1:9999/jmxrmi --object kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent
2.0版本
bin/kafka-run-class.sh kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://hdp1:9999/jmxrmi --object-name kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent
磁盘IO空闲度
2.0版本
bin/kafka-run-class.sh kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://hdp1:9999/jmxrmi --object-name kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent
调整参数:
num.network.threads:(网络i/o)
server用来处理网络请求的网络线程数目。增大能够增加处理网络io请求,但不读写具体数据,基本没有io等待。过大,会带来线程切换的开销
用于接收并处理网络请求的线程数,默认为3。其内部实现是采用Selector模型。启动一个线程作为Acceptor来负责建立连接,再配合启动num.network.threads个线程来轮流负责从Sockets里读取请求,一般无需改动,除非上下游并发请求量过大。
num.io.threads:(文件i/o)
server用来处理请求的磁盘文件I/O线程的数目。这个线程数目至少要等于硬盘的个数。过大,会带来线程切换的开销
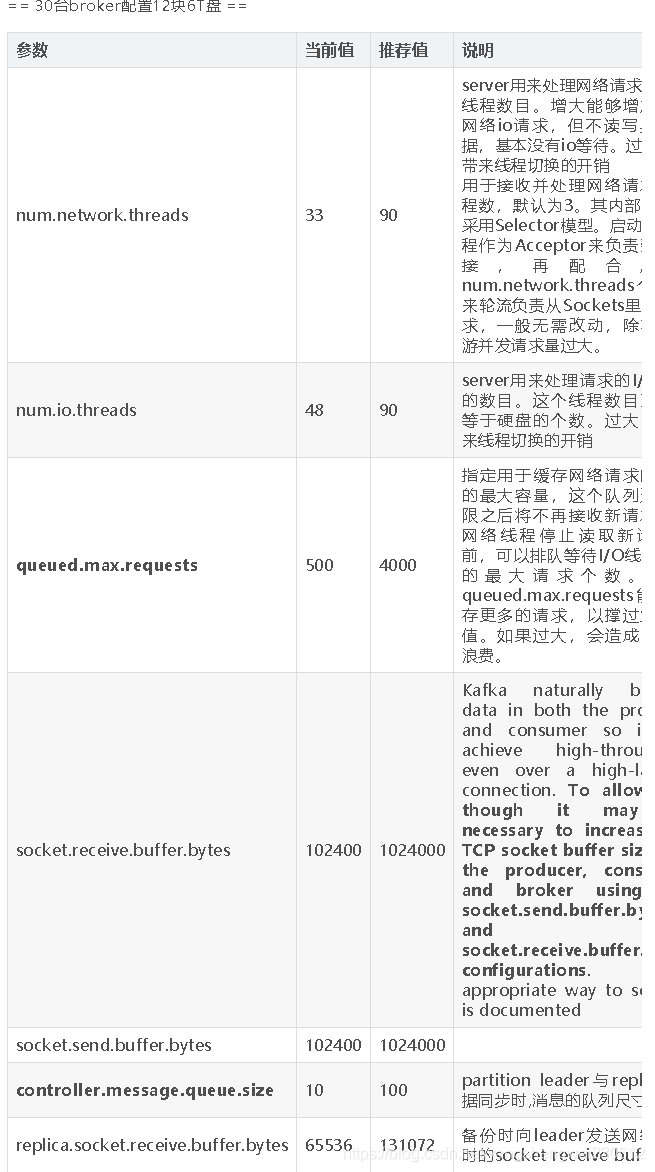
经过参数的加大,发现生产端与消费端都可以正常运行了
10.producer发送失败
producer参数 buffer.memory 设置(吞吐量)
该参数用于指定Producer端用于缓存消息的缓冲区大小,单位为字节,默认值为:33554432合计为32M。kafka采用的是异步发送的消息架构,prducer启动时会首先创建一块内存缓冲区用于保存待发送的消息,然后由一个专属线程负责从缓冲区读取消息进行真正的发送。
商业环境推荐:
消息持续发送过程中,当缓冲区被填满后,producer立即进入阻塞状态直到空闲内存被释放出来,这段时间不能超过max.blocks.ms设置的值,一旦超过,producer则会抛出TimeoutException 异常,因为Producer是线程安全的,若一直报TimeoutException,需要考虑调高buffer.memory 了。
用户在使用多个线程共享kafka producer时,很容易把 buffer.memory 打满。
11.kafka客户端 TIME_WAIT状态过多问题
12.发送客户端disconnected
测试发送使用一个客户单连续发送10000000消息出现几次disconnected ,增加request.tiomeout.ms(默认30s)时间
根据实际情况调整
props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);
Received invalid metadata error in produce request on partition test-1p-1f-2-0 due to org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received… Going to request metadata update now


13.部分的 consumer 不能消费
非自己实际碰到问题:网上借鉴
https://blog.csdn.net/waneyongfu/article/details/101375531?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
先是多个broker宕机重启后导致部分消费客户端不能消费频繁打印
Attempt to join group xxxx failed due to obsolete coordinator information, retrying.
快速解决办法:给更换消费组名
14.Kafka消费组运维详解
15.TCP面试官居然把TCP三次握手四次挥手问的这么详细
网络 卧槽!牛皮了,面试官居然把TCP三次握手四次挥手问的这么详细
16. Marking Coordinator Dead!
https://blog.csdn.net/yangshengwei230612/article/details/118523657
分区重分配可能出现的问题和排查问题思路
OOM内存溢出

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)