java使用hbase过滤器
1.什么是过滤器过滤器可以根据列族、列、版本等更多的条件来对数据进行过滤, 基于 HBase 本身提供的三维有序(行键,列,版本有序),这些过滤器可以高效地完成查询过滤的任务,带有过滤器条件的 RPC 查询请求会把过滤器分发到各个 RegionServer(这是一个服务端过滤器),这样也可以降低网络传输的压力。2.比较运算符LESS <LESS_OR_EQUAL <=EQUAL =NO
目录
单列值过滤器:SingleColumnValueFilter
列值排除过滤器:SingleColumnValueExcludeFilter
1.什么是过滤器
过滤器可以根据列族、列、版本等更多的条件来对数据进行过滤, 基于 HBase 本身提供的三维有序(行键,列,版本有序),这些过滤器可以高效地完成查询过滤的任务,带有过滤器条件的 RPC 查询请求会把过滤器分发到各个 RegionServer(这是一个服务端过滤器),这样也可以降低网络传输的压力。
过滤器的类型很多,但是可以分为两大类:
-
比较过滤器:可应用于rowkey、列簇、列、列值过滤器
-
专用过滤器:只能适用于特定的过滤器
2.比较运算符
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
NO_OP 排除所有
3 .常见的六大比较器(3,4不太常用)
BinaryComparator:按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparato:只是比较左端前缀的数据是否相同
NullComparator:判断给定的是否为空
BitComparator:按位比较
RegexStringComparator:提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator:判断提供的子串是否出现在中
4. 通用过滤器
首先这是连接hbase,以及传入过滤器,打印返回值的方法
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class FilterTest1 {
Connection conn;
Admin admin;
TableName studentTTN;
Table student;
@Before
public void getConn() throws IOException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","master:2181,node1:2181,node2:2181");
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
studentTTN = TableName.valueOf("student");
student = conn.getTable(TableName.valueOf("student"));
}
/**
*创建一个Scan对象,设置过滤器
*通过getScanner()方法获取所有过滤出来的数据,返回result数组
*遍历这个数组,将值一一取出来
*/
public void printFilter(Filter filter) throws IOException {
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = student.getScanner(scan);
for (Result result : scanner) {
String id = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue("info".getBytes(), "name".getBytes()));
String age = Bytes.toString(result.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(result.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(result.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
}
}
}列值过滤器:ValueFilter
/**
*列值过滤器ValueFilter
* 比较方法:对每个单元(cell)内容进行比较,一般不太符合要求
* 我们进行比较的时候需要比较符和比较器
*/
@Test
public void ValueFilter() throws IOException {
//二进制比较器,传入23的字节数组形式
BinaryComparator binaryComparator = new BinaryComparator("23".getBytes());
//采用列值过滤器,里面传入比较符(大于),比较器
ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.GREATER, binaryComparator);
printFilter(valueFilter);
}返回结果: 将所有行的数据都返回了,这是因为列值过滤器会将每一个cell的数据作比较,比如第一行,她的年龄没有到达23,但是15001000001他的ascii码比23大,这一行显示的所有其他数据都是比23要大的,只要一个cell符合条件,就返回这条数据

RowFilte 行键过滤器
@Test
/**
* RowFilte 行键过滤器
* 过滤出rowkey(id)以150010089开头的学生信息
*/
public void RowFilter() throws IOException {
//BinaryPrefixComparator:二进制前缀过滤器,筛选条件是左端数据是'150010089'
