
HBase是怎样找到某个rowkey
【摘要】 本文介绍HBase根据时间戳和查询列信息对HFile做一次过滤,缩小查询范围,查找rowkey的处理过程。1 定位到某个region内的storeHBase的 Hmaster会处理并分配region分区(根据rowKwy),相应的元数据都会存在Zookeeper里面。其中每个region的元数据中 都会存储两个属性:start-key 和 end-key,根据这个区间就能查到rowKey
【摘要】 本文介绍HBase怎样定位到某个rowKey的region分区和store。再根据时间戳和查询列信息对HFile做一次过滤,缩小查询范围,查找rowkey的处理过程。
1 定位到某个region内的store
HBase的 Hmaster会处理并分配region分区(根据rowKwy),相应的元数据都会存在Zookeeper里面。其中每个region的元数据中 都会存储两个属性:start-key 和 end-key,根据这个区间就能查到rowKey对应在哪个region。
region里再根据不同的列族(Column Family)存在不同的store里面(最新的数据存在mem store,较老的存在HFile)。Mem store也是个区间,存在内存中,可以很快判断在不在mem store里。而如果分区中这个列族数据比较多,超过Mem store的阈值(一般是100M~200M),就会刷到磁盘中,即多个HFile(key-value的格式)中。
如果创建表时,指定了BloomFilter,那么就根据BloomFilter快速的判断该rowkey是否在这个HFile中。
HFile 底层一般是: 布隆过滤器 + 多层索引结构。就能够快速确定并查找到某个rowKey对应的详细记录!
(如果想一般了解,到这里可以返回了,接下来是详细过程预警)
但BloomFilter也会存在错误率(这个和布隆过滤器的设计原理有关,一次存读对应一组hash散列值,存的数据较多时,原本不存在的某数据的一组哈希值也可能都被写为1,即判定其存在)。
所以主要来讨论下: 不使用BloomFilter下,是如何查找到rowkey在哪个HFile下。
2 从Store中定位到某个HFile
HBase首先根据时间戳和查询列的信息对file做一次过滤,将查询范围缩小。仍然需要扫描其余的文件,因为storeFile之间是无序的,而且HFile的rowkey范围会有交叉,所以并不会按照HFile顺序的查找。过程如下(将目标rowKey 标记为 targetRowKey):
- 预处理。HBase会先查每个HFile中的最小的rowkey,按照小到大的ASC排序后,将结果放到一个队列中(存HFile名,和 当前筛选最小的rowkey 暂记作:minRowKey i。i代表在队列中的排序,i=0 表示是 队列中的头结点)。
- 初次筛选。只扫描队列中MinRowKey i 比 targetRowKey 小的 HFile
- 具体筛选。接下来过程 类似归并排序:
- 先poll()取出队列的 头结点HFile,再从 头结点HFilee中读取一条记录(记作nextRowKey:minRowKey0的下一条记录);
- nextRowKey==targetRowKey则返回,不是则继续;如果 nextRowKey大于targetRowKey,则将此Hfile从队列的目标区域中移出,不是则继续:
- 因为队列的比较顺序是比较的每个HFile的第一条符合要求的rowkey。所以,hbase会继续从队列中 剩下的HFile取第一条记录 minRowKey1,把该记录与 头结点HFile 的第二条记录nextRowKey做比较: 如果前者大,则 MinRowKey0 = nextRowKey ;如果后者大,则MinRowKey0 = nextRowKey,再把 头结点HFile 放回队列重新排序,在重新取队列的头HFile。
- 然后重复上面的过程4 、5、 6,直到找到targetRowKey 所在的HFile。
范围缩小到该HFile后,就根据HFile文件中的索引去定位到块,快速的找到对应的详细记录。单个HFile文件中的索引主要是根据索引块的大小来提升速率。
