HBase 基础知识
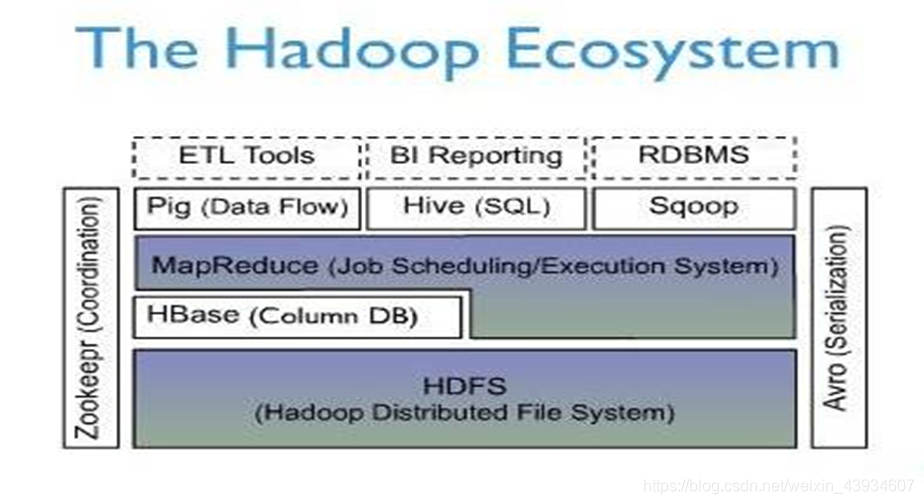
HBase基础知识一、HBase简介HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协调工具。二、HBase三要素1、主键
HBase基础知识
一、HBase简介
- HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
- HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协调工具。
二、HBase三要素
-
1、主键:Row Key (主键是用来检索记录的主键,访问hbase table中的行,只有三种方式:)
-
通过单个row key访问
-
通过row key的range
-
全表扫描(scan)
-
-
2、列族:Column Family
- 列族在创建表的时候声明,一个列族可以包含多个列,列中的数据都是以二进制形式存在,没有数据类型。
-
3、时间戳:timestamp
- HBase中通过Row和Column Family确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引
三、HBASE基础知识
1、物理存储
-
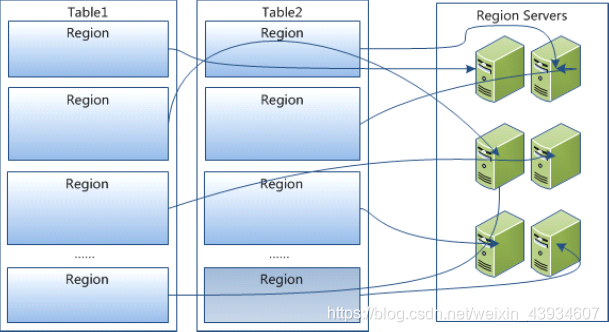
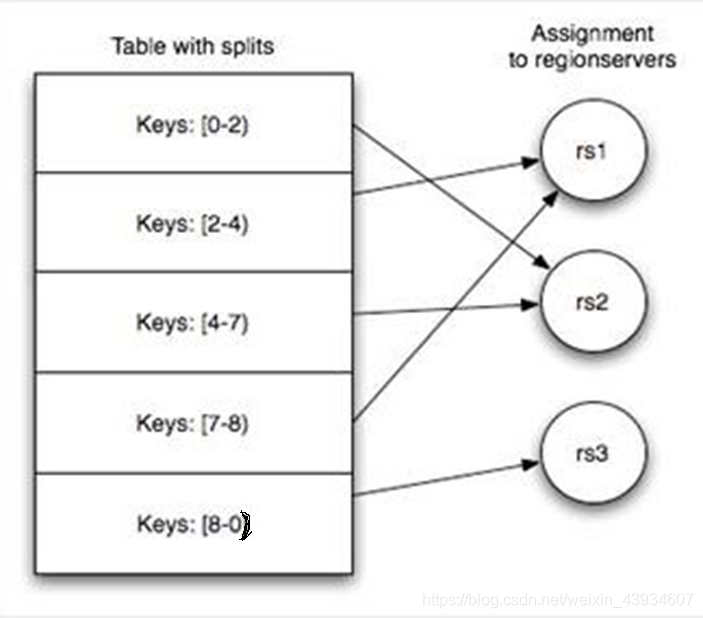
table 在行的方向上分割为多个HRegion,一个region由[startkey,endkey)表示,每个HRegion分散在不同的RegionServer中
2、架构体系
-
Client 包含访问hbase 的接口,client 维护着一些cache 来加快对hbase 的访问,比如regione 的位置信息
