手把手教你通过ElasticSearch、FSCrawler及 SearchUI搭建文件搜索引擎
文章目录一、需求一、需求公司内部存在大量的设备保修保养文件,
·
一、需求分析
- 公司内部存在大量的设备维修保养office文档,设备人员在检索特定的维修保养知识的时候,需要根据目录的索引文件,在服务器上先找出有可能相关的文件列表,再一一打开进行检索,效率低下且体验性差。
- 用户希望利用现有文档系统(编制,发布,升版等文控管理有专人负责)不变,搭建一个可以根据关键词条进行检索的文件搜索引擎,提高效率及提升体验度。
- 本文将通过ElasticSearch(开源搜索引擎),FSCrawler(文件爬虫,将文档“上传”到 elasticsearch), SearchUI(使用elasticsearch搜索 API 的前端页面),搭建一个文件搜索引擎系统。
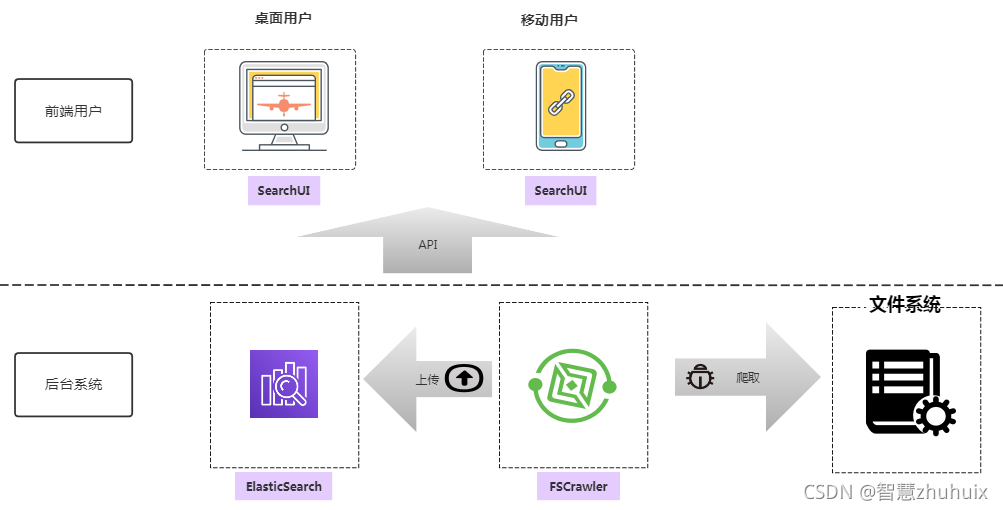
二、ElasticSearch
-
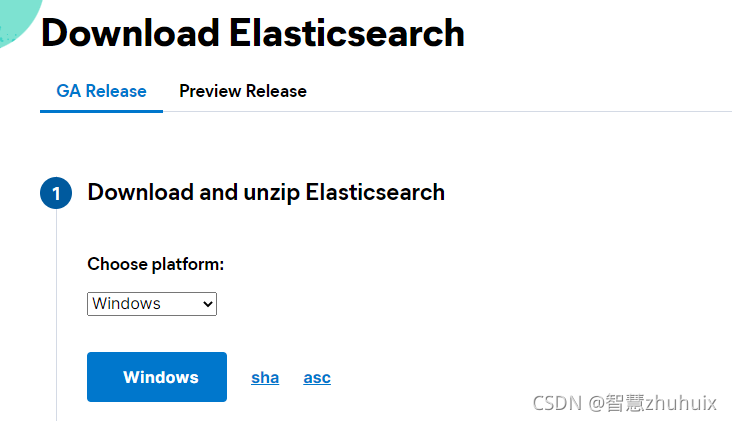
我们首先从(https://www.elastic.co/cn/downloads/elasticsearch下载文件(本文以windows版本为例)。
-
解压文件

-
