搜索引擎(大数据检索)论述[elasticsearch原理相关]
这是基本的词项存储列表,词项在存储的时候,是根据id进行k-v Map形式存储,而且存储也是分布式的,根据id hash计算处对应存储的key,然后知道对应存储的卡槽和卡槽所在的计算机节点(redis和kafka的类似思维的结合)。上述的词项属性中有一个词项的资源列表的概念,这里是一个倒序排列的出现该词项的所有的资源id的列表(int 列表),为了能很好检索出来词项对应的资源,对应的资源列表信息肯
首先需要大致知道搜索引擎有大致几类:1.全文搜索引擎 2.垂直搜索引擎 3.类目搜索引擎等。
1.全文搜索引擎:是全文本覆盖的,百度,google等都是全文本搜索,就是我搜一个词项“方圆”,那么这个词项可以是数字平方的概念,可以是一个人名,可以是一首歌等,所有的相关分类的概念都会被检索到。检索范围是全覆盖的,也就是中间涉及到语义的概念。
2.垂直检索引擎:就是检索一个词项,在一个语义范围内检索,检索范围在一个语义内的。
3.类目检索引擎:一般就是我们所见到互联网公司建设的搜索引擎,比如电商,一个词项检索就是检索自己所有的商品类目,或者汽车之家,就是检索所有的汽车类目。
建设搜索引擎,肯定在数据量上都是海量数据,而且要求数据检索返回速率很快,一般都是秒级返回(通常衡量检索引擎的指标有1.准确率 BM25/TF-IDF 2.召回率)。我们都知道一个数据库的表要是表中的数据几十亿条数据,我们select where 条件具有索引,时间也远不止一秒。所以检索引擎不是单单索引的建立那么简单。而且检索引擎的概念是select * like;是模糊匹配,不是固定匹配,所以检索更是范围巨大,远不是数据库索引检索那么简单。
搜索引擎在原理上很关键的几点,想到大家也会想到,1.数据结构的设计 2.索引结构的设计 3.数据存储方面的数据压缩机制(压缩之后检索更加高效)。首先我们先了解传统上数据的索引的数据结构B-Tree和B+tree.
