kafka 选举机制原理解析
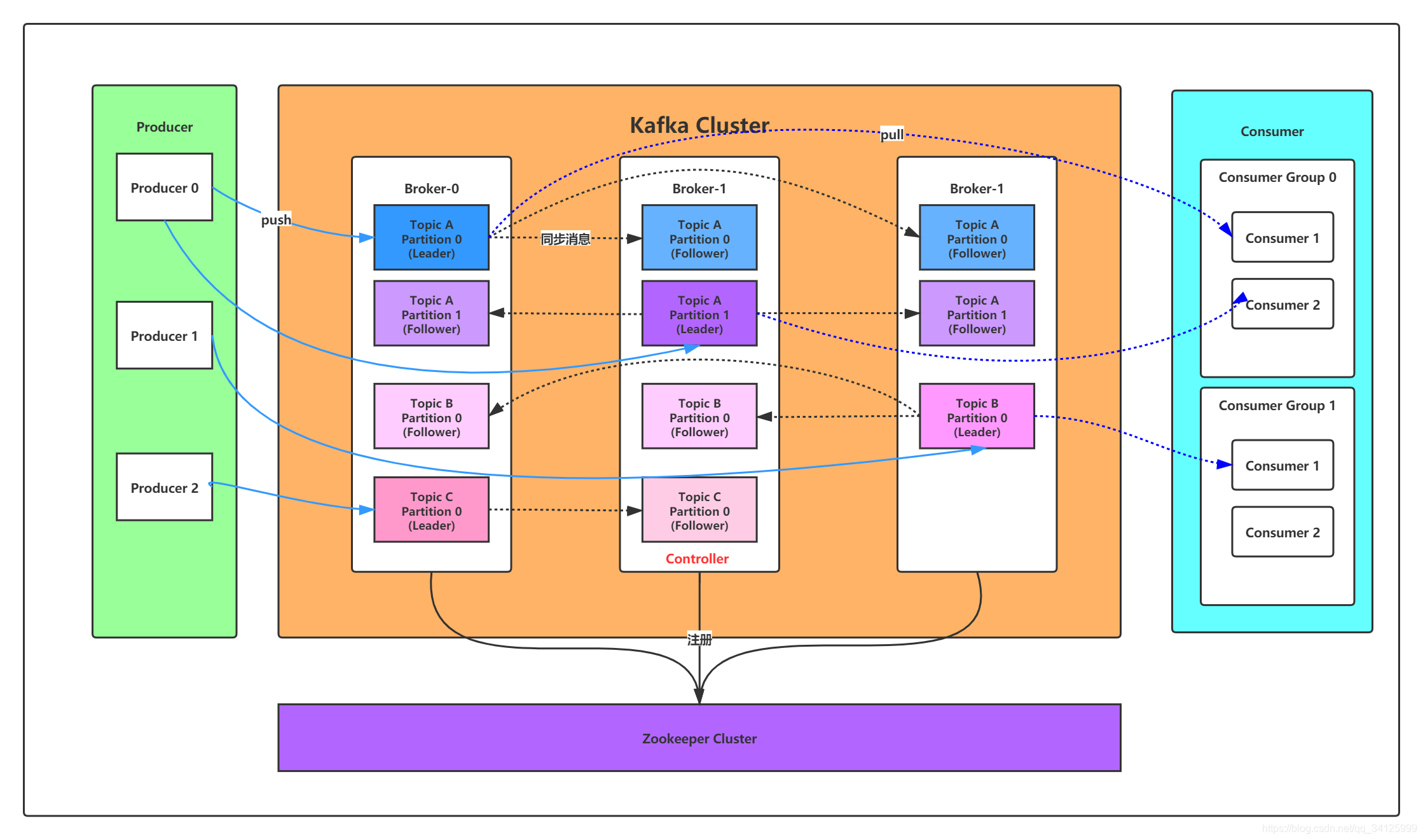
1 Controller在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。(1) 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。(2) 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。(3) 当使用ka
1 Controller
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
(1) 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
(2) 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
(3) 当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责让新分区被其他节点感知到。
Controller选举机制:
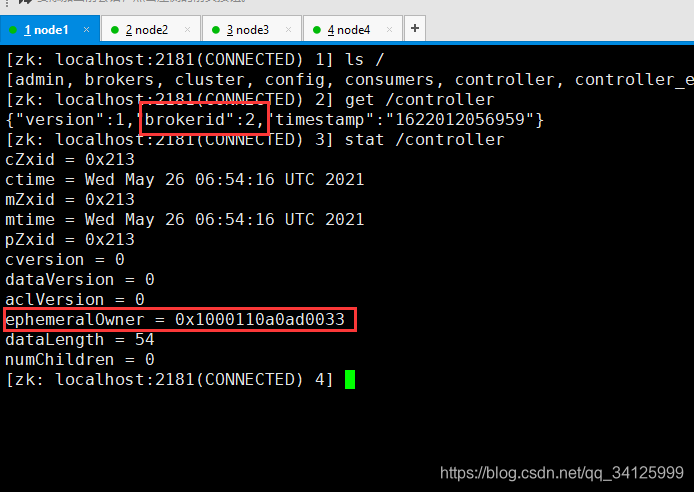
在kafka集群启动的时候,会自动选举一台broker作为controller来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个 /controller 临时节点,zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控器controller。 当这个controller角色的broker宕机了,此时zookeeper临时节点会消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点,就是我们上面说的选举机制,zookeeper又会保证有一个broker成为新的controller。
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
