分布式多个机器生成id,如何保证不重复?
参考:分布式多个机器生成id,如何保证不重复? - 简书目录1.snowflake方案:优点:缺点:2.用Redis生成ID:优点:缺点:3. UUID优点:缺点:4 美团 Leaf设计一个全局唯一的ID,需要唯一性,时间作为一个比较重要的点,并行生成ID,同一时间尽可能细化,比如一毫秒内50台机器都被调用这个API生成ID,根据机器的不同再标识。一台机器如果运算速度快,可能1ms应该会有挺多ID
更多场景设计题参看:
场景设计题 汇总 (一)_trigger333的博客-CSDN博客
目录
简单的想法
设计一个全局唯一的ID,需要唯一性,时间可以作为一个区分点,时间尽可能细化,精确到ms。
如果机器很多,并行生成ID,比如一毫秒内50台机器都被调用这个API生成ID,那么可以根据机器的不同再进行标识和区分。
一台机器如果运算速度快,可能1ms应该会有大量ID 生成,这种情况可以结合实际问题,限制一台机器1ms内生成的ID数量,比如至多m个。
如果N台机器都去一个叫ID生成服务器的服务器去得到全局ID,是很容易保证全局唯一且自增的,但是存在单点失效的问题,不满足高可用。
1.snowflake方案:
理解分布式id生成算法SnowFlake - SegmentFault 思否
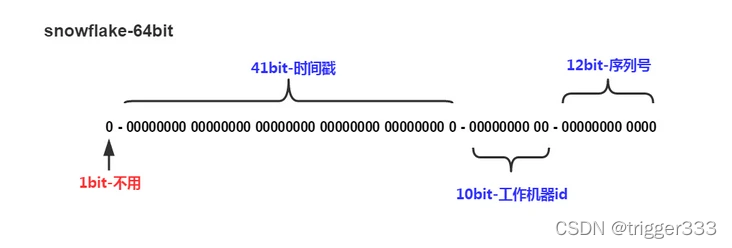
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID(64位)。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
可以表示的时间长度是69年,表示1024台机器,一个毫秒内可以有4096个ID。
优点:
1.毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
2.不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
3.可以根据自身业务特性分配bit位,非常灵活。
缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
Twitter的分布式雪花分片ID算法(SnowFlake)每秒自增生成26个万个可排序的ID (Java版)_HD243608836的博客-CSDN博客
2.用Redis生成ID:
因为Redis是单线程的,也可以用来生成全局唯一ID。可以用Redis的原子操作INCR和INCRBY来实现。
此外,可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis,可以初始化每台Redis的值分别是1,2,3,4,5,步长都是5,各Redis生成的ID如下:
A:1,6,11,16
B:2,7,12,17
C:3,8,13,18
D:4,9,14,19
E:5,10,15,20
这种方式是负载到哪台机器提前定好,未来很难做修改。3~5台服务器基本能够满足需求,都可以获得不同的ID,但步长和初始值一定需要事先确定,使用Redis集群也可以解决单点故障问题。
另外,比较适合使用Redis来生成每天从0开始的流水号,如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量较大。
3. UUID
常见的方式。可以利用数据库也可以利用程序生成,一般来说全球唯一。UUID是由32个的16进制数字组成,所以每个UUID的长度是128位(16^32 = 2^128)。UUID作为一种广泛使用标准,有多个实现版本,影响它的因素包括时间、网卡MAC地址、自定义Namesapce等等。
优点:
1)简单,代码方便。
2)生成ID性能非常好,基本不会有性能问题。
3)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
1)没有排序,无法保证趋势递增。
2)UUID往往是使用字符串存储,查询的效率比较低。
3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
4)传输数据量大
5)不可读。
4 美团 Leaf

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)