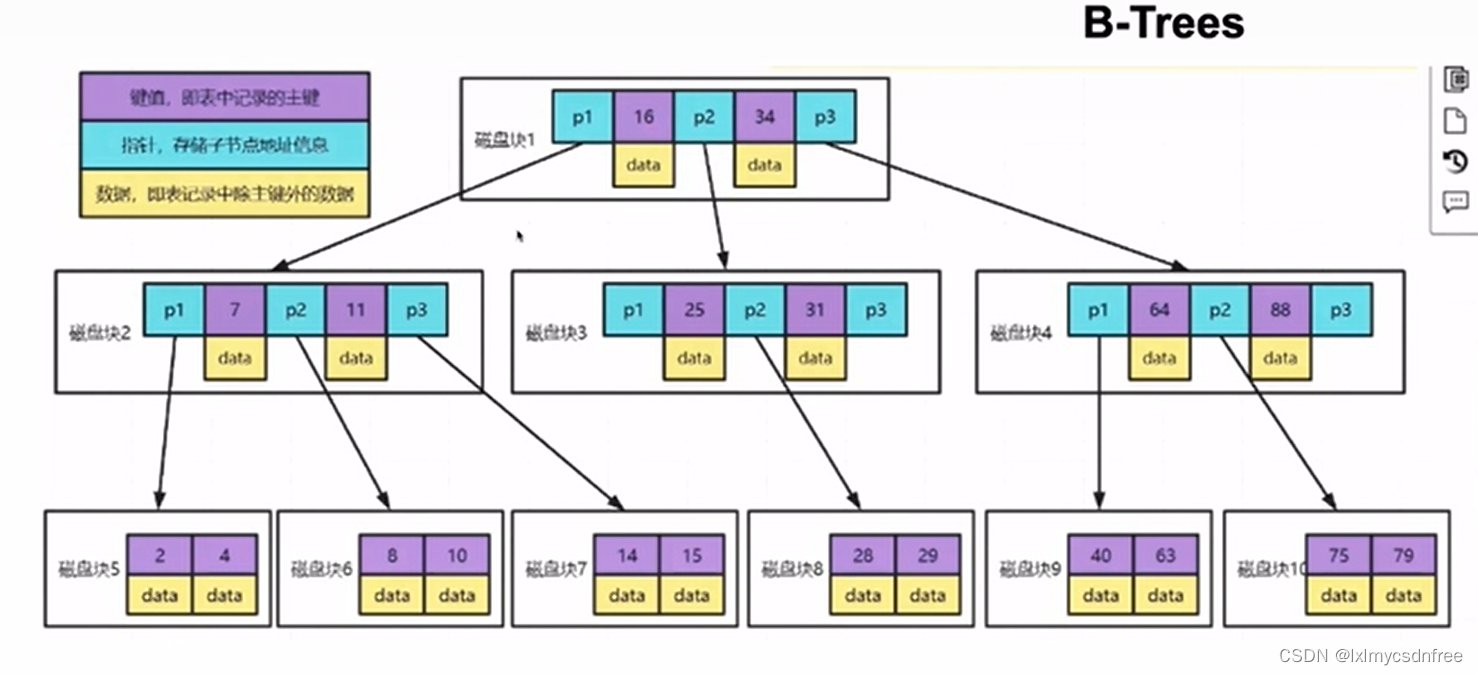
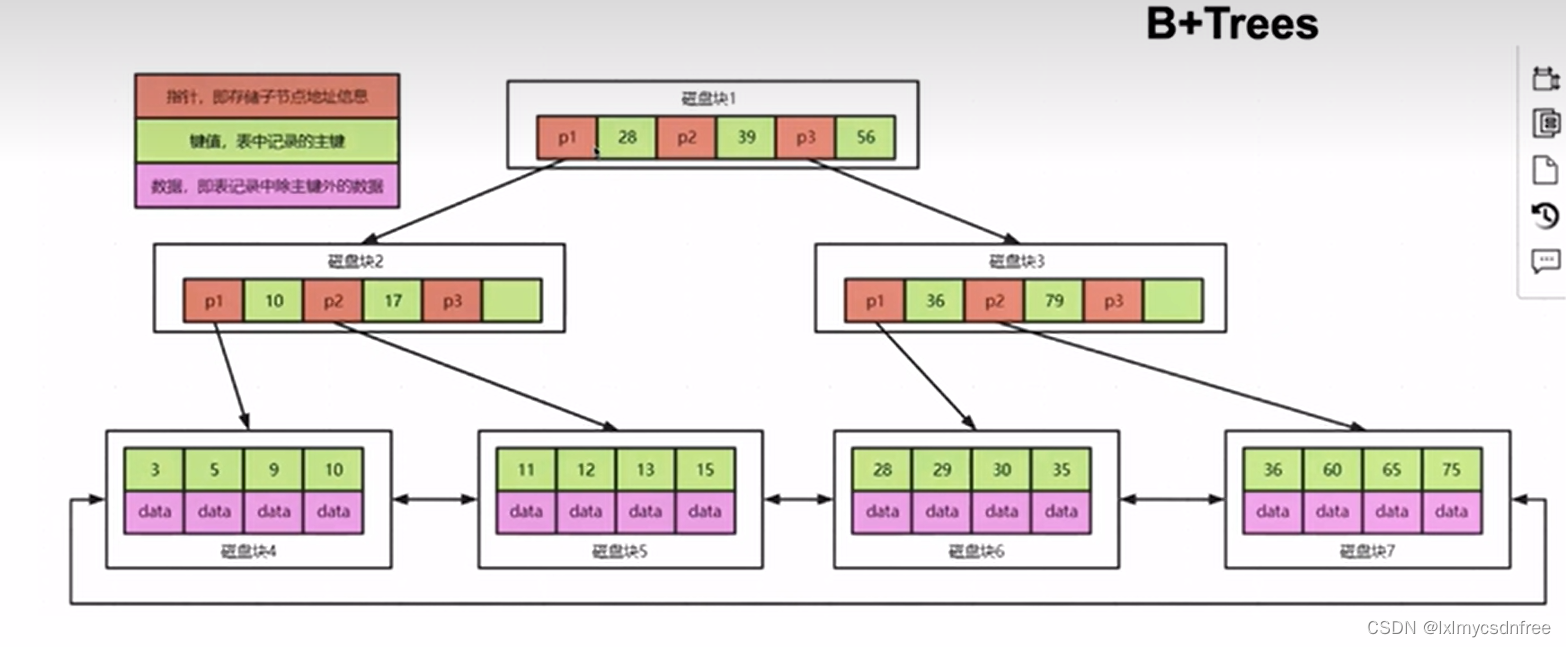
这是B树,但是需要普及一个知识点,不然大家不知道树存储到磁盘,在读取的时候涉及到的IO次数。我们磁盘最小的单元是一个扇区(512B),操作系统最小的读取单位是一簇4KB(8个扇区),那么我们在设置每一个树的节点也最小是4KB(在mysql中数据文件存储是16KB为一页,数据叶是最小存储单位)。那么B树每一个节点也要存储数据,如果数据部分很大,那么每一个节点上存储的分支个数就少了,那么树的深度自然要加大,那么在便利数据的时候,就需要遍历到一定深度的树才会检索到数据。每一次检索一个节点就是要读一个全新的数据叶,就是一次的IO磁盘读;那么这样检索上就需要很多次IO,效率很有限,因此引入了B+树:
B+树呢,每一个节点不存储数据,数据都存储在叶子节点上,而且叶子节点是一个双向的链表进行每一个叶子块链接。这样每一个节点数据块上可以存储的节点 分支就会多达几十,那么树的深度实现大幅度的缩小,遍历起来也非常快。
对于检索引擎,一方面我们肯定把所有的资源信息完整存储,然后根据资源提取所有的“词项”信息,然后搜索引擎会把所有的出现的词项进行存储,词项数据多达千亿级别,词项提出越多,搜索引擎检索准确率也就越高。
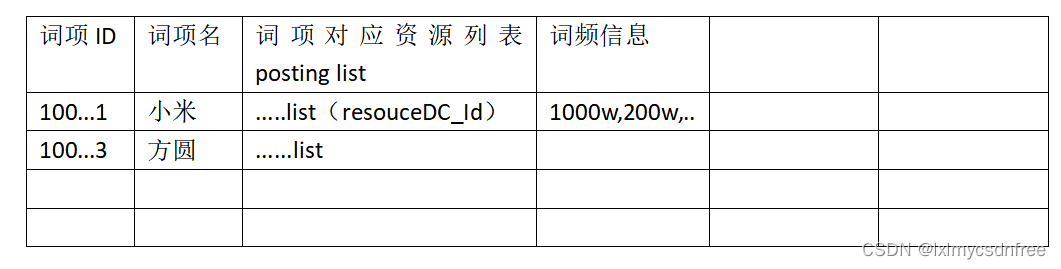
这是基本的词项存储列表,词项在存储的时候,是根据id进行k-v Map形式存储,而且存储也是分布式的,根据id hash计算处对应存储的key,然后知道对应存储的卡槽和卡槽所在的计算机节点(redis和kafka的类似思维的结合)。然后呢,搜索引擎还根据词项字典建立了对应的词项字典索引,加快map块的遍历。