(1) 监听broker相关的变化。为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
(2) 监听topic相关的变化。为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
(3) 从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
(4) 更新集群的元数据信息,同步到其他普通的broker节点中。
2 Partition副本选举Leader机制
controller感知到分区leader所在的broker挂了(controller可以监听zookeeper /brokers/ids),controller会从ISR列表里挑第一个broker作为leader(第一个broker最先放进ISR列表,可能是同步数据最多的副本),如果参数unclean.leader.election.enable为true,代表在ISR列表里所有副本都挂了的时候可以在ISR列表以外的副本中选leader,这种设置,可以提高可用性,但是选出的新leader有可能数据少很多。
#创建3副本主题
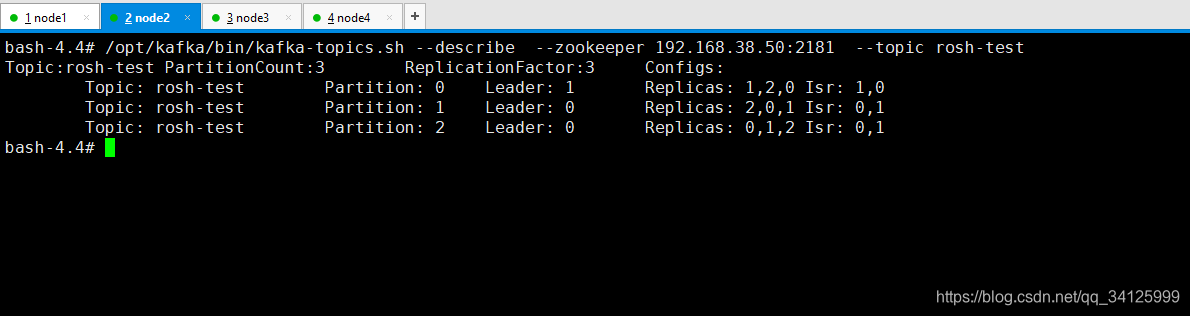
/opt/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.38.50:2181 --replication-factor 3 --partitions 3 --topic rosh-test
#查看主题
/opt/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.38.50:2181 --topic rosh-test

停掉node4的kafka
#node4
docker stop kafka
#查看主题
/opt/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.38.50:2181 --topic rosh-test

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)