3 普通 HFile查找 的 性能分析
Region下单个HFile文件数越多,一次查询就会需要更多的IO操作,延迟必然会越来越大。
如下图一所示,随着数据写入不断增加,文件数不断增多,读取延时也在不断变大。
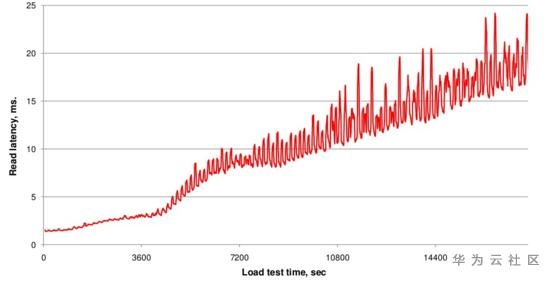
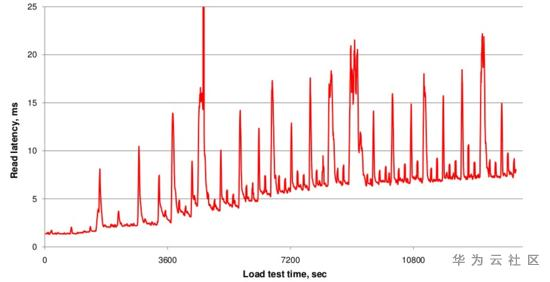
文件数基本稳定,进而IO Seek次数会比较稳定,延迟就会稳定在一定范围。下图是不断写入数据,hfile数量变多,不断Compaction合成大文件,文件数量基本稳定,查询时延也基本稳定
4 HFile结构
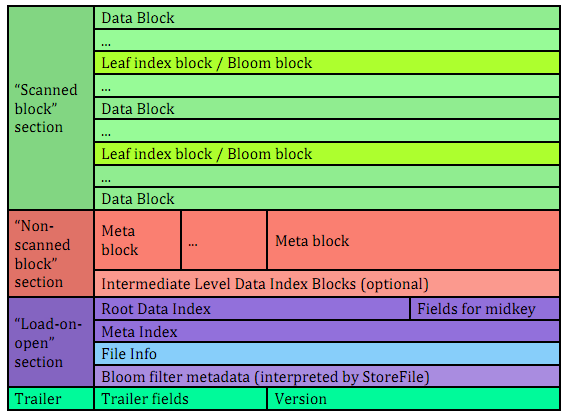
文件主要分为四个部分:Scanned block section,Non-scanned block section,Load-on-open-section和Trailer。
- Scanned block section:顾名思义,表示顺序扫描HFile时所有的数据块将会被读取,包括Leaf Index Block,Data Block 和 Bloom Block。
- Non-scanned block section:表示在HFile顺序扫描的时候数据不会被读取。主要包括Meta Block 和 Intermediate Level Data Index Blocks 两部分。
- Load-on-open-section:这部分数据在 HBase 的 region server启动时,需要加载到内存中。包括 FileInfo、Bloom filter block、root data index 和 meta index。
- Trailer:这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
HFile的数据块,元数据块通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO。
下图中,上三层为索引层。在数据量不大时只有最上面一层,数据量大了之后开始分裂为多层,最多三层,如下图所示。
最下面一层为数据层,存储用户的实际keyvalue数据。这个索引树结构类似于InnoSQL的聚集索引,只是HBase并没有辅助索引的概念。

图中红线表示一次查询的索引过程(HBase中相关类为HFileBlockIndex和HFileReaderV2),基本流程可以表示为:
- 用户输入rowkey为fb,在root index block中通过二分查找定位到fb在’a’和’m’之间,因此需要访问索引’a’指向的中间节点。因为root index block常驻内存,所以这个过程很快。
- 将索引’a’指向的中间节点索引块加载到内存,然后通过二分查找定位到fb在index ‘d’和’h’之间,接下来访问索引’d’指向的叶子节点。
- 同理,将索引’d’指向的中间节点索引块加载到内存,一样通过二分查找定位找到fb在index ‘f’和’g’之间,最后需要访问索引’f’指向的数据块节点。
- 将索引’f’指向的数据块Data Block 加载到内存,通过遍历的方式 找到对应的 key-value。
上述流程中因为 中间节点、叶子节点 和 数据块 都需要加载到 内存,所以I/O次数正常为3次。但是实际上HBase为block提供了缓存机制,可以将频繁使用的数据块block缓存在内存中,可以进一步加快实际读取过程。 所以:
- 在HBase中,通常一次随机读请求会产生 最多 3次 I/O;
- 如果数据量小(只有一层索引),数据已经缓存到了内存,就不会产生IO;
- 如果是频繁查找的数据块内,也不会产生I/O。
原文地址:https://blog.csdn.net/Du939/article/details/118212810 from 士弘毅
本文参考(借鉴并修正): https://bbs.huaweicloud.com/blogs/192853

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)