上述的词项属性中有一个词项的资源列表的概念,这里是一个倒序排列的出现该词项的所有的资源id的列表(int 列表),为了能很好检索出来词项对应的资源,对应的资源列表信息肯定需要存储的,这是必不可少的存储的数据单元。普通来说资源数据量在千亿级以上,那么出现该词项的条件假如有100万条,那么100万 int列表就是400万B=4MB.千亿级资源至少也有其百倍的词项,就是100*千亿=10w亿,那仅仅词项的倒排资源列表就是巨大的,甚至达到不可有效存储的概念。所以搜索引擎中的压缩算法是必不可少的,根据压缩后的逻辑遍历数据,从而使得检索更快。搜索引擎通常使用的压缩算法有FOR(Frame of Reference),Boaring BitMap算法,至少elasticSearch(lucence引擎)使用该压缩算法。
1.FOR(Frame of Reference)算法,很简单就是对数据列表取差值,存储初始值和所有的差值即可。比如 一列数据,10000,10001,10002,10003...... 1000101;取完差值(第一个值保留原值)列表就是10000,1,1,1,1,1......;我们使用几个bit存储所有的差值即可(这里差值是1),之前存储所有的数据是靠整型存储,现在依靠bit存储差值。实现很好的压缩,对于该类压缩还经常使用到文本信息压缩,尤其全英文的或者全中文文字压缩,因为存储的都是ASCII码,范围在一个区间内(比较紧凑),那记录差值很简单。FOR压缩很紧凑的数据效率很好。
2.Boaring BitMap算法(位图算法),对于非紧凑的数据序列使用FOR压缩就不行了,如1,30,200,400,750,900,1030,... 差值和原值没有大幅度缩小,所以使用BM算法。一个bit列 1000100001...每一个位就是一个bit,每一个位对应的位置号就是1,2,3,4,5,6....;那么在对应的位置上的bit要是1就代表有该序号的数值存在。.........00101010..... 