hbase的RIT异常处理
hbase的RIT异常处理
文章目录
- RIT的理解
- Region-In-Trasition机制
- 案例分析
- 1.Compaction永久阻塞
- 现象:线上一个集群因为未知原因忽然就卡住了,读写完全进不来了;另外还有很多处于PENDING_CLOSE状态的Region。
- 分析:集群卡住常见原因无非两个,一是Memstore总消耗内存大小超过了上限进而触发RegionServer级别flush,此时系统会阻塞集群执行长时间flush操作;二是storefile数量过多超过设定的上限阈值(参见:hbase.hstore.blockingStoreFiles),此时系统会阻塞所有flush请求而执行compaction。可以在CDH 上进行Hbase的页面查看各个region的大小以及数据的分布均衡
- 排查思路:
- 解决方案:
- 操作指令:
- 注意点:如果Hbases版本的2.x的需要进行: Hbase 2.0以后, 不在提供默认的hbck工具类,需要使用hbck2,进行使用下载
- 其他命令参考
- 当HDFS文件异常时,导致Region处于FAILED_OPEN状态
RIT的理解
相信长时间运维HBase集群的童鞋肯定都会对RIT(Region-In-Transition,很多参考资料误解为Region-In-Transaction,需要注意)有一种咬牙切齿的痛恨感,一旦Region处于长时间的RIT就会有些不知所措,至少以前的我就是这样过来的。正所谓“恐惧来源于未知”,不知所措意味着我们对RIT知之甚少,然而“凡事都有因果,万事皆有源头”,处于RIT状态的Region只是肉眼看到的一个结果,为什么会处于RIT状态才是问题探索的根本,也是解决问题的关键。本文就基于hbase 1.2.0版本对RIT的工作机制以及实现原理进行普及性的介绍,同时在此基础上通过真实案例讲解如何正确合理地处理处于RIT状态的Region。一方面希望大家能够更好的了解RIT机制,另一方面希望通过本文的学习之后可以不再’惧怕’RIT,正确认识处于RIT状态的Region。
Region-In-Trasition机制
从字面意思来看,Region-In-Transition说的是Region变迁机制,实际上是指在一次特定操作行为中Region状态的变迁,那这里就涉及这么几个问题:
Region存在多少种状态?
HBase有哪些操作会触发Region状态变迁?
一次正常操作过程中Region状态变迁的完整流程是怎么样的?
如果Region状态在变迁的过程中出现异常又会怎么样?
Region存在多少种状态?
有哪些操作会触发状态变迁?
HBase在RegionState类中定义了Region的主要状态,主要有如下:
1.详细图解
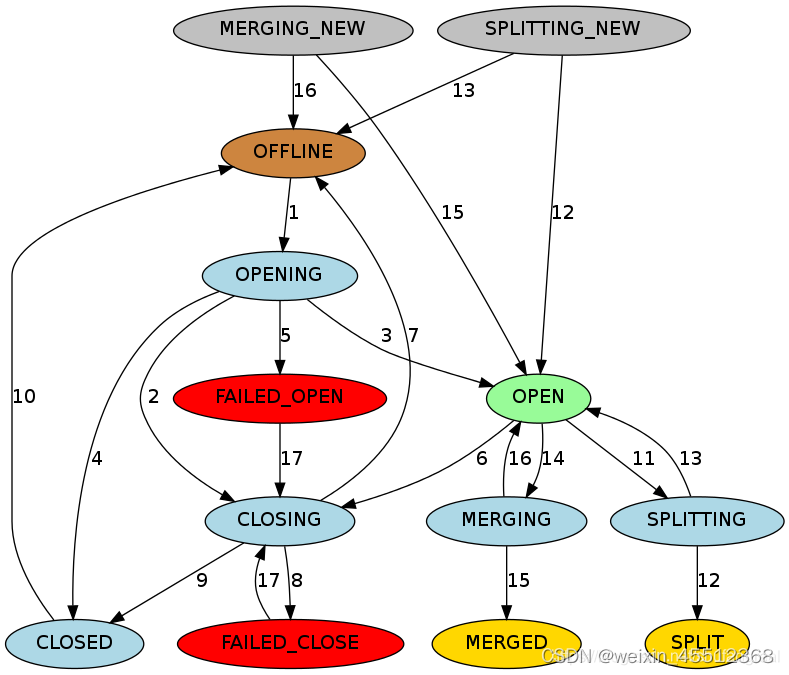
1.1 Region是Hbase中数据管理单元,Region可以有以下多种状态。
OFFLINE:代表Region是下线状态,而且未开放
OPENING:代表Region正处于被打开的执行状态,但是还未被开放
OPEN:代表Region此时已经开放,而且RegionServer此时已经通知Master,此时该Region是可以投入使用的
FAILED_OPEN:RegionServer打开Region失败
CLOSING:Region正在被RegionServer关闭
FAILED_CLOSED:RegionServer关闭Region失败
SPLITTING:Region正在被分裂
SPLIT:Region完成分裂
SPLITTING_NEW:Region正在被创建,创建方式是通过父Region的SPLTTING操作
MERGED:RegionServer已经通知了Master,该Region已经被合并
MERGING_NEW:这个Region正在通过Merging被创建
只有OPEN状态才能给外部处理服务请求
1.2 其中图片的颜色
棕色:代表OFFLINE状态,这是一个特殊的状态,这个状态是一个暂时的状态,在CLOSED状态之后,在OPENING状态之前