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("150010089".getBytes());
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, binaryPrefixComparator);
printFilter(rowFilter);
}结合了行键过滤器,可以看到返回的都是rowkey左端数据是'150010089'的
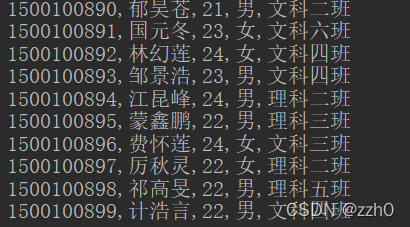
列过滤器:QualifierFilter
*/
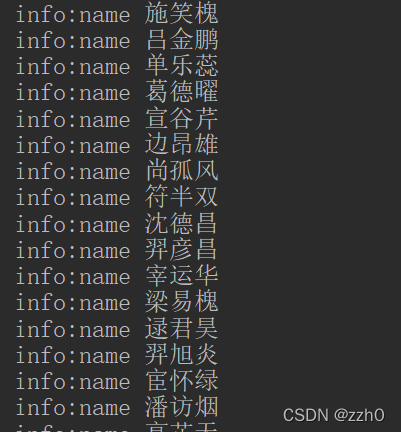
public void SubStringQualifierFilter() throws IOException {
//这里用到了子字符串比较器,需要目标内容中含有'na'这个字符串
SubstringComparator comparator = new SubstringComparator("na");
QualifierFilter qualifierFilter = new QualifierFilter(CompareFilter.CompareOp.EQUAL, comparator);
Scan scan = new Scan();
scan.setFilter(qualifierFilter);
ResultScanner scanner = student.getScanner(scan);
for (Result rs : scanner) {
for (Cell cell : rs.listCells()) {
String cf = Bytes.toString(CellUtil.cloneFamily(cell));
String q = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(cf + ":" + q + " " + value);
}
}
}
}
列簇过滤器:FamilyFilter
//过FamilyFilter查询列簇名包含in的所有列簇下面的数据
@Test
public void SubstringComparatorFilter() throws IOException {
//比较值过滤器,以"in"为前缀
SubstringComparator info = new SubstringComparator("in");
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, info);
printFilter(familyFilter);
}结果:列簇名中含有"in"的数据都返回了
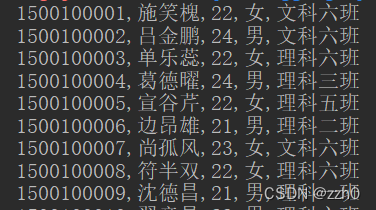
5.专用过滤器
单列值过滤器:SingleColumnValueFilter
这里有需要注意的地方,如果比较的列值中有null,是会将这行数据打印出来的,无法过滤掉
@Test
/**
* SingleColumnValueFilter 单列值过滤器
* 可以指定一个列进行过滤
* 该过滤器会将符合过滤条件的列对应的cell所在的整行数据进行返回
* 如果某条数据的列不符合条件,则会将整条数据进行过滤
* 如果数据中不存在指定的列,则默认会直接返回
*
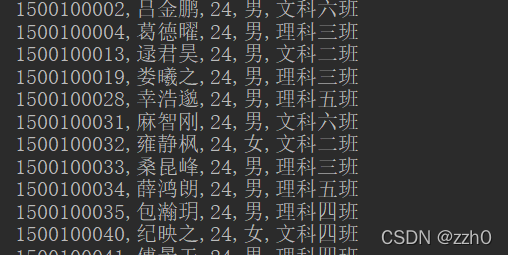
* age > 23 的学生
*/
public void SingleColumnValueFiter() throws IOException {
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
"info".getBytes(),
"age".getBytes(),
CompareFilter.CompareOp.GREATER,
"23".getBytes()
);
printFilter(singleColumnValueFilter);
}
列值排除过滤器:SingleColumnValueExcludeFilter
/**
与SingleColumnValueFilter相反,会排除掉指定的列,其他的列全部返回
通过SingleColumnValueExcludeFilter与BinaryComparator
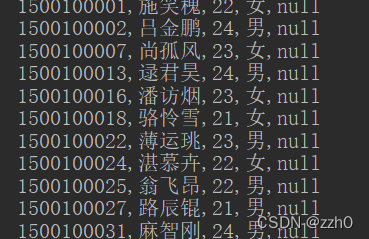
查询文科所有学生信息,最终不返回clazz列
*/
@Test
public void SingleColumnValueExculdeFilter() throws IOException {
//比较过滤器,以"文科"为前缀
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("文科".getBytes());
SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter(
"info".getBytes(),
"clazz".getBytes(),
CompareFilter.CompareOp.EQUAL,
binaryPrefixComparator
);
printFilter(singleColumnValueExcludeFilter);
}
rowkey前缀过滤器:PrefixFilter
@Test
/**
* 过滤出rowkey(id)以150010089开头的学生
* 使用PrefixFilter:rowkey前缀过滤器
* 相当于BinaryPrefixComparator+RowFilter
*/
public void PrefixFilter() throws IOException {
PrefixFilter prefixFilter = new PrefixFilter("150010089".getBytes());