假如这是一列数前面有10000bit位省略了,那么第一个位置代表一万零一,这一串bit代表就是存储了1万零三,1万零五,1万零七三个数据,所以可以见的一串bit的位置是记录的数据大小,所以存储的数据列一定是不可以重复的,不重复的数据这样记录存储可以极大的压缩,要是资源id在几万几十万区间内或者上亿区间内,那么这样就是1百bit存储一百个大小一亿以上的数据(大小:4B*100)数据,同时我们记录设置初始位置记为1亿(就是bit列第一位置就是1亿)100bit=12.5B存储了400B,实现了几百倍上千倍的压缩。
对于关键词(Term)字典结构的存储,采用复用的思想;就是关键词都是由多个字符组成的,(中文是双字节的字符)那么在整个字典结构保存的时候,采用保存一个个的字符,字符之间通过有向的索引来进行串联起来。这就是前缀树结构,Trie-树结构(如下图所示,数字标记的圆就是一个字符节点)。
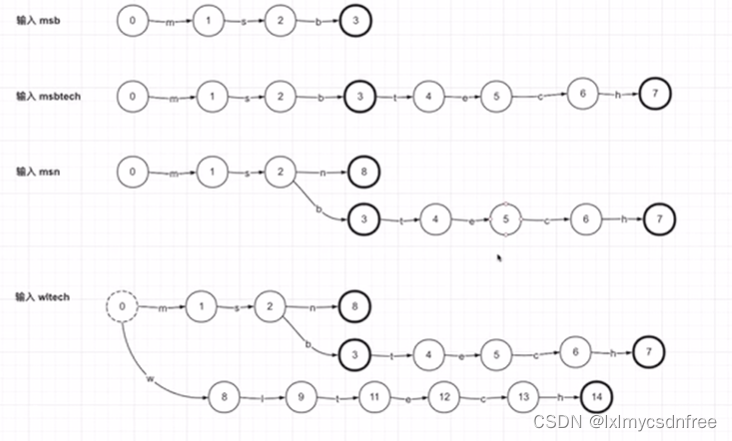
那为什么采用这个复用的思想呢?直接通过散列映射k-v,hashMap结构把所有的关键词都存储起来,遍历也十分迅速,为什么采用这种复用的结构呢?一般搜索服务里面包含几十亿上百亿的资源,然后后台的服务会将这些资源文件中的文本进行解析,提取其中的关键词(或者关键句),一般一个资源文件中包含的关键词有几十到几百,考虑到关键词的重复,那么所有资源包含的关键词 也有百亿甚至更大的数量级别。那么将这些关键词(关键句)存储起来将是非常大的空间,大致计算下,加入平均每一个关键词是8个字符,那么百亿关键词就是100GB的大小的字典结构(这还是很保守的估算)。如果通过字符共用+有向拼接的思想,实现这个结构千倍、万倍的压缩,那么直接可以将这个字典结构放在内存中,那么就不需要每次检索去IO文件,性能表现也完全不一样。