CLOSED => OFFLINE => OPENGING => OPEN
绿色:代表在线状态,此时可以处理服务请求
亮蓝色:代表进行中的暂时状态
红色:故障状态,需要OPS注意
金色:最终状态,已拆分/已合并
灰色:代表拆分/合并过程中的初始状态
2.简单示意图

2.1上图中实际上定义了四种会触发Region状态变迁的操作以及操作对应的Region状态。
其中特定操作行为通常包括assign、unassign、split以及merge等,而很多其他操作都可以拆成unassign和assign,比如move操作实际上是先unassign再assign;
2.2 Region状态迁移是如何发生的?
这个过程有点类似于状态机,也是通过事件驱动的。和Region状态一样,HBase还定义了很多事件(具体见EventType类)。此处以unassign过程为例说明事件是如何驱动状态变迁的,见下图:
2.2.1 迁移示意图

2.2.2 上图所示是Region在close时的状态变迁图,
其中红字部分就是发生的各种事件。可见,如果发生M_ZK_REGION_CLOSING事件,Region就会从OPEN状态迁移到PENDING_CLOSE状态,而发生RS_ZK_REGION_CLOSING事件,Region会从PENDING_CLOSE状态迁移到CLOSING状态,以此类推,发生RS_ZK_REGION_CLOSED事件,Region就会从CLOSING状态迁移到CLOSED状态。当然,除了这些事件之外,HBase还定义了很多其他事件,在此就不一一列举。截至到此,我们知道Region是一个有限状态机,那这个状态机是如何正常工作的,HMaster、RegionServer、Zookeeper又在状态机工作过程中扮演了什么角色,
3.一次正常操作过程中Region状态变迁的完整流程

3.1 过程讲解图
- HMaster先执行事件M_ZK_REGION_CLOSING并更新RegionStates。
- 将该Region的状态改为PENDING_CLOSE,并在regionsInTransition中插入一条记录;
- 发送一条RPC命令给拥有该Region的RegionServer,责令其关闭该Region;
- RegionServer接收到HMaster发送过来的命令之后,首先生成一个RS_ZK_REGION_CLOSING事件,更新到Zookeeper。
- Master监听到ZK节点变动之后更新regionStates,将该Region的状态改为CLOSING;
RegionServer执行真正的Region关闭操作:如果该Region正在执行flush或者compaction,等待操作完成;否则将该Region下的所有Memstore强制flush; - 完成之后生成事件RS_ZK_REGION_CLOSED,更新到Zookeeper。
- Master监听到ZK节点变动之后更新regionStates,将该Region的状态改为CLOSED;
到这里,基本上将unssign操作过程中涉及到的Region状态变迁解释清楚了,当然,其他诸如assign操作基本类似,在此不再赘述。这里其实还有一个问题,即关于HMaster上所有Region状态是否需要持久化的问题,刚开始接触这个问题的时候想想并不需要,这些处于RIT的状态信息完全可以通过Zookeeper上/region-in-transition的子节点信息构建出来。然而,在阅读HBase Book的相关章节时,看到如下信息:一方面Master更新hbase:meta是一个远程操作,代价相对很大;另一方面Region状态内存更新和远程更新保证一致性比较困难;再者,Zookeeper上已经有相应RIT信息,再持久化一份并没有太大意义。为了对其进行确认,就查阅跟踪了一下源码,发现是否持久化取决于一个参数: hbase.assignment.usezk ,默认情况下该参数为true,表示使用zk情况下并不会对Region状态进行持久化(详见RegionStateStore类),可见HBase Book的那段说明存在问题,
3.2 如果Region状态在变迁的过程中出现异常会怎么样?