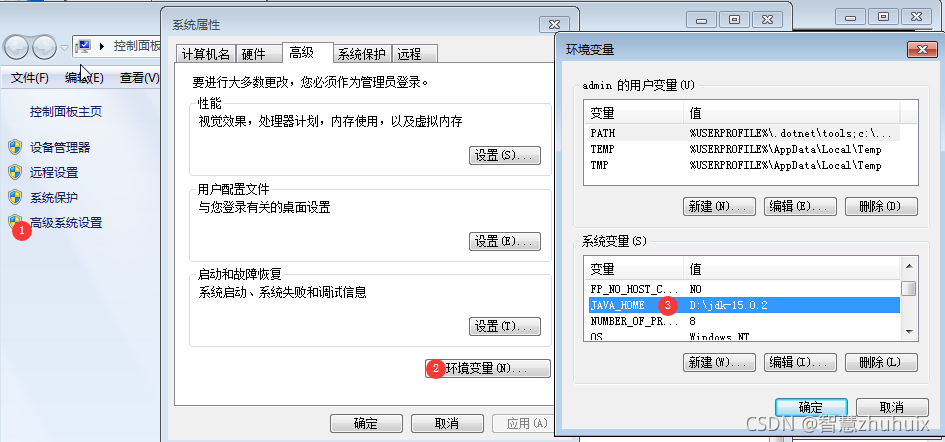
下载安装jdk并设置java环境变量
-
进入到解压后的bin目录,双击elasticsearch.bat文件运行
-
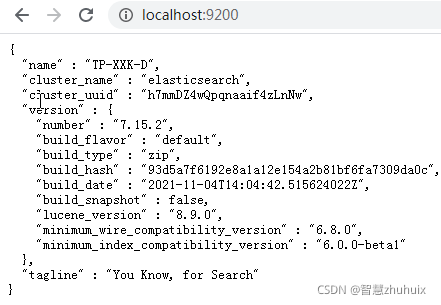
验证ElasticSearch是否启动成功:使用浏览器访问http://localhost:9200,看到以下页面就代表安装成功了
三、FSCrawle
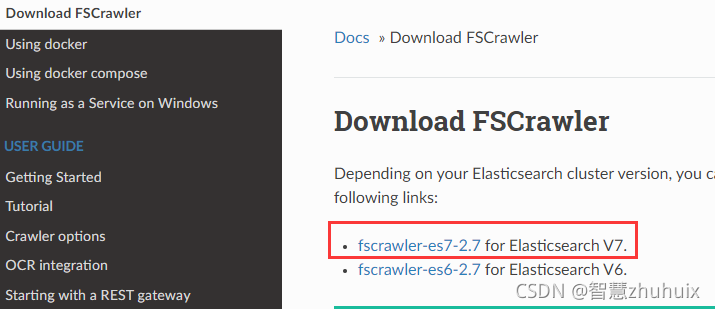
- 我们再从https://fscrawler.readthedocs.io/en/fscrawler-2.7/installation.html下载文件(本文以windows版本为例)。
- 解压文件


- 创建文件爬取job
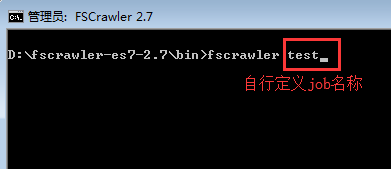
- 运行以上命令后,程序提示是否创建该job
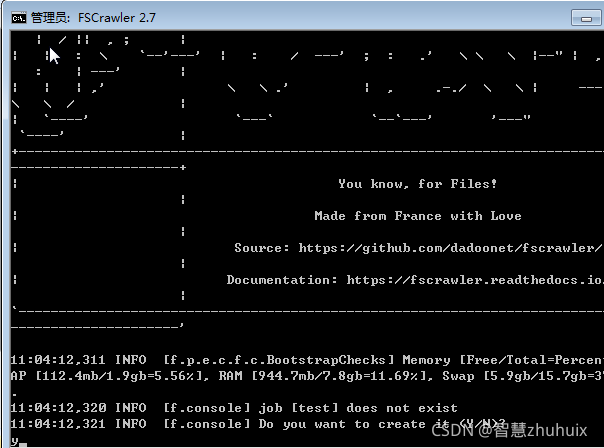
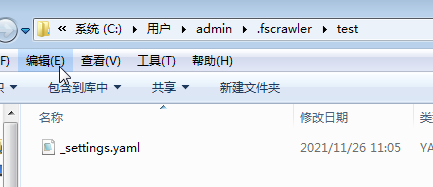
- 选择y,程序会在用户目录下创建以下配置文件,我们需要对该任务进行配置
---
name: "test"
fs:
url: "d:\\test" # 监控windows下的D盘test目录
update_rate: "15m" # 间隔15分进行扫描
excludes:
- "*/~*" #排除以~开头的文件
json_support: false
filename_as_id: false
add_filesize: true
remove_deleted: true
add_as_inner_object: false
store_source: false
index_content: true
attributes_support: false
raw_metadata: false
xml_support: false
index_folders: true
lang_detect: false
continue_on_error: false
ocr:
language: "eng"
enabled: true
pdf_strategy: "ocr_and_text"
follow_symlinks: false
elasticsearch:
nodes:
- url: "http://127.0.0.1:9200"
bulk_size: 100
flush_interval: "5s"
byte_size: "10mb"
ssl_verification: true
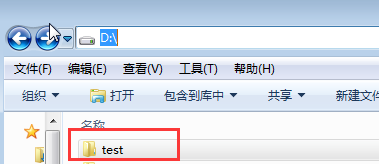
- 保存配置后,我们就可启动FSCrawle爬虫程序了:
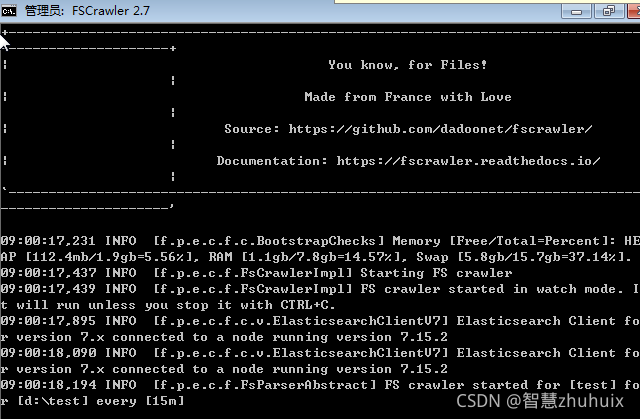
- 启动成功后,我们在原有的配置目录会发现多出一个状态文件,该文件会记录文件爬虫程序的定时运行记录:
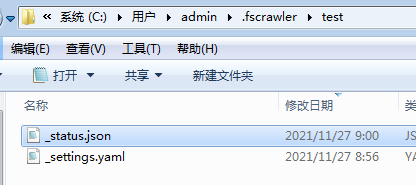
{
"name" : "test",
"lastrun" : "2021-11-27T09:00:16.2043064",
"indexed" : 0,
"deleted" : 0
}
三、SearchUI
- 我们最后从https://github.com/elastic/search-ui下载前端页面:
- 文件解压后,用vscode打开examples\elasticsearch目录:
- 并依次修改search.js、buildRequest.js、buildState.js文件
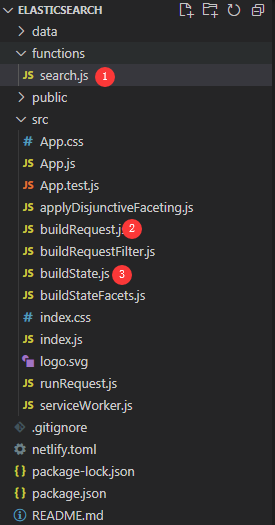
- 修改search.js:设定job路径
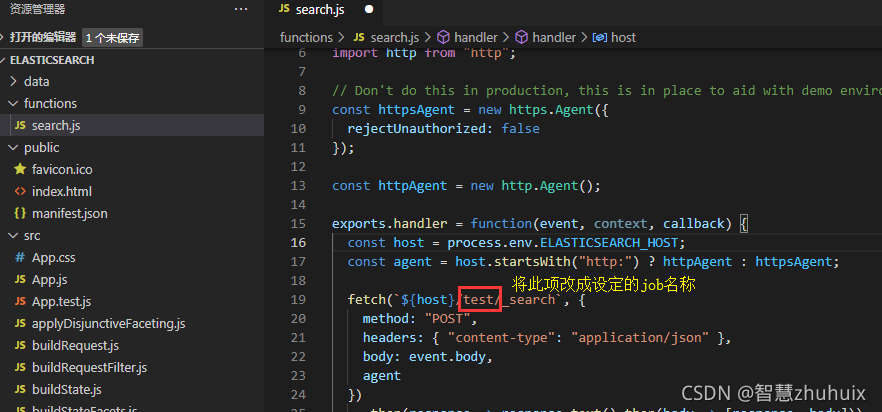
- 修改buildRequest.js