为了实现前缀复用树(字典)结构能根据有向链接输出想要查询的Term(关键词),需要标记具体节点的状态,例如是不是某一个要查询的Term最后一个字符,某一个节点有几个输出的子节点、子结点个数、是否是最后的子节点(子节点的个数记为某一个节点的出度,有些文章把输出子节点直接叫成出度,这纯属概念混淆)等。既然节点有状态,且通过有向链接,那么就是有限状态机的概念(Finit state Machine FSM)。如下图:
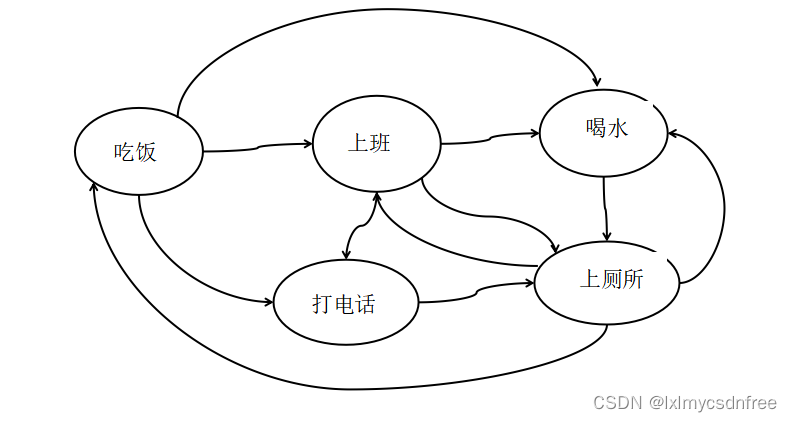
由此可见有限有序状态机其实是一个图结构,只是每一个节点有标记状态的数据。那么存储Term(关键词)字典结构肯定也是一个有向图结构,而且还是节点状态标记的图结构。只是每一次节点存储的是字符和节点状态等信息,而且Term存储结构还加入了起始点和终止节点,目的就是在遍历的时候单向有限,而且要求尽量去复用节点,这就是FSA(Finit state Accepter 有限状态接收器)的概念。如下图:
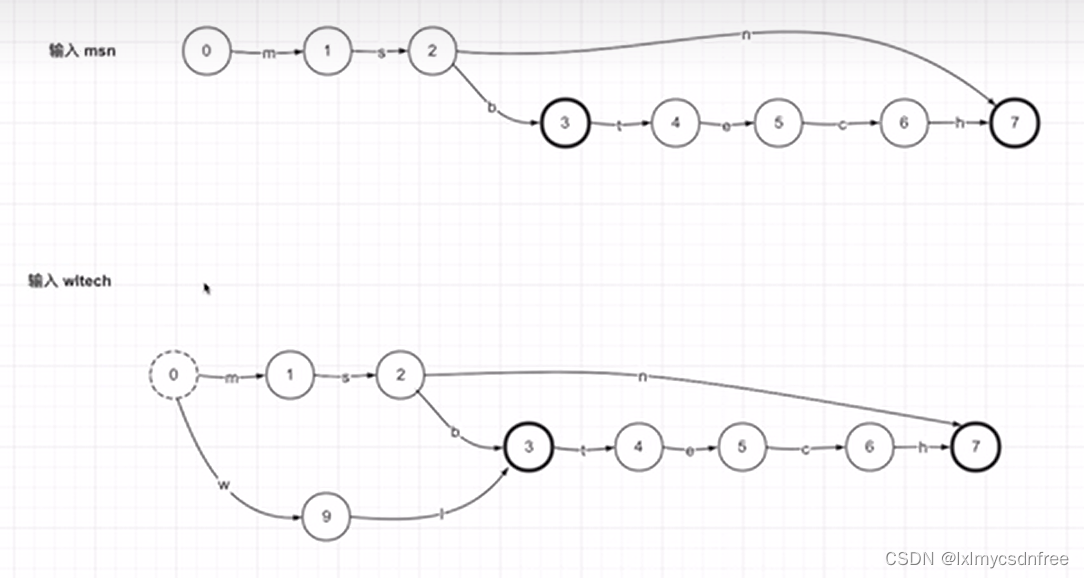
上图中0是起始节点,7是终止节点 ;而且在有向路线上尽量复用节点。那么如何实现复用呢?这是最为核心的算法,也是关键词存储和检索的核心算法。很多博客上或者视频讲解中只是提到FSA具备线路输出值(或者权重)特征,有点类似哈夫曼树(也叫霍夫曼),尽量使得所有线路的权重值求和结果最小,而且一般要求FSA中相同的始末节点线路输出值是一致的(heap和area中a->e的线路输出值一致)。那么在所有字典节点确认好了之后,来检查线路输出值,相同的要进行合并,这样就容易达到公用线路的算法。如下图:
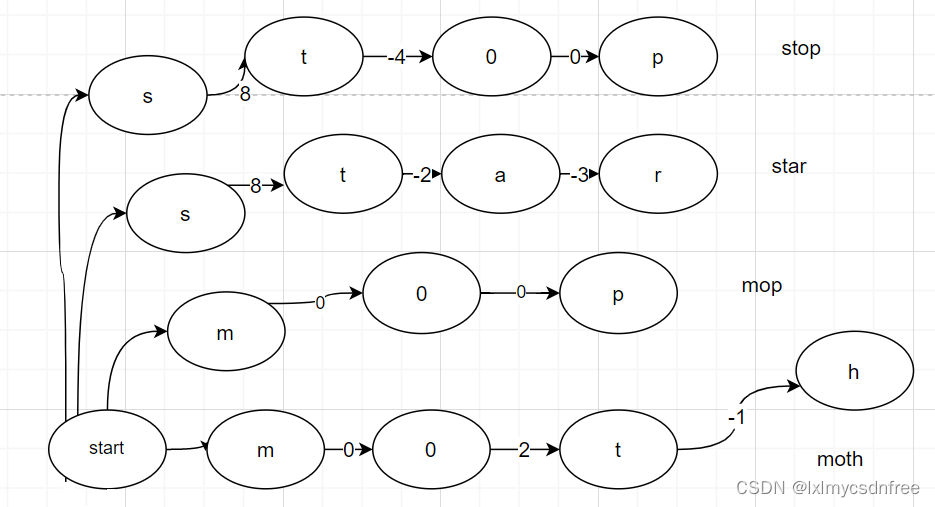
线路遍历之后,合并线路:
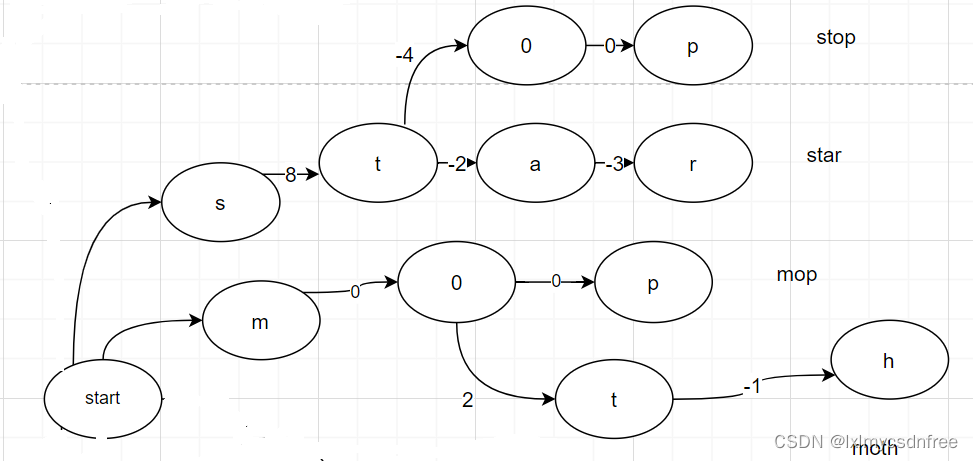