-
Zookeeper
-
保证任何时候,集群中只有一个running master
-
存贮所有Region 的寻址入口
-
实时监控Region Server 的状态,将Region server 的上线和下线信息,实时通知给Master
-
存储Hbase 的schema,包括有哪些table,每个table 有哪些column family
-
-
Master 可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行
-
为Region server 分配region
-
负责region server 的负载均衡
-
发现失效的region server 并重新分配其上的region
-
3、HBase的逻辑梳理
-
HBase中有两张特殊的Table,-ROOT-(hbase:namespace)和.META.(hbase:meta)
-
(0.98 版本后弃用)-ROOT-(hbase:namespace) :记录了.META.(hbase:meta)表的Region信息,-ROOT-(hbase:namespace)只有一个region
-
.META.(hbase:meta) :记录了用户创建的表的Region信息,.META.(hbase:meta)可以有多个regoin
-
-
Zookeeper中记录了META 表的location

- Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-(hbase:namespace)表,接着访问.META.(hbase:meta)表,最后才能找到用户数据的位置去访问(0.98 版本后没有 -ROOT- 这步)
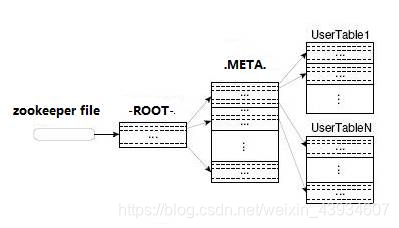
- Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-(hbase:namespace)表,接着访问.META.(hbase:meta)表,最后才能找到用户数据的位置去访问(0.98 版本后没有 -ROOT- 这步)
4、HBase读数据流程
-
HBase读数据流程
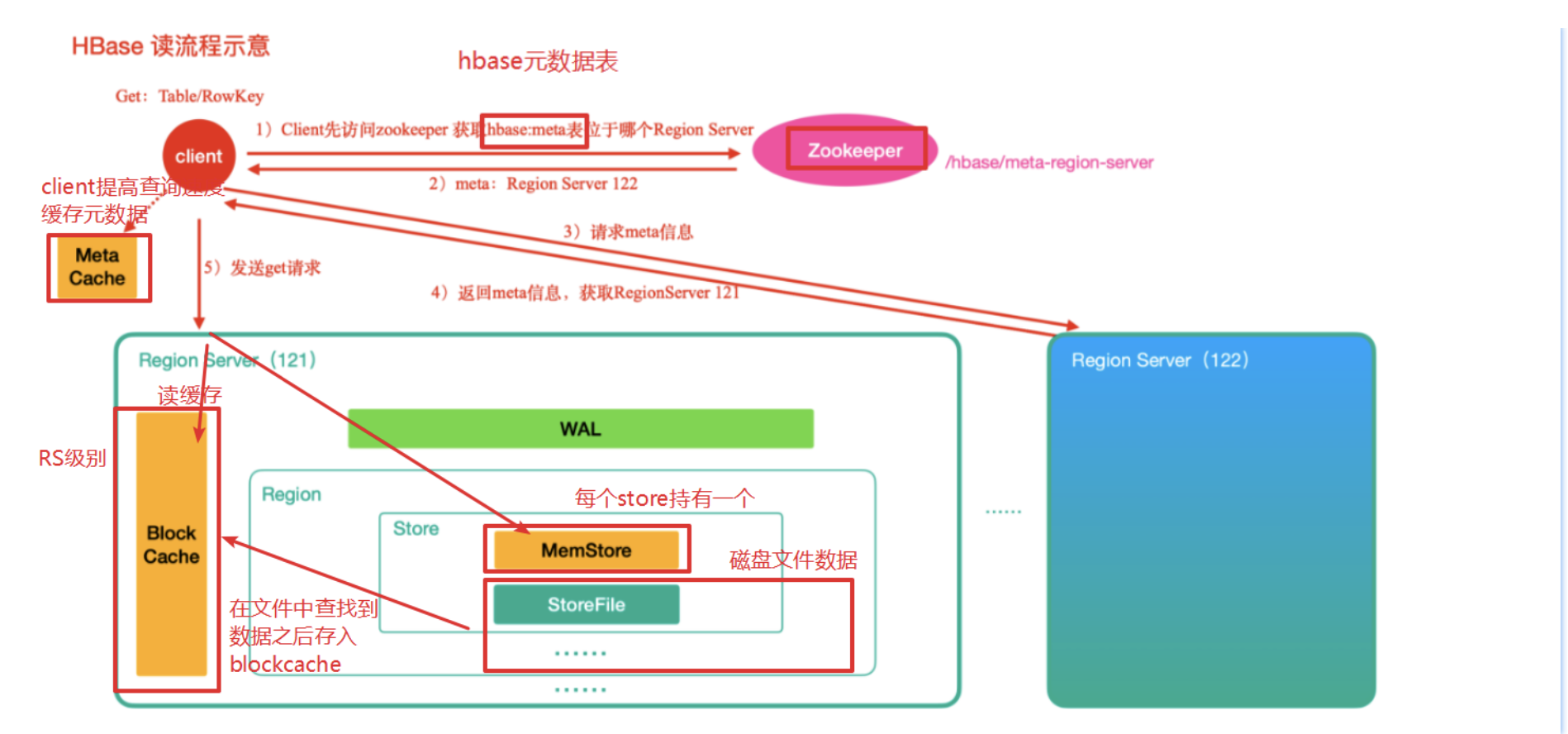
-
HBase元数据信息
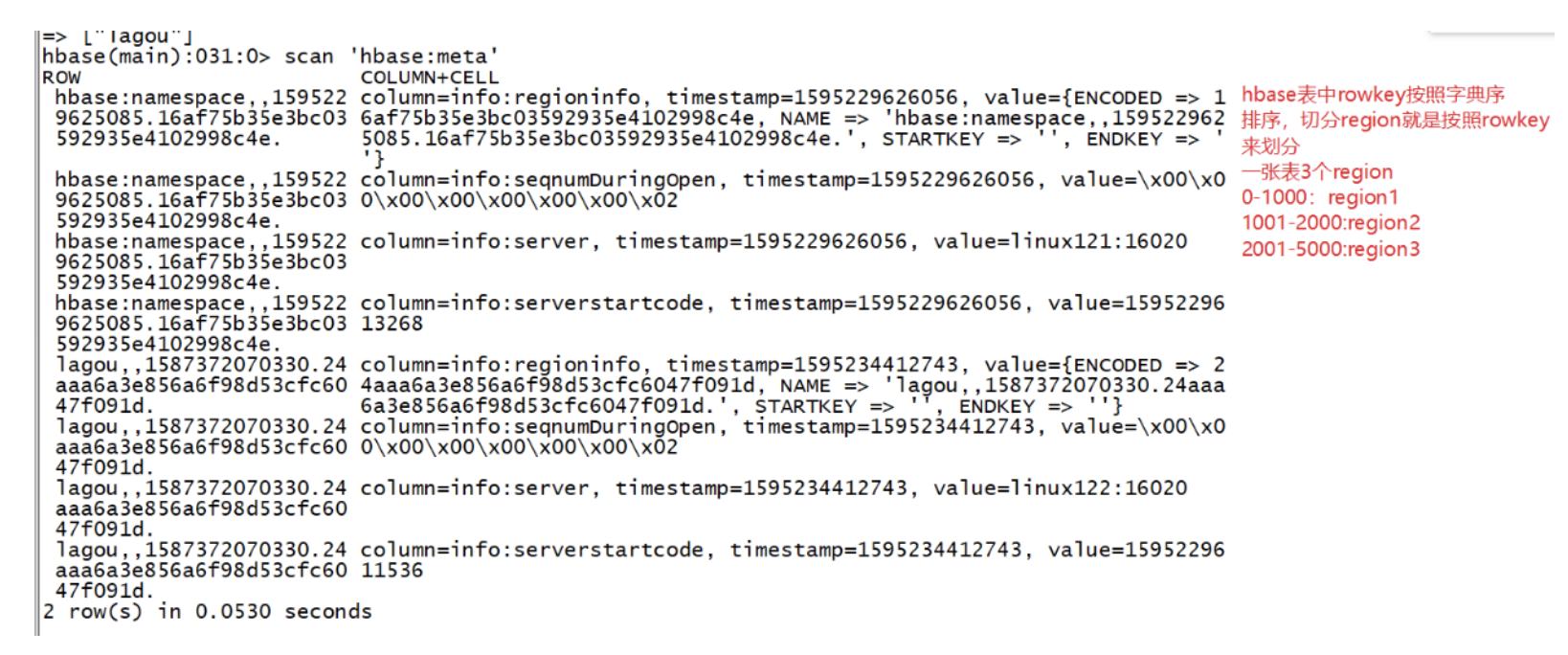
-
HBase读操作
-
首先从zk中找到meta表的region信息,然后meta表中的数据,meta表中存储了用户的region信息
-
根据要查询的namespace、表名和rowkey信息,找到对应的真正存储要查询的数据的region信息
-
找到这个region对应的regionServer,然后发送请求
-
查找对应的region
-
先从metastore查找数据,如果没有,再从BlockCache读取。
- HBase上的RegionServer的内存分为两个部分
- 一部分作为Memstore,主要用来写
- 另一部分作为BlockCache,主要用来读数据
- HBase上的RegionServer的内存分为两个部分
-
如果BlockCache中也没有找到,再到StoreFile上进行读取
- 从storeFile中读取到数据之后,不是直接把结果数据返回给客户端, 而是把数据先写⼊入到BlockCache中,目的是为了加快后续的查询;然后在返回结果给客户端。
5、HBase写数据流程
-
HBase写数据流程
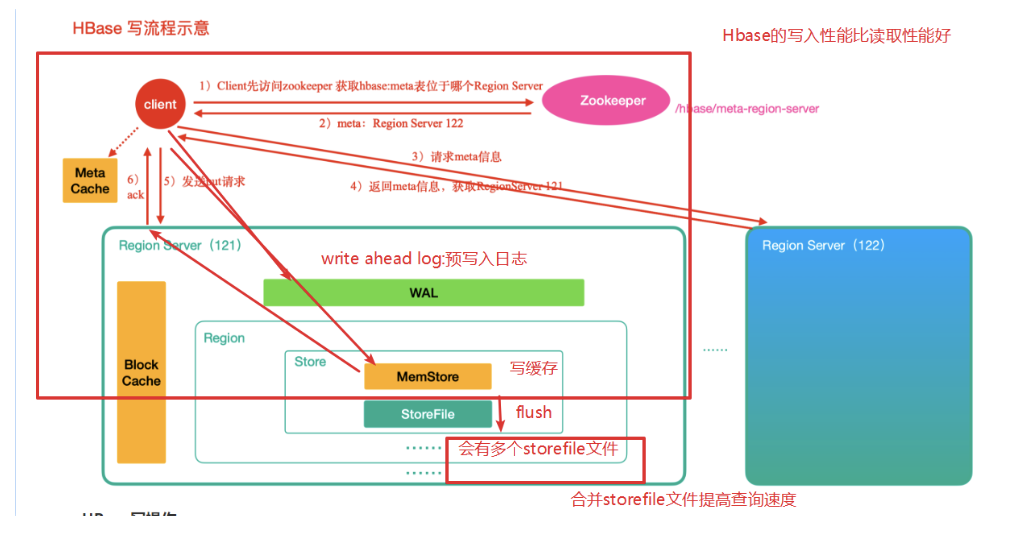
