Redis主从模式以及数据同步原理:全量数据同步、增量数据同步
Redis主从模式以及数据同步原理:全量数据同步、增量数据同步一、主从复制二、数据同步1、全量数据同步2、增量数据同步3、服务器 RUN ID4、复制偏移量 offset5、环形缓冲区三、何时使用全量还是增量数据同步Redis有三种集群模式,分别是:主从模式、哨兵模式、Cluster模式主从模式是三种模式中最简单的,在主从复制中分为主数据库(master)和从数据库(slave),若master出
Redis主从模式以及数据同步原理:全量数据同步、增量数据同步
Redis有三种集群模式,分别是:主从模式、哨兵模式、Cluster模式
主从模式是三种模式中最简单的,在主从复制中分为主数据库(master)和从数据库(slave),若master出现宕机,需要手动配置slave转为master。
后来为了高可用提出来哨兵模式,可以选择出slave转为master,提升可用性,但不能动态扩充。
后来又有了cluster集群模式。
本文介绍主从模式,以及如何数据同步
一、主从复制
命令:redis-server --replicaof 127.0.0.1 7001
执行该命令后,当前服务器得redis-server就会成为127.0.0.1 7001的从数据库了,使用从数据库可以使得数据更加安全。从数据库具有只读属性,不能写。
主数据库要给从数据库同步数据才能使用,下面将介绍同步数据的方式
二、数据同步
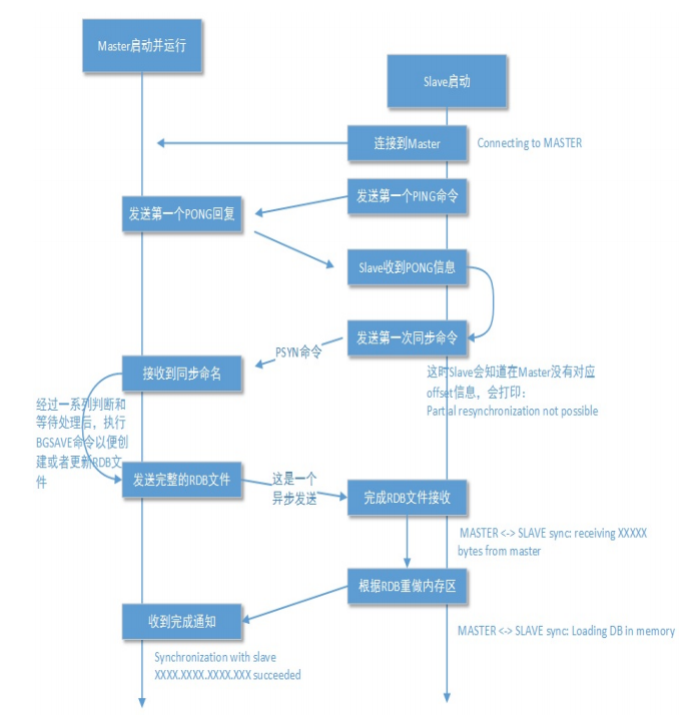
1、全量数据同步
- 从数据库连接到主数据库
- 从数据库发送ping命令,主数据库回复pong命令
发送ping主要是为了(相当于tcp的 keepalive 心跳包)检测主数据库是否有响应 - 从数据库发送一个同步命令,主数据库进行异步发送数据
无论主数据采用aof还是rdb的持久化方式,在主从复制的时候都以rdb的数据格式进行复制 - 从数据库根据rdb调整内存后,发送给主数据库完成同步命令
2、增量数据同步
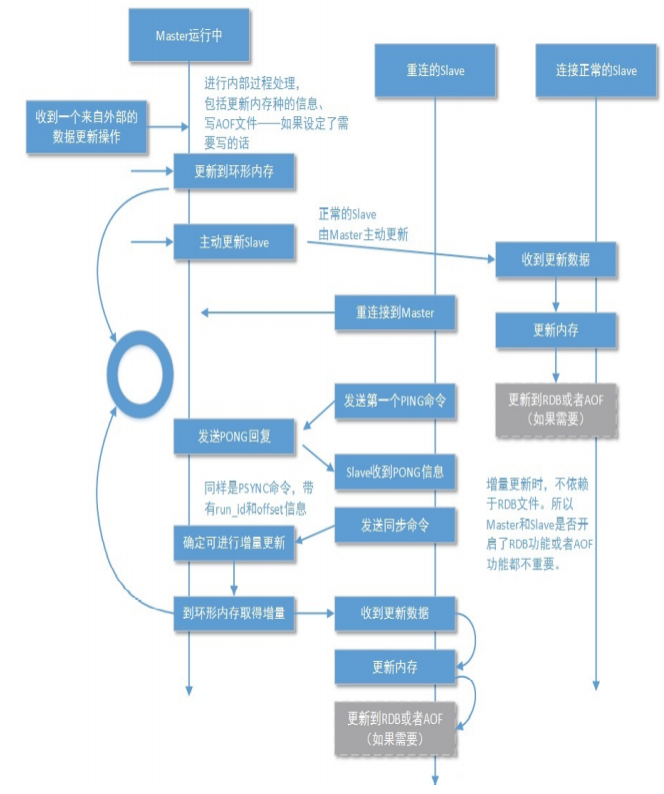
在从数据库连接着主数据库情况下,由于网络原因,某些数据出现主从不一致的情况,这时候可以容忍数据不一致的情况,通过设置环形缓冲区,将网络抖动时候的数据先写入环形缓冲区,从数据库会记录一个偏移值,在主数据库发送数据前,从数据库先把偏移值发送给主数据库,看偏移值是否在环形缓冲区中,然后再将环形缓冲区中偏移值到起始地址的数据发送到从数据库中
3、服务器 RUN ID