在FSA的建立之后,我们还需要对term存储的字典结构中存储每一个term的value,term字符串就是key,还需要像hashmap那样存储对应的value.所以我们又创造了每一个term结束字符节点的时候输出一个value,记为outputValue.这就是FST finit state transsioner.对于一系列的term,需要构造FST结构存储,事先就确定了每一个term的value,构建FST数据结构的一系列算法的集合 叫做FST构造器。构造器的构造过程如下:
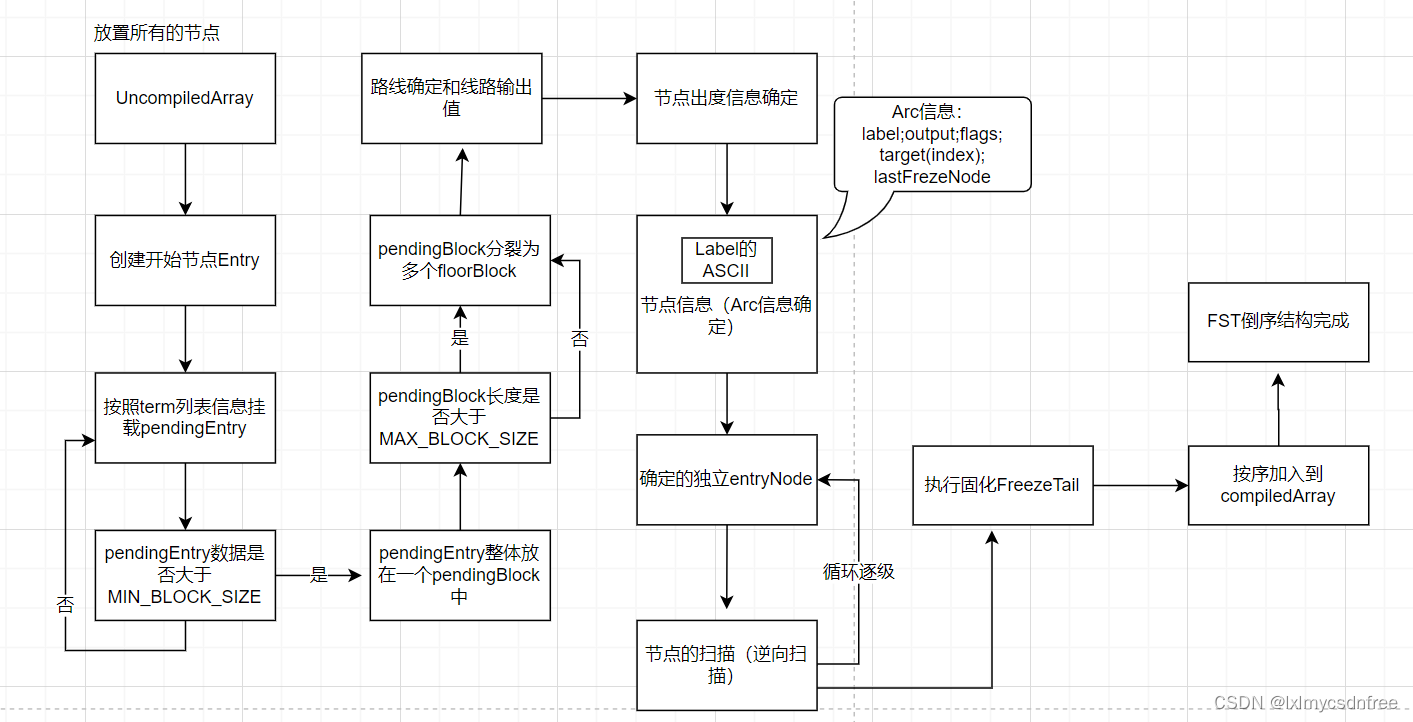
所有的关键词term字符节点都被放置在一个叫做frontier的列表里面,去构建FST的时候,首先创造uncomplied[] 存储即将构建的term的字符,然后创建一个初始节点entry,然后 依次从uncomplied[](也叫做current[])中获取每一个term的起始节点,然后按照每一个term将其他的节点依次挂进去,并记为pendingEntry。如果一个节点挂载的pendingEntry较多的时候,就会合并在一起形成pendingblock,并将该队列中最后一个entry的线路值作为pendingblock的线路值。如果形成的pendingblock持续增长,长度达到一个条件,就会转换成两个floorblock挂载在该block下面,形成层级结构,每一个floorblock的第一个entry节点的线路值作为floorblock的线路输出值。这样就形成了组织架构,这样也是为了方便将term的字典树结构搭建起来,然后所有的term节点挂载完成之后,然后根据term最后的节点来链接到终止节点,接着根据终止节点来倒着扫描末尾节点的状态和输出线路值。逐个的将floorblock和pendingblock中的entry逐个的确定和隔离开来,形成确定的节点参数信息和线路值。