- Master宕机重启:Master在宕机之后会丢失所有内存中的信息,也包括RIT信息以及Region状态信息,因此在重启之后会第一时间重建这些信息。重启之后会遍历Zookeeper上/hbase/regions-in-transition节点下的所有子节点,解析所有子节点对应的最后一个‘事件’,解析完成之后一方面借此重建全局的Region状态,另一方面根据状态机转移图对处于RIT状态的Region进行处理。比如如果发现当前Region的状态是PENDING_CLOSE,Master就会再次据此向RegionServer发送’关闭Region’的RPC命令。
- 其他异常宕机:HBase会在后台开启一个线程定期检查内存中处于RIT中的Region,一旦这些Region处于RIT状态的时长超过一定的阈值(由参数hbase.master.assignment.timeoutmonitor.timeout定义,默认600000ms)就会重新执行unassign或者assign操作。比如如果当前Region的状态是PENDING_CLOSE,而且处于该状态的时间超过了600000ms,Master就会重新执行unassign操作,向RegionServer再次发送’关闭Region’的RPC命令。
可见,HBase提供了基本的重试机制,保证在一些短暂异常的情况下能够通过不断重试拉起那些处于RIT状态的Region,进而保证操作的完整性和状态的一致性。然而不幸的是,因为各种各样的原因,很多Region还是会掉入长时间的RIT状态,甚至是永久的RIT状态,必须人为干预才能解决。 - RIT的整体机制我们明白了。回到我们出现的问题,我们所有的数据都是处于在OPENING状态,表示服务开始分配但是未分配完成,很有可能是在分配过程中直接宕机,导致这些Region一直处于Region状态。
案例分析
在一些特别极端的场景下还是会发生一些异常导致部分Region掉入永久的RIT状态,进而会引起表读写阻塞甚至整个集群的读写阻塞
1.Compaction永久阻塞
现象:线上一个集群因为未知原因忽然就卡住了,读写完全进不来了;另外还有很多处于PENDING_CLOSE状态的Region。
分析:集群卡住常见原因无非两个,一是Memstore总消耗内存大小超过了上限进而触发RegionServer级别flush,此时系统会阻塞集群执行长时间flush操作;二是storefile数量过多超过设定的上限阈值(参见:hbase.hstore.blockingStoreFiles),此时系统会阻塞所有flush请求而执行compaction。可以在CDH 上进行Hbase的页面查看各个region的大小以及数据的分布均衡
排查思路:
1)首先查看了各个RegionServer上的Memstore使用大小,并没有达到设定的upperLimit。
2)再查看了一下所有RegionServer的storefile数量,瞬间石化了,store数为250的RegionServer上storefile数量竟然达到了1.5w+,很多单个store的storefile都超过了设定阈值100
3)初步怀疑是因为storefile数量过多引起的,看到这么多storefile的第一反应是手动执行major_compaction,然而所有的compact命令好像都没有起任何作用
4)无意中发现所有RegionServer的Compaction任务都是同一张表music_actions的,而且Compaction时间都基本持续了一两天。到此基本可以确认是因为表music_actions的Compaction任务长时间阻塞,占用了所有的Compaction线程资源,导致集群中所有其他表都无法执行Compaction任务,最后导致StoreFile大量堆积