-
HBase写操作
- 首先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了用户表的region信息
- 根据要查询的namespace、表名和rowkey信息,找到对应的真正存储要查询的数据的region信息
- 找到这个region对应的regionServer,然后发送请求
- 把数据写到HLog(write ahead log。WAL:预写入日志)和memstore各一份(写到Region里列族对应的Store的内存)
- Memstore 达到阈值后把数据刷到磁盘,生产storeFile
- 删除HLog中的历史数据
四、系统架构
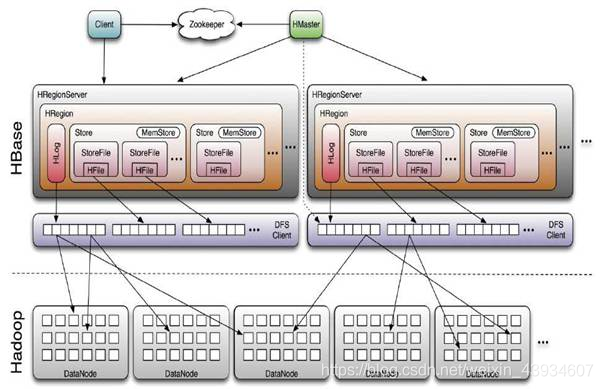
- Zookeeper:在Hbase中,选举集群主节点Master,以便跟踪可用的在线服务器,同时维护集群的元数据。一般安装多个,用于提供Master的高可用性。
- 1)Master高可用,协助选举Master
- 2)监听RegionServer状态(心跳),向Master汇报RegionServer上下线信息
- 3)存放与维护集群配置信息,如hbase:meta表的地址。
- Master:Hbase的主节点(集群中的某一台服务器),协调客户端应用程序与RegionServer的关系,监控和记录元数据的变化和管理。
- 1)负责管理元数据,如执行DDL操作、定期更新hbase:meta表
- 2)分配与移动region以保证集群的负载均衡
- 3)管理RegionServer,出现问题时进行故障转移 在分布式集群中,Master通常运行在NameNode上。
- RegionServer:是Hbase的从节点,用region形式处理实际的表。Region是Hbase表的基础单元组件,存储了分布式表。Hbase集群利用Master和RegionServer来协同工作。