Arc:描述FST构建的重要类型,其中我们要着重理解的包括label、output、target和flags四个属性,其他属性我这里都已经做了详细的中文注释,这里我们来把刚才说的四个属性重点讲解一下。
label:描述当前输入词项中的一个字符,FST最终存储的是label对应字符的ASCLL的二进制。
output:存储Arc对象的附加值或者叫做输出值,output和finalOutput都属于output。
target:如果当前的祖父不是输入值的最后一个字符,target会存储当前字符的下一个字符在current数组中的flag值在current数组中的index即索引值。
flags:通用最小化算法要求任何对数据的压缩都要可以逆向运算,即数据可编码解码,因此在对于FST进行压缩的时候,flags的作用是以最小的代价标记若干个状态值,这里采用了一种位移算法,以实现其通用最小化的目的。这里label和output都很容易理解,但是target和flags相对难以理解。target的含义我们在FST的写入过程中给大家做详细介绍,但是这flags的含义我们有必要在这里展开来详细的讲解一下。
lastFrozenNode:当节点从frontier[]数组中摘下来的时候,节点和它包含的Arcs信息会被写入到current[]数组中,lastFrozenNode会记录当前被处理的节点的第一个Arc在current数组中的起始坐标,即flag的坐标。如果当前节点是终止节点,因为终止节点没有出度Arc,因此lastFrozenNode会输出-1。当lastFrozenNode的值和当前处理的Arc指向的target node在current数组的起始坐标不相同并且当前处理的Arc的target node不是Stop node(因为没有出度Arc)的时候,也就意味着最终构建的FST对象存储的current[]数组在读取的时候,当前Arc对应的label在数组中的下一个Arc不是当前term的下一个label,就需要记录当前Arc的下一个Arc在current数组中的坐标,此时flag就不会标记BIT_TARGET_NEXT值。