5)那为什么会存在PENDING_CLOSE状态的Region呢?经查看,这些处于PENDING_CLOSE状态的Region全部来自于表music_actions,进一步诊断确认是由于在执行graceful_stop过程中unassign时遇到Compaction长时间阻塞导致RegionServer无法执行Region关闭(参考上文unassign过程),因而掉入了永久RIT
解决方案:
1)这个问题中RIT和集群卡住原因都在于music_actions这张表的Compaction阻塞,因此需要定位Compaction阻塞的具体原因。经过一段时间的定位初步怀疑是因为这张表的编码导致,anyway,具体原因不重要,因为一旦Compaction阻塞,好像是没办法通过正常命令解除这种阻塞的。临时有用的办法是增大集群的Compaction线程,以期望有更多空闲线程可以处理集群中其他Compaction任务,消化大量堆积的StoreFiles
2)而永久性消灭这种Compaction阻塞只能先将这张表数据迁移出来,然后将这张表暴力删除。暴力删除就是先将HDFS对应文件删除,再将hbase:meta中该表对应的相关数据清除,最后重启整个集群即可。这张表删除之后使用hbck检查一致性之后,集群Compaction阻塞现象就消失了,集群就完全恢复正常。
操作指令:
- 重新assign Region,对每个异常的region进行数据处理
[rootroot@k8s-master ]# hbase shell
[rootroot@k8s-master ]# assign 'region名称’
对页面的红色引用文件进行批处理

let tds = $(".tab-pane tr[role=alert] > td:nth-child(2)");
let tdArrays = [];
for (let i = 0; i< tds.length; i++) {
if (tds[i] != null) {
let html = tds[i].innerHTML;
if (html != null && html.indexOf('KYLIN_') > 0) {
tdArrays.push(html.trim().split(' state=OPENING')[0]);
}
}
}
tdArrays.join("";\nassign "")
注意点:如果Hbases版本的2.x的需要进行: Hbase 2.0以后, 不在提供默认的hbck工具类,需要使用hbck2,进行使用下载
git clone https://github.com/apache/hbase-operator-tools.git
mvn clean package
HBCK2 来进行处理,那么最好是可以复制粘贴需要处理的 region 或者 procedure
[rootroot@k8s-master ]# assigns 'region名称’
[rootroot@k8s-master ]# sudo -u hbase hbase hbck -j /data/hbase-hbck2-1.1.0-SNAPSHOT.jar assigns 'region名称’
其他命令参考
HBase的 Regions in Transition 问题
# 查看hbase中损坏的block
hbase hbck
# 修复hbase
hbase hbck -repair
The Load Balancer is not enabled which will eventually cause performance degradation in HBase as Regions will not be distributed across all RegionServers. The balancer is only expected to be disabled during rolling upgrade scenarios.