- 1)负责数据的增删改查,即DML操作
- 2)负责region的拆分与合并
- 3)将MemStore中数据刷写到StoreFiles
- 4)检查RegionServer的HLog文件 在分布式集群中,RegionServer都运行在DataNode上。
- Clinet:使用HBase RPC机制与Master和RegionServer通信。对于管理类操作(DDL操作)与Master通信,对于数据读写类操作与RegionServer通信。
五、HBase数据模型:
HBase不以关系设计为中心,可以根据需求随意增加字段。每行数据提供row_key做快速索引。
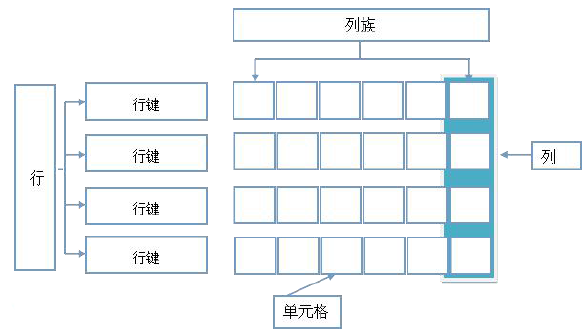
- 行键:是每个记录的唯一键,它在内存或磁盘中是以字节数组保存的,没有数据类型的概念。
- 列族:将相同功能或类型的列集合在一起成为列族。
除了上边几个概念外,还包括以下一些:
- (1)版本:Hbase中没有Insert和Update,只有put。每put一次,就会产生一个版本,默认显示你最后一次put的内容(最新的版本),并且保留3个版本的记录。
- (2)时间戳:表示数据插入到表中的时间。
- (3)单元格(Cell):最基本的存储单元,在内部就是一个实际存储的值。插入单元格数据时,必须包括:table(namespace:tablename) + rowkey + column family + column + timestamp : value。
HBase的Schema由表名和列族两项组成。另外,值结合版本信息转为字节数组存储在列中。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)