把该末尾节点输出线路值记为一个合理的数值out1,该term对应的数值是value,往前所有的线路输出值总和为value-out1;如果out1值被之前扫描到的term线路已经赋值了,那么:1.如果out1<=value;则其向前线路和为value-out1; 2.如果out1>value;则令out1=value;记temp=out1-value;temp的数值可能需要被其他term向前的其他线路作为补偿值,且该term向前的线路暂不输出值(不输出值标记为0)。这样倒向逐个确定节点的线路输出值,然后最后相同的线路进行扫描合并,确定每一个节点的出度和状态参数信息,从而达到固化的目的。然后再倒序扫描固化的节点,执行freezeTail加固话的节点信息存储到compiled array数组中,依次从数组的最前面开始放置。这样放置完成之后,发现数组最后的位置存储的term字典树的开始位置节点信息,类似一个栈结构;这也是为什么叫做倒排索引的原因。
flags在FST结构读取的时候起着关键作用,flags是有几种有限的固定值的。

flags是这几种状态值的和,1,2,4,8,16,32者六种数值的几种组合,所以我们可以很轻松从flag的数值推断出来是哪几种状态值的累加。根据flag,我们在读取的时候很容易知道该节点在FST中的状态和位置。
按照网上给的一个例子,图中红框内是term和对应的value数值,也就是k-v列表信息:

然后图中左边部分是要计算每一个节点的flags,和右边确定的FST节点的拓扑结构信息,可以动手大家画一下,很容易就可以画出来的。下面是输出的最终FST数组结构:


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)