关闭balance,防止在停掉服务后,原先节点上的分片会迁移到其他节点上,到时候在移回来,浪费时间。
hbase(main):001:0> balance_switch true
2018-02-27 21:14:54,236 INFO [hbasefsck-pool1-t38] util.HBaseFsckRepair: Region still in transition, waiting for it to become assigned: {ENCODED => e540df791e7fcdc93c118b8055d1c74f, NAME => 'pos_flow_summary_20170713,,1503656523513.e540df791e7fcdc93c118b8055d1c74f.', STARTKEY => '', ENDKEY => ''}
2018-02-27 21:14:54,236 INFO [hbasefsck-pool1-t47] util.HBaseFsckRepair: Region still in transition, waiting for it to become assigned: {ENCODED => e59b1015c6fed189cdb9ba8493024563, NAME => 'pos_flow_summary_20180111,,1515768771542.e59b1015c6fed189cdb9ba8493024563.', STARTKEY => '', ENDKEY => ''}
2018-02-27 21:14:54,241 INFO [hbasefsck-pool1-t44] util.HBaseFsckRepair: Region still in transition, waiting for it to become assigned: {ENCODED => d22e214e72ff89e87b4df3eebd9603f9, NAME => 'pos_flow_summary_20180112,,1515855181051.d22e214e72ff89e87b4df3eebd9603f9.', STARTKEY => '', ENDKEY => ''}
2018-02-27 21:14:54,244 INFO [hbasefsck-pool1-t23] util.HBaseFsckRepair: Region still in transition, waiting for it to become assigned: {ENCODED => e8667191e988db9d65b52cfdb5e83a4d, NAME => 'pos_flow_summary_20170310,,1504229353726.e8667191e988db9d65b52cfdb5e83a4d.', STARTKEY => '', ENDKEY => ''}
2018-02-27 21:14:54,245 INFO [hbasefsck-pool1-t45] util.HBaseFsckRepair: Region still in transition, waiting for it to become assigned: {ENCODED => d05b759994d757b8fc857993e3351648, NAME => 'app_point,5000,1510910952310.d05b759994d757b8fc857993e3351648.', STARTKEY => '5000', ENDKEY => '5505|1dcfb8c9a44c4147acc823c2e463d536'}
# 修复 .META表
hbase hbck -fixMeta
ERROR: Region { meta => pos_flow,2012|dd12dceee69c56f6776154d02e49f840,1518061965154.71eb7d463708010bc2a3f1e96deca135., hdfs => hdfs://namenode01:9000/hbase/data/default/pos_flow/71eb7d463708010bc2a3f1e96deca135, deployed => , replicaId => 0 } not deployed on any region server.
ERROR: Region { meta => pos_flow_summary_20180115,,1516115199923.70df944adbd82c1422be8f7ee8c24f3e., hdfs => hdfs://namenode01:9000/hbase/data/default/pos_flow_summary_20180115/70df944adbd82c1422be8f7ee8c24f3e, deployed => , replicaId => 0 } not deployed on any region server.
ERROR: Region { meta => pos_flow,5215|249f79b383f5c144cdd95cd1c29fdec3,1518380260884.67bfa42b4c45ec847c7eb27bbd7d86e5., hdfs => hdfs://namenode01:9000/hbase/data/default/pos_flow/67bfa42b4c45ec847c7eb27bbd7d86e5, deployed => , replicaId => 0 } not deployed on any region server.
ERROR: Region { meta => pos_flow_summary_20170528,,1504142971183.679bcdecd0335c99d847374db34de31d., hdfs => hdfs://namenode01:9000/hbase/data/default/pos_flow_summary_20170528/679bcdecd0335c99d847374db34de31d, deployed => , replicaId => 0 } not deployed on any region server.
ERROR: Region { meta => pos_flow,4744|dcf7bccc75f738986e5db100f1f54473,1518489513549.673e899d577f6111b5699b3374ba6adc., hdfs => hdfs://namenode01:9000/hbase/data/default/pos_flow/673e899d577f6111b5699b3374ba6adc, deployed => , replicaId => 0 } not deployed on any region server.
ERROR: Region { meta => pos_flow,1321|ab83f75ef25bdd0d2ecc363fe1fe0106,1518466350793.66b9622950bba42339f011ac745b080b., hdfs => hdfs://namenode01:9000/hbase/data/default/pos_flow/66b9622950bba42339f011ac745b080b, deployed => , replicaId => 0 } not deployed on any region server.
ERROR: Region { meta => pos_flow,9449|1ed33683e675c3e9ddbecf4d9bd42183,1518041132081.66b11e69bc62f356b3f81f351b8a6c68., hdfs => hdfs://namenode01:9000/hbase/data/default/pos_flow/66b11e69bc62f356b3f81f351b8a6c68, deployed => , replicaId => 0 } not deployed on any region server.
ERROR: Region { meta => access_log,1000,1517363823393.65c41f802af180f41af848f1fed8e725., hdfs => hdfs://namenode01:9000/hbase/data/default/access_log/65c41f802af180f41af848f1fed8e725, deployed => , replicaId => 0 } not deployed on any region server.
Table pos_flow_summary_20180222 is okay.
