大数据常用实时流处理方式(Kafka+SparkStream or ETL+Kudu)
这两天刚完成一个项目,我有个习惯就是完了项目做一下总结和复盘正好这两天没有事情,根据项目顺手做了一个Demo,算是对项目做一个实例化吧。项目核心:展现实时数据流的处理方式整体流程:Java模拟数据,发送到UDP↓......
这两天刚完成一个项目,我有个习惯就是完了项目做一下总结和复盘
正好这两天没有事情,根据项目顺手做了一个Demo,算是对项目做一个实例化吧。
一、项目流程
项目核心:展现实时数据流的常规处理方式
整体流程:

规划项目流程后,我们便可以对其进行一一拆分实现。
二、模拟数据发送到UDP
UDP是参考模型中一种无连接的传输层协议,它主要用于不要求分组顺序到达的传输中,分组传输顺序的检查与排序由应用层完成,提供面向事务的简单不可靠信息传送服务。
SCADA(Supervisory Control And Data Acquisition)系统,即数据采集与监视控制系统。SCADA系统是以计算机为基础的DCS与电力自动化监控系统;它应用领域很广,可以应用于电力、冶金、石油、化工、燃气、铁路等领域的数据采集与监视控制以及过程控制等诸多领域。
UDP在Scada系统中有一定的应用,故也可以作为实时数据流程中的一个小部分(如物理设备发送到指定端口,底层存储监听该端口获取数据)。
虽然是造数据,但是也要造的有模有样的~
设计了5列:time、date、id、name、value
其中,time精确到秒,date是日期(yyyy-mm-dd),id是递增的int类型,value是随机random的值产生的。
对这个稍加思索,我们不难发现,我们可以划分为三个类或方法,降低复杂度, 提高可读性。
分别是:
- 格式化日期类
- 获取随机值类
- 发送到UDP类
1. 格式化日期类
主要是获取当前时间戳,然后转为秒级数据和日期级数据。main方法是打印输出的,可省略。
package com.example.utils;
import java.text.SimpleDateFormat;
public class TimeStampFormat {
// 获取时间戳
private Long timestamp = System.currentTimeMillis();
// 时间戳转时间
public String getTime() {
SimpleDateFormat formatTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return formatTime.format(timestamp);
}
// 时间转日期
public String getDate() {
SimpleDateFormat formatTime = new SimpleDateFormat("yyyy-MM-dd");
return formatTime.format(timestamp);
}
public static void main(String[] args) {
String time = new TimeStampFormat().getTime();
String date = new TimeStampFormat().getDate();
System.out.println(time);
System.out.println(date);
}
}
2. 获取随机值类
getInt方法是后面造name的时候,有一个姓和名的数组,用于随便获取一个姓名的。
package com.example.utils;
public class GetRandom {
// 获取一个随机数
private double random = Math.random();
// 随机数转整数,用于当索引下标
public int getInt() {
return (int)(random * 10);
}
// 随机数转固定位小数(6位)
public Double getDouble() {
return Double.valueOf(String.format("%.6f",random * 100));
}
public static void main(String[] args) {
System.out.println(new GetRandom().getInt());
System.out.println(new GetRandom().getDouble());
System.out.println(new GetRandom().random);
}
}
3. 发送到UDP类
最开始是把发送方法直接写到main当中的,但是还是抽成一个方法了,比较直观。
Tips:这个send方法基本上就是两个new ,一个send,一个close。对资源的占用和消耗比较大,其实可以换一种方式,减小Java创建对象开销。
package com.example.service;
import com.example.utils.GetRandom;
import com.example.utils.TimeStampFormat;
import java.io.IOException;
import java.net.*;
import java.util.concurrent.TimeUnit;
public class SendToUDP {
// IP
private static String IP = "10.168.1.xx";
// private static String IP = "127.0.0.1";
// port
private static String PORT = "3927";
private static void send(byte[] sendValue) throws SocketException, UnknownHostException {
// 创建socket对象
DatagramSocket ds = new DatagramSocket();
// 打包数据
DatagramPacket datagramPacket = new DatagramPacket(sendValue, sendValue.length, InetAddress.getByName(IP), Integer.parseInt(PORT));
// send
try {
ds.send(datagramPacket);
} catch (IOException e) {
e.printStackTrace();
} finally {
ds.close();
}
}
public static void main(String[] args) throws InterruptedException, SocketException, UnknownHostException {
// 创建数据 1 时间戳;2 时间;3 ID;4 Name ;5 Values;
int i = 0;
String[] surNameList = "李、王、张、刘、陈、杨、赵、黄、周、吴".split("、");
String[] nameList = "梦琪、忆柳、之桃、慕青、问兰、尔岚、元香、初夏、沛菡、傲珊".split("、");
while (true) { // 一直发送数据
TimeStampFormat ts = new TimeStampFormat();
GetRandom rd = new GetRandom();
// 1 time
String time = ts.getTime();
// 2 date
String date = ts.getDate();
// 3 id
i ++ ;
// 4 Name name = surNameList[i] + nameList[index]
String name = surNameList[rd.getInt()] + nameList[rd.getInt()];
// 5 values
Double doubleValues = rd.getDouble();
// 拼接数据
byte[] sendValue = String.format("%s,%s,%s,%s,%s", time, date, i, name, doubleValues).getBytes();
System.out.println(String.format("%s,%s,%s,%s,%s", time, date, i, name, doubleValues));
send(sendValue);
// 休眠1纳秒再发送
TimeUnit.NANOSECONDS.sleep(1);
}
}
}
运行效果:

三、解析UDP发送到Kafka
这一块比较简单,直接配置Kafka Producer,然后将接收到的UDP包解析为逗号分隔的格式,发送到Kafka即可。
1. Kafka帮助类
package com.example.utils;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import java.util.Properties;
public class KafkaUtils {
public Producer getProducer() {
// 实例化配置类
Properties props = new Properties();
//集群地址,多个服务器用","分隔
props.put("bootstrap.servers", "10.168.1.xx:9092");
//key、value的序列化,此处以字符串为例,使用kafka已有的序列化类
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//props.put("partitioner.class", "com.kafka.demo.Partitioner");//分区操作,此处未写
props.put("request.required.acks", "1");
Producer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
return kafkaProducer;
}
public void closeRes(Producer kafkaProducer) {
if (kafkaProducer != null) {
try {
kafkaProducer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
2. 解析UDP,发送到Kafka
package com.example.dao;
import com.example.utils.KafkaUtils;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
public class ReceiveUDPSendToKafka {
public static void main(String[] args) throws IOException {
Logger.getLogger("org").setLevel(Level.INFO);
// 定义一个接收端
DatagramSocket ds = new DatagramSocket(3927);
// 获取Kafka配置
Producer producer = new KafkaUtils().getProducer();
while (true) {
// 接收数据
byte[] bytes = new byte[1024];
// dp
DatagramPacket dp = new DatagramPacket(bytes, bytes.length);
ds.receive(dp);
// 解析
byte[] data = dp.getData();
int length = dp.getLength();
//输出
String outData = new String(data, 0, length);
// System.out.println(outData);
// key
String key = outData.split(",")[2];
// ProducerRecord 这里需要三个参数,第一个:topic的名称,第二个参数:表示消息的key,第三个参数:消息具体内容
try {
producer.send(new ProducerRecord<String, String>("demoTopic", key, outData));
System.out.println("发送成功:" + outData);
} catch (Exception e) {
try {
new KafkaUtils().closeRes(producer);
} catch (Exception e1) {
e.printStackTrace();
}
}
}
}
}
Tips:这个监听…好像不能指定IP?所以想运行,需要将发送到UDP的地址改为本机,或者把解析UDP的程序打包到发送到UDP的IP服务器上运行。
运行效果:我是直接在Kafka上模拟消费者查看的:

四、SDC解析Kafka写入Kudu
StreamSets Data Collector(SDC)是目前最先进的可视化数据采集配置工具,非常适合做实时的数据采集,兼顾批量数据采集和不落地的数据ETL。如果您正在使用Flume、Logstash、Sqoop、Canal等上一代数据采集工具,推荐您使用SDC作为升级替换。
Apache Kudu 是一个开源分布式数据存储引擎,可以轻松地对快速变化的数据进行快速分析。兼顾OLAD和OLTP。
对于两种数据,我会考虑使用ETL完成。
- 数据源多的。例如需要把MySQL里面所有库的数据迁移到大数据平台
- 数据已经处理成结构数据,对实时性要求在秒级,且服务器资源富裕的情况。
第一种情况,数据太多,写代码的话,会有很多版,或者需要一个脚本去运行,所以我考虑用ETL;
第二种情况,使用可视化的ETL,会让我们对数据的整体流向有一个掌握,但是资源消耗大。
Tips:种草一个中文网站,很好用,很全。
StreamSets中文站:链接:http://streamsets.vip/
这一块,主要是用使用ETL对数据进行处理,可视化ETL,除了SDC,还有NIFI,非可视化的ETL可以考虑Sqoop和Flume。
1. 数据源

2. 处理器
由于在Kafka里面的数据是逗号分隔,直接用逗号作为分割符,然后绑定column名。

3. 输出源
先创建一个kudu表:
CREATE TABLE kafka_to_kudu(
id int,
point_date STRING,
point_time STRING,
name STRING,
value DOUBLE,
PRIMARY KEY (id,point_date))
PARTITION BY HASH (id) PARTITIONS 10,
RANGE (point_date) (
PARTITION "2021-07-19" <= VALUES < "2021-07-19\000",
PARTITION "2021-07-20" <= VALUES < "2021-07-20\000",
PARTITION "2021-07-21" <= VALUES < "2021-07-21\000",
PARTITION "2021-07-22" <= VALUES < "2021-07-22\000",
PARTITION "2021-07-23" <= VALUES < "2021-07-23\000",
PARTITION "2021-07-24" <= VALUES < "2021-07-24\000",)
STORED AS KUDU
TBLPROPERTIES ('kudu.master_addresses'='10.168.1.12:7051');
这是使用impala创建的kudu表,impala + Kudu,对内存的消耗比较大(我是直接装的CDH),如果条件不允许,建议直接写到hive。
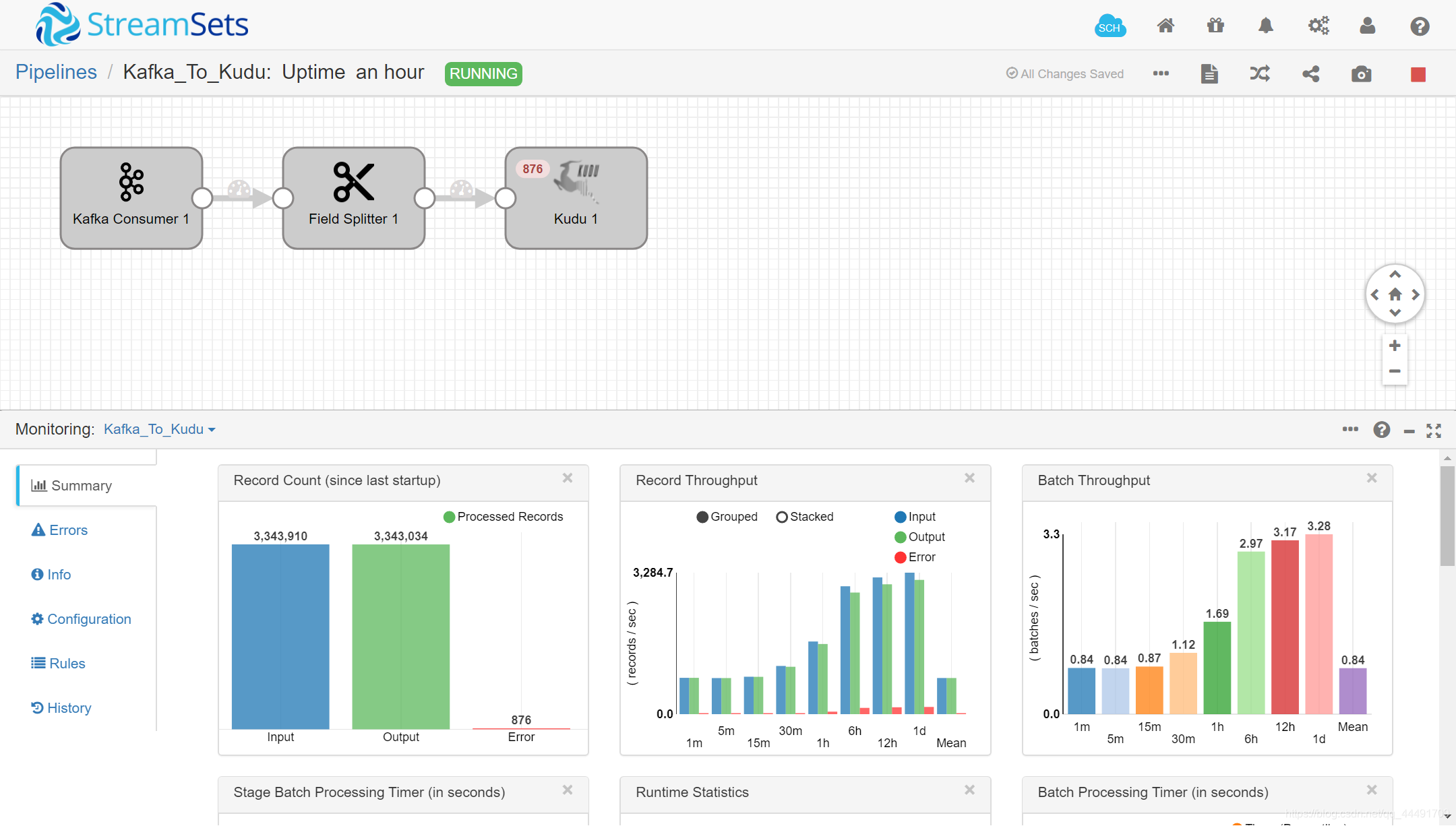
输出源配置:

运行效果(有报错是因为刚才IDEA运行了一下,发送消息到UDP,然后布置在服务器的程序解析发到kafka…又被SDC解析写入kudu,但是kudu里面的id已经存在,所以报错…):

4. 自动创建分区
ranger分区只到24号,超过24号就无法插入数据了,可以新建一个脚本,定时执行。
脚本:每天新建3天后的分区
#!bin/bash
add=$(date -d +3day "+%Y-%m-%d")
nohup impala-shell -q "alter table default.kafka_to_kudu add range partition '${add}' <= VALUES < '${add}\000'" >> /dev/null &
定时任务:每天执行一遍
0 1 * * * sh /root/kudutool/kuduParitition.sh &
五、Spark Streaming解析Kafka写入Kudu
这一块是比较核心的内容,主要流程是新建StreamingContext,然后接收Kafka,将接收的数据转为DF,再使用原生的API保存。
package com.example.dao
import java.lang
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.types.StructField
import org.apache.spark.sql.types.DataTypes
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Kafka_To_Kudu {
Logger.getLogger("org").setLevel(Level.WARN)
def getSparkSess(): StreamingContext = {
val ssc = new StreamingContext(new SparkConf().setMaster("local[*]").setAppName("Kafka_To_Kudu")
// 不加这个set,会报错:对象不可序列化
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
, Seconds(1))
// checkpoint
ssc.checkpoint("hdfs://10.168.1.xx/data/spark/checkpoint/kafka-to-kudu")
// return
ssc
}
def getKafkaConf(): Map[String, Object] = {
val kafkaConfig = Map[String, Object](
"bootstrap.servers" -> "10.168.1.13:9092"
, "key.deserializer" -> classOf[StringDeserializer] // 指定序列化的方式
, "value.deserializer" -> classOf[StringDeserializer] // 指定反序列化方式
, "group.id" -> "group01"
// 指定消费位置
, "auto.offset.reset" -> "latest"
// 提交方式 true :自动提交
, "enable.auto.commit" -> (true: lang.Boolean)
)
kafkaConfig
}
def main(args: Array[String]): Unit = {
val topic = Array("demoTopic")
val ssc = getSparkSess()
// 配置消费
val streams: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topic, getKafkaConf())
)
// insert kudu
// 先转为DF,不然不能保存
streams.foreachRDD { rdd =>
// get ss
val ss = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
// 处理
val value = rdd.map(_.value().split(",")).map(x => // 动态编码
Row(x(2).trim.toInt, x(1), x(0), x(3), x(4).trim.toDouble))
// .toDF("time", "date", "id", "name", "value") // Bean + 反射,略
val schema = StructType(List(
StructField("id", DataTypes.IntegerType, false),
StructField("point_date", DataTypes.StringType, false),
StructField("point_time", DataTypes.StringType, false),
StructField("name", DataTypes.StringType, false),
StructField("value", DataTypes.DoubleType, false)
))
// 绑定
val frame = ss.createDataFrame(value, schema)
// frame.printSchema()
// frame.show()
// 保存
try {
frame.write.options(Map("kudu.master" -> "10.168.1.xx"
, "kudu.table" -> "impala::default.spark_to_kudu"))
.mode("append")
.format("org.apache.kudu.spark.kudu")
.save()
println("保存成功" + frame)
} catch {
case e: Exception => {
try {
ss.stop()
} catch {
case e1: Exception => {
e1.printStackTrace()
}
}
e.printStackTrace()
}
}
}
// start
ssc.start()
ssc.awaitTermination()
}
}
maven:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ScalaSparkStremingConsumerKafka</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.0-cdh6.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.0-cdh6.3.1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17-cloudera1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.example.dao.Kafka_To_Kudu</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
按照上面的kudu建表语句,在kudu里面新建一个spark_to_kudu
这个checkpoint是用来记录Kafka消费的offset,需要新建,并且权限改为777
运行效果:


六、使用StructuredStreaming 处理
这是2021-07-27日新增的。
代码:
package com.example.dao
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SaveMode, SparkSession}
object Kafka_To_Kudu_Structured {
Logger.getLogger("org").setLevel(Level.ERROR)
def getSparkSess(): SparkSession = {
val ss = SparkSession.builder().master("local[*]")
.appName("Kafka_To_Kudu_Structured").getOrCreate()
ss
}
def loadKafkaSession(ss: SparkSession): DataFrame = {
val df = ss.readStream.format("kafka")
.option("kafka.bootstrap.servers", "10.168.1.xx:9092") // boker server
.option("subscribe", "demoTopic") // topic
.option("startingOffsets", "latest") // 从最新的地方开始消费
.load()
df
}
def main(args: Array[String]): Unit = {
val ss = getSparkSess()
val df = loadKafkaSession(ss)
// 隐式转换
import ss.implicits._
// 输出测试
/* df.selectExpr("CAST(value AS STRING)").as[String]
.writeStream.outputMode("append").format("console")
.trigger(Trigger.ProcessingTime(0L))
.option("checkpointLocation","hdfs://10.168.1.12:8020/data/spark_check_point")
.option("truncate",false)
.start()*/
/**
* 处理 + 保存到kudu
* kudu表:structured_to_kudu
* 因为structured不支持kudu,所以先输出到memory,然后再保存到Kudu
* Tips1:如果数据过大,会造成内存溢出
* Tips2:如果对数据没有处理(筛选、聚合),建议直接用SparkStreaming即可
* Tips3:此处采用的是foreachBatch方式,批量保存到kudu...
**/
df.selectExpr("CAST(value AS STRING)").as[String]
.map(line => {
val arr: Array[String] = line.split(",")
// 输出查看
// println(arr(2).toInt, arr(1), arr(0), arr(3), arr(4).toDouble)
(arr(2).toInt, arr(1), arr(0), arr(3), arr(4).toDouble)
}).toDF("id", "point_date", "point_time", "name", "value")
.writeStream.outputMode("append").foreachBatch((df, batchId) => { // 当前分区id, 当前批次id
if (df.count() != 0) {
df.cache() // 加载到内存,速度更快
df.write.mode(SaveMode.Append).format("org.apache.kudu.spark.kudu")
//设置master(ip地址)
.option("kudu.master", "10.168.1.xx")
//设置kudu表名
.option("kudu.table", "impala::default.structured_to_kudu")
//保存
.save()
println("保存成功!" + df)
}
})
.trigger(Trigger.ProcessingTime(0L))
.start()
// run
ss.streams.awaitAnyTermination()
}
}
maven:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ScalaSparkStremingConsumerKafka</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.0-cdh6.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.0-cdh6.3.1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17-cloudera1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.example.dao.Kafka_To_Kudu</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
在最后…我准备打包到服务器运行…但是一直报错:


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)