Elasticsearch 入门到精通-Elasticsearch数据写入(写入流程)
Elasticsearch数据写入流程
Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。这样就能实现分布式了。 以下是Elasticsearch单个文档的写入简单流程。
1、数据写入的简单流程
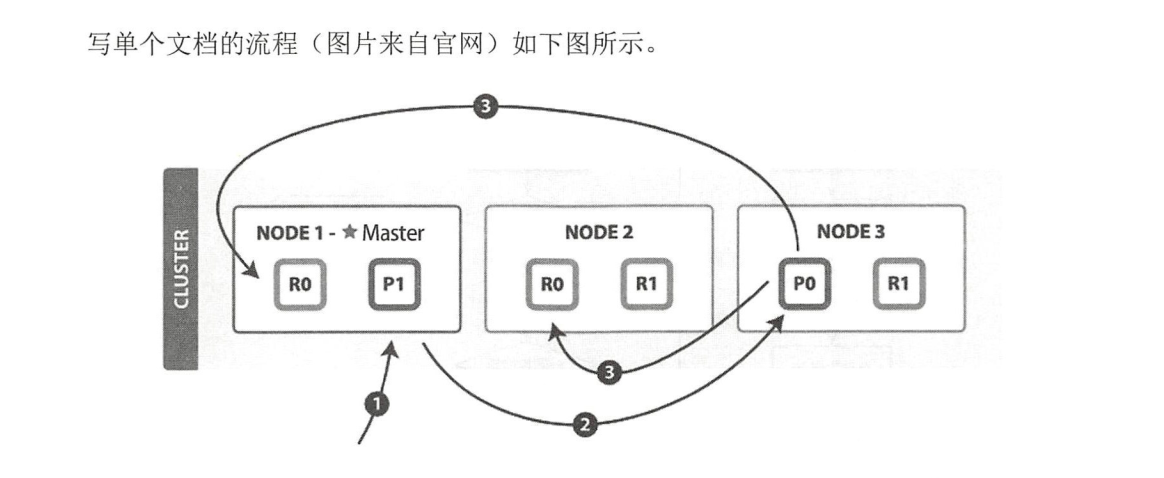
以下是写单个文档所需的步骤:
1、客户端向 NODE I 发送写请求。
2、检查Active的Shard数。
3、NODEI 使用文档 ID 来确定文档属于分片 0,通过集群状态中的内容路由表信息获知分片 0 的主分片位于 NODE3 ,因此请求被转发到 NODE3 上。
4、NODE3 上的主分片执行写操作 。 如果写入成功,则它将请求并行转发到 NODE I 和
NODE2 的副分片上,等待返回结果 。当所有的副分片都报告成功, NODE3 将向协调节点报告
成功,协调节点再向客户端报告成功 。
5、在客户端收到成功响应时 ,意味着写操作已经在主分片和所有副分片都执行完成。
2、索引与分片的关系
分片是一个底层的 工作单元,一个分片是一个 Lucene 的实例,它本身就是一个完整的搜索引擎,文档不会跨分片存储。
索引与分片的关系图:

3、数据写入详细流程

1、将document写入内存buffer缓存中,同时写入到translog中
2、每隔一秒钟,buffer中的数据被写入新的segment file,
3、同时进入os cache,此时index segment file被打开并供search使用,
4、buffer被清空
5、重复1~3,新的segment不断添加,buffer不断被清空,而translog中的数据不断累加
6、当translog长度达到一定程度的时候,commit操作发生
(6-1)buffer中的所有数据写入一个新的segment,并写入os cache,打开供使用
(6-2)buffer被清空
(6-3)一个commit ponit被写入磁盘,标明了所有的index segment
(6-4)filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
7、现有的translog被清空,创建一个新的translog
4、写入一条数据,在Elasticsearch中怎么确定数据写在哪个节点上?
1、当客户端对一个node发出写入请求,这个node可以称为协调节点
2、协调节点会将document路由到实际节点node的primary shard上,
3、当主分片成功处理这个请求,将请求并行发给副本分片,primary shard 对应的replica shard ,备份分片可能不止一个,主分片和备份不会在同一台机子上()
4、当primary和replica 都写完后,primary节点向协调节点报告成功,协调节点返回结果给客户端
ES路由规则
写入数据和读取数据都是,以下算法实现:
shard_num = hash(_routing) % num_primary_shards
// _routing:一般都是doc_id
// num_primary_shards:主分片数量- 对数据的doc_id进行hash之后的值
- 在对主要分片数量求余,获得对应编号的主分片
所以 创建索引的时候就确定好主分片的数量,并且永远不会改变这个数量。
如果变了, 那么所有之前路由的值都会无效,文档也再也找不到了。
这时候协调节点就要发请求到各个分片节点上进行查询,这种操作会给集群带来负担,增大了网络的开销。
而自定义的Routing模式,将同一个种类的数据放在相同分片上,这是时候查apple就直接去P1分片上查询就行了。
自定义路由
设置路由的两种方式
// 样例1 指定routing为 key1
PUT route_test1/_doc/b?routing=key1
{
"type":"apple"
"data": "red apple"
}
//样例2 指定type字段作为路由
PUT route_test1/_doc/_mapping
{
"order": {
"_routing": {
"required": true,
"path": "type" //指定文档的字段作为路由
}
}
}
# 也可以去查询多个路由
GET route_test/_search?routing=key1,key2
{
"query": {
"match": {
"type": "apple"
}
}
}另外,指定routing还有个弊端就是容易造成负载不均衡(apple 数据量远大于其他数据)。
所以ES提供了一种机制可以将数据路由到多个shard上面。
只需在创建索引时(也只能在创建时)设置index.routing_partition_size,默认值是1,即只路由到1个shard,可以将其设置为大于1且小于索引shard总数的某个值,就可以路由到多个shard了。
shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)