Number of regions: 0
Deployed on:
Table pos_flow_summary_20180223 is okay.
Number of regions: 0
Deployed on:
Table pos_flow_summary_20180224 is okay.
Number of regions: 1
Deployed on: prd-bldb-hdp-data02,60020,1519734905071
Table pos_flow_summary_20180225 is okay.
Number of regions: 1
Deployed on: prd-bldb-hdp-data02,60020,1519734905071
Table pos_flow_summary_20180226 is okay.
Number of regions: 1
Deployed on: prd-bldb-hdp-data02,60020,1519734905071
Table hbase:namespace is okay.
Number of regions: 1
Deployed on: prd-bldb-hdp-data02,60020,1519734905071
Table gb_app_active is inconsistent.
Number of regions: 7
Deployed on: prd-bldb-hdp-data01,60020,1519734905393 prd-bldb-hdp-data02,60020,1519734905071 prd-bldb-hdp-data03,60020,1519734905043
Table app_point is inconsistent.
Number of regions: 3
Deployed on: prd-bldb-hdp-data01,60020,1519734905393 prd-bldb-hdp-data03,60020,1519734905043
inconsistencies detected.
Status: INCONSISTENT
2018-02-27 21:40:59,644 INFO [main] client.ConnectionManager$HConnectionImplementation: Closing master protocol: MasterService
2018-02-27 21:40:59,644 INFO [main] client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x161d70981710083
2018-02-27 21:40:59,646 INFO [main] zookeeper.ZooKeeper: Session: 0x161d70981710083 closed
2018-02-27 21:40:59,646 INFO [main-EventThread] zookeeper.ClientCnxn: EventThread shut down
# 当出现漏洞
hbase hbck -fixHdfsHoles
# 缺少regioninfo
hbase hbck -fixHdfsOrphans
# hbase region 引用文件出错
# Found lingering reference file hdfs:
hbase hbck -fixReferenceFiles
# 修复assignments问题
hbase hbck -fixAssignments
#启动Hbase
hbase master stop
hbase master start
service hbase-master restart
当HDFS文件异常时,导致Region处于FAILED_OPEN状态
现象:线上集群很多RegionServer短时间内频频宕机,有几个Region处于FAILED_OPEN状态
分析诊断:
1)查看系统监控以及RegionServer日志,确认RegionServer频繁宕机是因为大量CLOSE_WAIT状态的短连接导致。监控显示短时间内(4h)CLOSE_WAIT的数量从0增长到6w+。
2)再查看RegionServer日志查看到如下日志:
日志显示,Region 引用文件 打开失败,因此状态被设置为FAILED_OPEN,原因初步认为是FileNotFoundException导致,找不到的文件是Region 名称 下的一个文件,这两者之间有什么联系呢?
使用命令查看
hbase hbck
看到这里就一下恍然大悟,从引用文件可以看出来,Region ‘ 引用文件的ID ’是‘region名称ID ’ 的子Region,熟悉Split过程的童鞋就会知道,父Region分裂成两个子Region其实并没有涉及到数据文件的分裂,而是会在子Region的HDFS目录下生成一个指向父Region目录的引用文件,直到子Region执行Compaction操作才会将父Region的文件合并过来。
到这里,就可以理解为什么子Region会长时间处于FAILED_OPEN状态:因为子Region引用了父Region的文件,然而父Region的文件因为未知原因丢失了,所以子Region在打开的时候因为找不到引用文件因而会失败。而这种异常并不能通过简单的重试可以解决,所以会长时间掉入RIT状态。
现在基本可以通过RegionServer日志和hbck日志确定Region处于FAILED_OPEN的原因是因为子Region所引用的父Region的文件丢失导致。那为什么会出现CLOSE_WAIT数量暴涨的问题呢?经确认是因为Region在打开的时候会读取Region对应HDFS相关文件,但因为引用文件丢失所以读取失败,读取失败之后系统会不断重试,每次重试都会同datanode建立短连接,这些短连接因为hbase的bug一直得不到合理处理就会引起CLOSEE_WAIT数量暴涨。