printFilter(prefixFilter);
}这样结果和上面一样:但是 少创建了一个比较过滤器
分页过滤器 PageFilter
我这里实现的功能和mysql中的limit m,n类似
将上个传入 PageFilter中rowkey 存储起来,作为下面 PageFilter查询的开始位置,再设置一下返回的数据条数,就可以得到分页查询的结果
@Test
/**
* 通过PageFilter查询第三页的数据,每页10条
*
* 使用PageFilter分页效率比较低,每次都需要扫描前面的数据,直到扫描到所需要查的数据
*
* 可设计一个合理的rowkey来实现分页需求
*/
public void PageFilter1() throws IOException {
int pagenum=4;
int pagesize=10;
int start_num=(pagenum-1)*pagesize+1;
// PageFilter里面传入int类型值
PageFilter pageFilter = new PageFilter(start_num);
Scan scan = new Scan();
scan.setFilter(pageFilter);
ResultScanner scanner = student.getScanner(scan);
//这里循环不断给rowkey赋新值,最后一次的rowkey是我们需要的
String rowkey=null;
for (Result result : scanner) {
rowkey = Bytes.toString(result.getRow());
}
System.out.println(rowkey);
Scan scan1 = new Scan();
scan1.withStartRow(rowkey.getBytes());
PageFilter pageFilter1 = new PageFilter(pagesize);
scan1.setFilter(pageFilter1);
ResultScanner scanner1 = student.getScanner(scan1);
for (Result rs : scanner1) {
String id = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
String age = Bytes.toString(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
}
}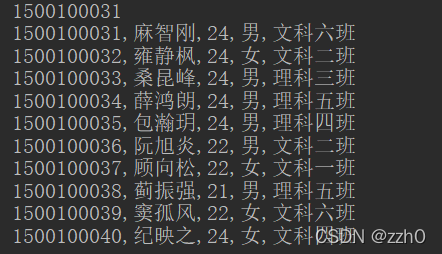
如果我们在设置行键的时候就注意到了要设置一定的规律,就不用前面获取开始位置的Rowkey这个操作, 比如说rowkey是从1500100000开始到1500101000的连续数字,我就直接可以知道第31也的rowkey是1500100031,直接设置PageFilter为10就好了
{ Scan scan = new Scan();
scan.withStartRow("1500100031".getBytes());
PageFilter pageFilter = new PageFilter(10);
scan1.setFilter(pageFilter);
ResultScanner scanner = student.getScanner(scan);
for (Result rs : scanner) {
String id = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
String age = Bytes.toString(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
}多过滤器综合查询 FilterList
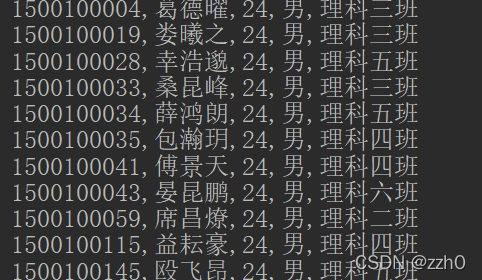
可以向FilterList添加多个过滤器,返回的是满足所有过滤条件的数据
@Test
/**
* 过滤 gender为男,age>23,理科班的学生
* 过条件过滤需要使用FilterList
*/
public void MultipleFilter() throws IOException {
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(
"info".getBytes(),
"gender".getBytes(),
CompareFilter.CompareOp.EQUAL,
"男".getBytes()
);
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(
"info".getBytes(),
"age".getBytes(),
CompareFilter.CompareOp.GREATER,
"23".getBytes()
);
SingleColumnValueFilter filter3 = new SingleColumnValueFilter(
"info".getBytes(),
"clazz".getBytes(),
CompareFilter.CompareOp.EQUAL,
new BinaryPrefixComparator("理科".getBytes())
);
FilterList filterList = new FilterList();
filterList.addFilter(filter1);
filterList.addFilter(filter2);
filterList.addFilter(filter3);
printFilter(filterList);
}
}结果:

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)