无论主库还是从库都有自己的 RUN ID,RUN ID 启动时自动产生,RUN ID 由40个随机的十六进
制字符组成;
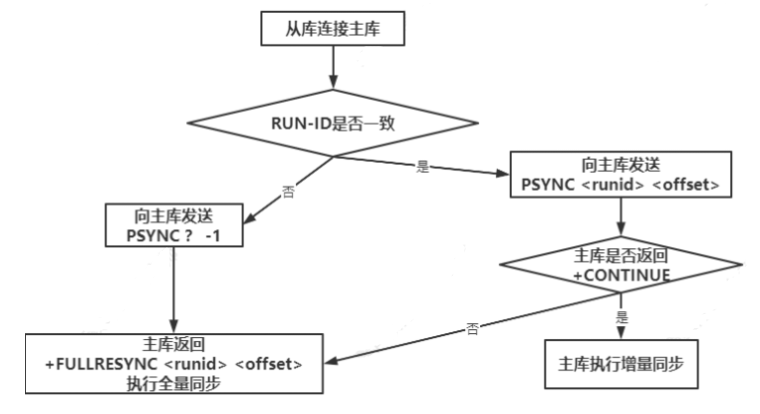
当从库对主库初次复制时,主库将自身的 RUN ID 传送给从库,从库会将 RUN ID 保存;
当从库断线重连主库时,从库将向主库发送之前保存的 RUN ID;
- 从库 RUN ID 和主库 RUN ID 一致,说明从库断线前复制的就是当前的主库;主库尝试执行 增量同步操作;
- 若不一致,说明从库断线前复制的主库并不时当前的主库,则主库将对从库执行全量同步操作;
相比全量数据同步,增量数据同步还多了数据检查。从数据库连接主数据库,使用了runid,而不仅仅是ip、port,因为如果从数据库所在服务器宕机了,换了另一台,使用ip、port,那又怎么知道该增量多少呢,复制到哪个阶段,而使用runid可以唯一标识从数据库。
4、复制偏移量 offset
主从都会维护一个复制偏移量;
- 主库向从库发送N个字节的数据时,将自己的复制偏移量上加N;
- 从库接收到主库发送的N个字节数据时,将自己的复制偏移量加上N;
通过比较主从偏移量得知主从之间数据是否一致;偏移量相同则数据一致;偏移量不同则数据不一
致;
5、环形缓冲区
本质:固定长度先进先出队列;
存储内容:如下图;
当因某些原因(网络抖动或从库宕机)从库与主库断开连接,避免重新连接后开始全量同步,在主
库设置了一个环形缓冲区;该缓冲区会在从库失联期间累计主库的写操作;当从库重连,会发送自
身的复制偏移量到主库,主库会比较主从的复制偏移量:
- 若从库offset还在复制积压缓冲区中,则进行增量同步;
- 否则,主库将对从库执行全量同步;
# redis.conf
# 环形缓冲区的大小 为1mb
repl-backlog-size 1mb
# 如果所有从库断开连接 3600 秒后没有从库连接,则释放环形缓冲区
repl-backlog-ttl 3600
大小确定: disconnect_time * write_size_per_seconddisconnect_time :从库断线后重连主库所需的平均时间(以秒为单位);write_size_per_second :主库平均每秒产生的写命令数据量;
偏移量会出现环绕回去,变成0的情况吗?偏移量最大为 2 64 2^{64} 264,就算一天增加1个亿,也要好几千年,不会存在这种问题。
三、何时使用全量还是增量数据同步

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)