解决方案:
1.尝试进行修复
2.如果解决不了进行删除,是因为数据block异常
操作指令
1.修复
1、查看 hbase 的请求数量是否过高,查看Request Per Second 并不高,排除热点问题,
2、检查表是否存在一致性问题
hbase hbck 检查输出所以ERROR信息,每个ERROR都会说明错误信息
hbase hbck -details hbase:meta
3、使用hbase用户尝试修复,在这之前要先确定hdfs上的tableinfo,regioninfo,region等数据都存在
修复.META.表损坏
META.表损坏的时候,HBase将启动失败,这种情况下要使用OFFlineMetaRepair工具创建新的META.表
该工具的工作原理是找到HBase在HDFS的主目录,加载Region的元数据文件信息,然后重新创建新的META.表:
hbase hbck -repair hbase:meta
hbase org.apache.hadoop.hbase.util.OffileMetaRepair
注意重启hbase关闭echo "balance_switch false" | hbase shell,重启之后开启true,并解决本地化低问题
注释:
hbase 一致性
.meta表和regionserver持有的region信息不一致,region缺失空洞,region重叠,meta元数据丢失等
检查
hbase hbck
Status:OK,表示没有发现不一致问题。
Status:INCONSISTENT,表示有不一致问题。
优雅下线regionserver hbase2.x
graceful_stop.sh做的工作是逐个地讲Region从RegionServer中移除,先移除一个Region,然后将这个Region安置到一个新的地方,再移除下一个,直到Region被全部移除。最后关闭RegionServer
整体修复hbase hbck -repair hbase:meta
空洞修复hbase hbck -repairHoles hbase:meta
hbase hbck -repair Shortcut for -fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps -fixReferenceFiles -fixHFileLinks -fixTableLocks -fixOrphanedTableZnodes
hbase hbck -repairHoles Shortcut for -fixAssignments -fixMeta -fixHdfsHoles
hbase hbck -repairHoles 修复holes
1、hbase hbck -fixMeta 修复meta表信息,利用regioninfo信息,重新生成对应meta row填写到meta表中,并为其填写默认的分配regionserver。
2、hbase hbck -fixHdfsHoles 修复region缺失,利用缺失的rowkey范围边界,生成新的region目录以及regioninfo填补这个空洞。
3、hbase hbck -fixAssignment 把这些offline的region触发上线,当region开始重新open上线的时候,会被重新分配到真实的RegionServer上 , 并更新meta表上对应的行信息。
hbase hbck -repair 包含以上空洞修复同时还包括修复tableinfo缺失,regioninfo缺失,region重叠等整体修复
1、hbase hbck -fixTableOrphans 先修复tableinfo缺失问题,根据内存cache或者hdfs table 目录结构,重新生成tableinfo文件。
2、hbase hbck -fixHdfsOrphans 修复regioninfo缺失问题,根据region目录下的hfile重新生成regioninfo文件3、hbase hbck -fixHdfsOverlaps 修复region重叠问题,merge重叠的region为一个region目录,并从新生成一个regioninfo。
命令指数详情
1.局部修复
1如果出现数据不一致,修复是要最大限度的降低可能出现的风险,使用以下命令对region进行修复风险较低:
1.1 hbase hbck -fixAssignments
命令解释:修复region 没有分配(unassigned),错误分配(incorrectly assigned)以及多次分配(multiply assigned)的问题
1.2 hbase hbck -fixMeta
命令解释:删除META表里有记录但HDFS里没有数据记录的region
添加HDFS里有数据但是META表里没有记录的region到META表
1.3hbase hbck -repairHoles
命令解释:hbase hbck -fixAssignments -fixMeta -fixHdfsHoles
-fixHdfsHoles的作用:
命令解释:如果rowkey出现空洞,即相邻的两个region的rowkey不连续,则使用这个参数会在HDFS里面创建一个新的region
创建新的region之后要使用-fixMeta和-fixAssignments参数来使用挂载这个region,所以一般和前两个参数一起使用
region重叠修复
进行以下操作非常危险,因为这些操作会修复文件系统,需要谨慎操作!