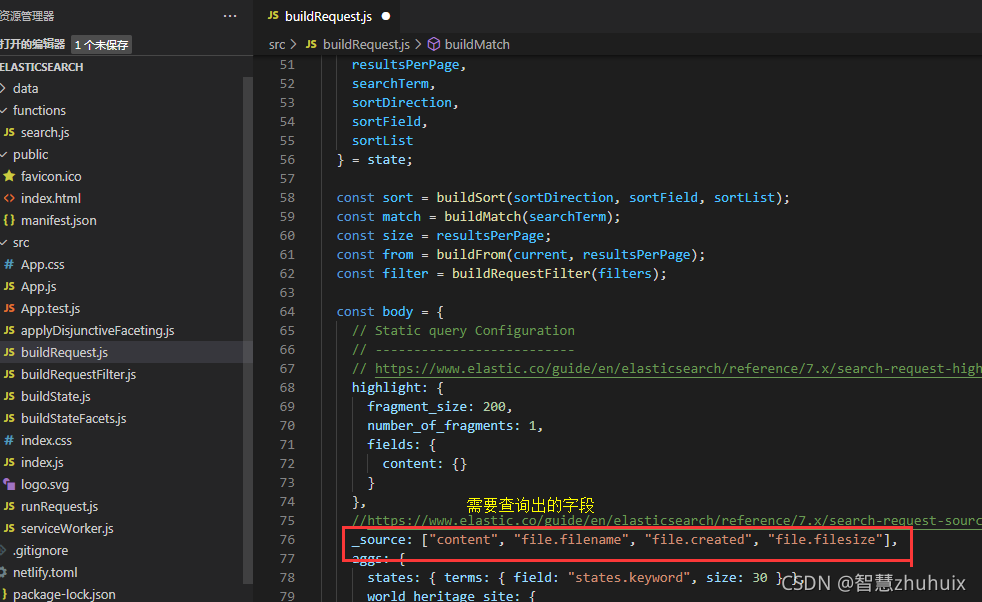
- 修改buildState.js
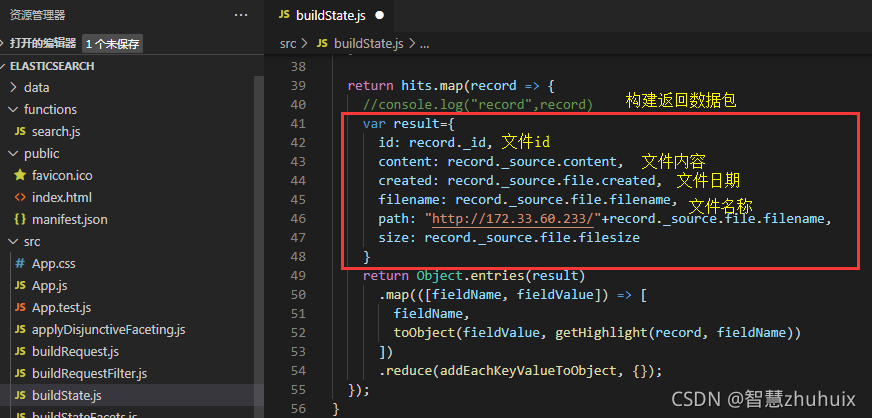
- 注意:为了让用户在搜索页面上可以直接通过文件链接下载文件,我们通过IIS搭建文件下载服务:
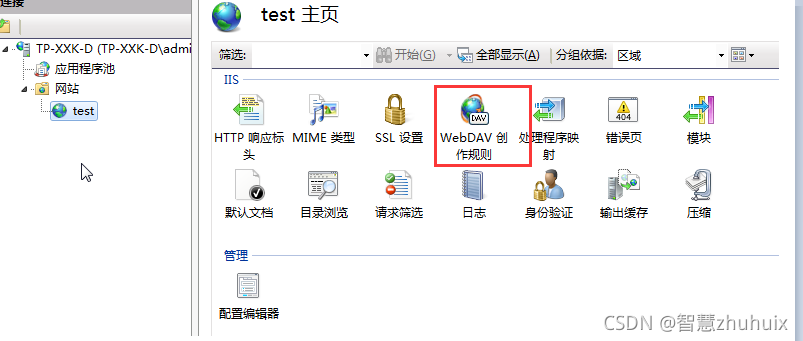
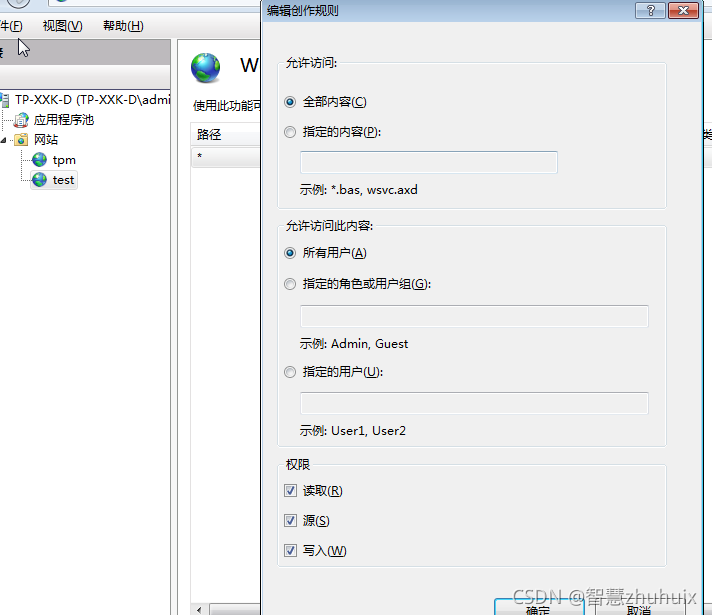
- 该地址反映在在buildState.js中
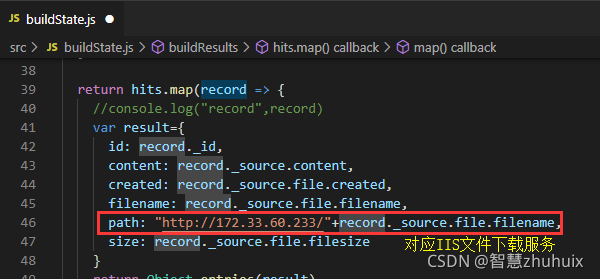
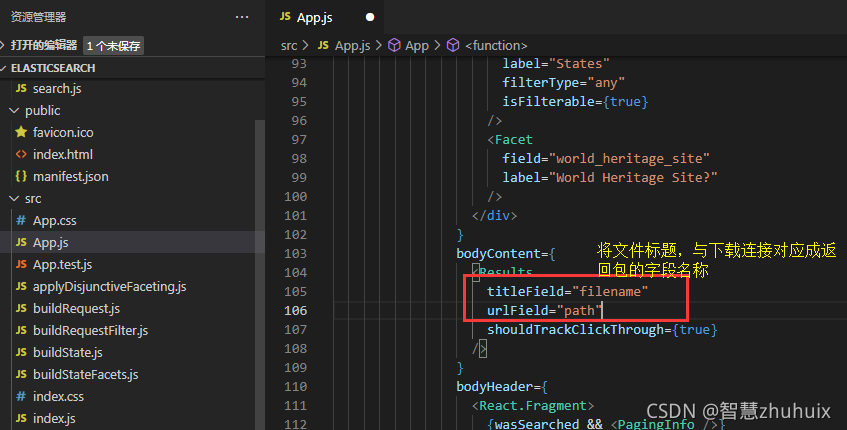
- 最后我们修改一下app.js,将搜索返回的页面与搜索字段名称进行对应
五、运行测试
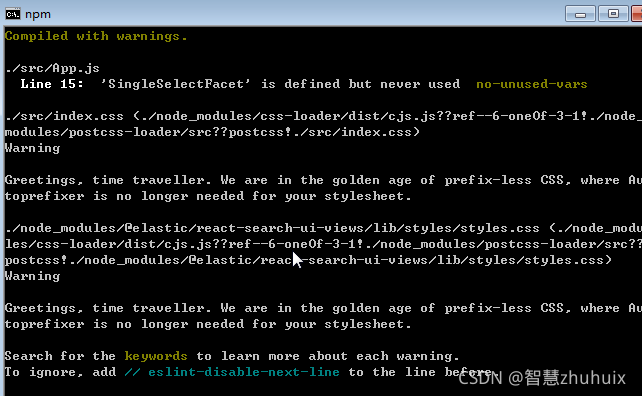
- 安装依赖包,运行程序
# 安装
- npm install
# 运行
- npm start
-
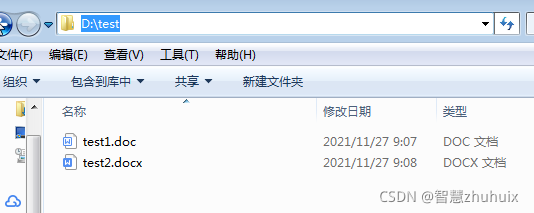
放置文件到FSCrawler监控的目录下
-
测试搜索效果


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)