进行以下操作前使用hbck -details 查看详细的问题,如果需要进行修复先停掉应用,如果执行以下命令同时有数据操作可能会造成不可期的异常
2.1 hbase hbck -fixHdfsOrphants
命令解释:将文件系统中没有metadata文件(.regioninfo)的region目录加入到hbase中,即创建.regioninfo目录并
region 分配到regionserver
2.2hbase hbck -fixHdfsOverlaps
命令解释:通过2种方式可以将rowkey有重叠的region合并
1).merge:将重叠的region合并成一个大的region
2).sideline将region重叠的部分去掉,并将重叠的数据先写入到临时文件,然后再导入进来
如果重叠的数据很大,直接合并成一个大的region会产生大量的split和compact操作,可以通过以下参数控制region过大
-maxMerger 合并重叠region的最大数量
-sidelineBigOverlaps假如有大于maxMerge个数的region重叠,则采用sideline方式处理与其他region的重叠
-maxOverlapsToSideline 如果用sideline方式处理重叠region,最多sideline n个region
2.3hbase hbck -repair
命令解释:等价于:hbase hbck -fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile -sidelineBigOverlaps
可指定表名:hbase hbck -repair Table1 Table2
2.4hbase hbck -fixMetaOnly -fixAssignments
命令解释:如果只有META表的region不一致,则可以使用这个命令恢复
2.5hbase hbck -fixVersionFile
命令解释:Hbase 的数据文件启动是需要一个version file ,如果这个文件丢失,可用这个命令新建一个,但是要保障hbck 版本
和Hbase集群的版本是一样的
2.6hbase org.apache.hadoop.hbase.util.hbck.offlineMetaRepair
命令解释:如果ROOT表和META表都出现问题了HBASE无法启动,可用这个命令来新建一个新的ROOT和META表
这个命令的前提是HBASE 已经关闭,执行时它会从hbase的home目录加载hbase的相关信息(.regioninfo).如果表的信息
是完整的就会创建新的root和meta目录及数据
2.7hbase hbck -fixSplitParents
命令解释:
当region做split操作的时候,父region会被自动清理掉,但是有时候子region在父region被清除之前又做了split,造成有些延迟离线的
父region存在于META和HDFS中,但是没有部署,HBASE又不能清除他们。这种情况下可以使用此命令重置这些在META表中的region
为在线状态并且没有split,然后就可以使用之前的修复命令把这个region修复
根据报错来确定使用哪个参数




备注参考:
HBCK 参数解释
-fixAssignments :修复没有assign、assign不正确或者同时assign到多台RegionServer的问题region。
-fixMeta :主要修复.regioninfo文件和hbase:meta元数据表的不一致。修复的原则是以HDFS文件为准:如果region在HDFS上存在,但在hbase.meta表中不存在,就会在hbase:meta表中添加一条记录。反之如果在HDFS上不存在,而在hbase:meta表中存在,就会将hbase:meta表中对应的记录删除。
-fixHdfsHoles :尝试修复HDFS中的Region黑洞;
-fixHdfsOrphans:尝试修复hdfs中没有.regioninfo文件的region目录
-fixTableOrphans 尝试修复hdfs中没有.tableinfo文件的table目录(只支持在线模式)
-fixHdfsOverlaps 修复重叠
-fixVersionFile 尝试修复hdfs中hbase.version文件缺失的问题;
总结
永久性掉入RIT状态其实出现的概率并不高,都是在一些极端情况下才会出现。绝大部分RIT状态都是暂时的。
一旦掉入永久性RIT状态,说明一定有根本性的问题原因,只有定位出这些问题才能彻底解决问题
如果Region长时间处于PENDING_CLOSE或者CLOSING状态,一般是因为RegionServer在关闭Region的时候遇到了长时间Compaction任务或Flush任务,所以如果Region在做类似于Major_Compact的操作时尽量不要执行unassign操作,比如move操作、disable操作等;而如果Region长时间处于FAILED_OPEN状态,一般是因为HDFS文件出现异常所致,可以通过RegionServer日志以及hbck定位出来

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)