医药领域知识图谱快速及医药问答项目(项目全过程)
该项目是中科院软件所刘焕勇老师在github上的开源项目,基于知识图谱的医药领域问答项目Github项目地址:mirrors / liuhuanyong / qasystemonmedicalkg · GitCode一、项目环境搭建该部分要十分注意,由于版本升级的问题,一些用法及格式已经不兼容了。python3.8下载地址:Python Release Python 3.8.10 | Python
该项目是中科院软件所刘焕勇老师在github上的开源项目,基于知识图谱的医药领域问答项目
Github项目地址:mirrors / liuhuanyong / qasystemonmedicalkg · GitCode
一、项目环境搭建
该部分要十分注意,由于版本升级的问题,一些用法及格式已经不兼容了。
python3.8
下载地址:Python Release Python 3.8.10 | Python.org![]() https://www.python.org/downloads/release/python-3810/
https://www.python.org/downloads/release/python-3810/
Neo4j数据库安装 (我用的是4.2.2版本 JDK是15)
这个博主写得好,贴下链接:(3条消息) neo4j数据库安装 - CSDN![]() https://www.csdn.net/tags/NtzaQg5sNTk2My1ibG9n.html
https://www.csdn.net/tags/NtzaQg5sNTk2My1ibG9n.html
MongoDB安装 (我用的是4.0)
这个博主写得好,贴下链接:(3条消息) MongoDB安装详细教程(爬坑之路)_Just Do Its的博客-CSDN博客_mongodb安装![]() https://blog.csdn.net/liu991029/article/details/114709588 环境配置差不多了,如果项目运行失败,看看这些软件是否运行
https://blog.csdn.net/liu991029/article/details/114709588 环境配置差不多了,如果项目运行失败,看看这些软件是否运行
项目运行时以下三个cmd窗口不要关闭!!!
运行neo4j数据库
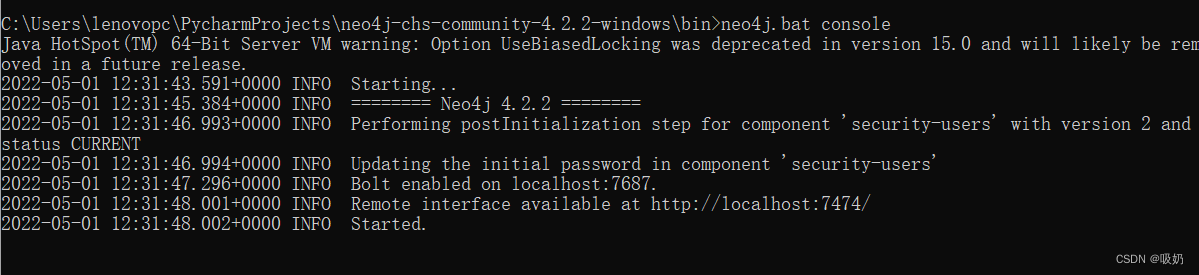
在浏览器中输入 localhost:7474
开启mongodb服务
开启mongodb客户端,27017是默认端口
如果还有环境以及版本、语法格式这种问题,就不要问我了。
二、数据获取
在该项目prepare_data目录下
该目录下的一些代码写法已经过时,报错了请自行百度。
1. ,运行data_spider.py(保证mongodb服务是开启的)
该程序末尾添加这三行以调用
handler = CrimeSpider()
handler.inspect_crawl()
handler.spider_main()运行结果:

2. 运行build_data.py
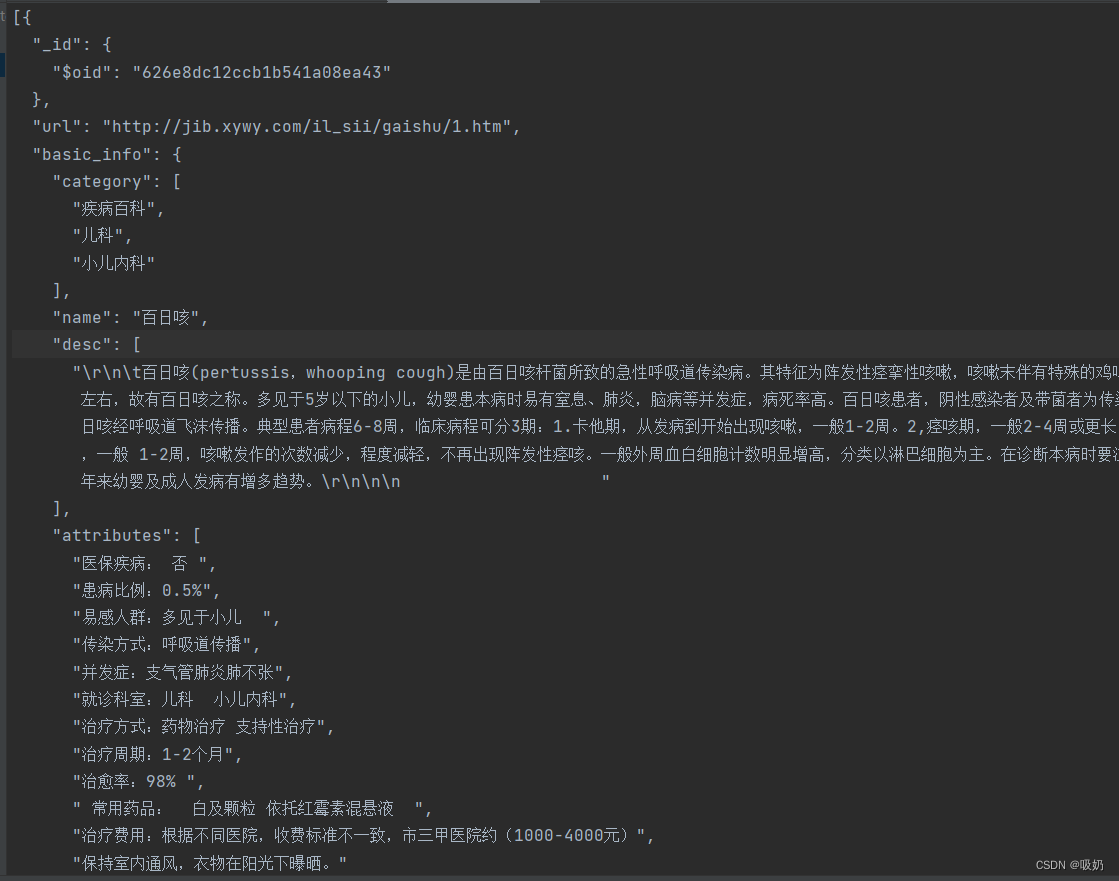
这里需要好好说说,在这个py文件里面,有一个神秘的first_name.txt,但是刘焕勇老师并没有在项目中给出。于是我在这里猜测它就是medical.json的前身,在刚刚运行data_spider.py之后,mongodb里面已经有东西了,所以我认为first_name.txt就是从data数据库中导出的文件。(这里需要格式转换,mongodb并不支持txt格式,需要另存为txt格式)
first_name.txt就是长这样:
函数调用
if __name__ == '__main__':
handler = MedicalGraph()
handler.modify_jc()
handler.collect_medical()运行build_data.py结束后,medical数据库中也有东西了,继续导出,
我们得到second_name.txt,这已经非常接近medical.json了
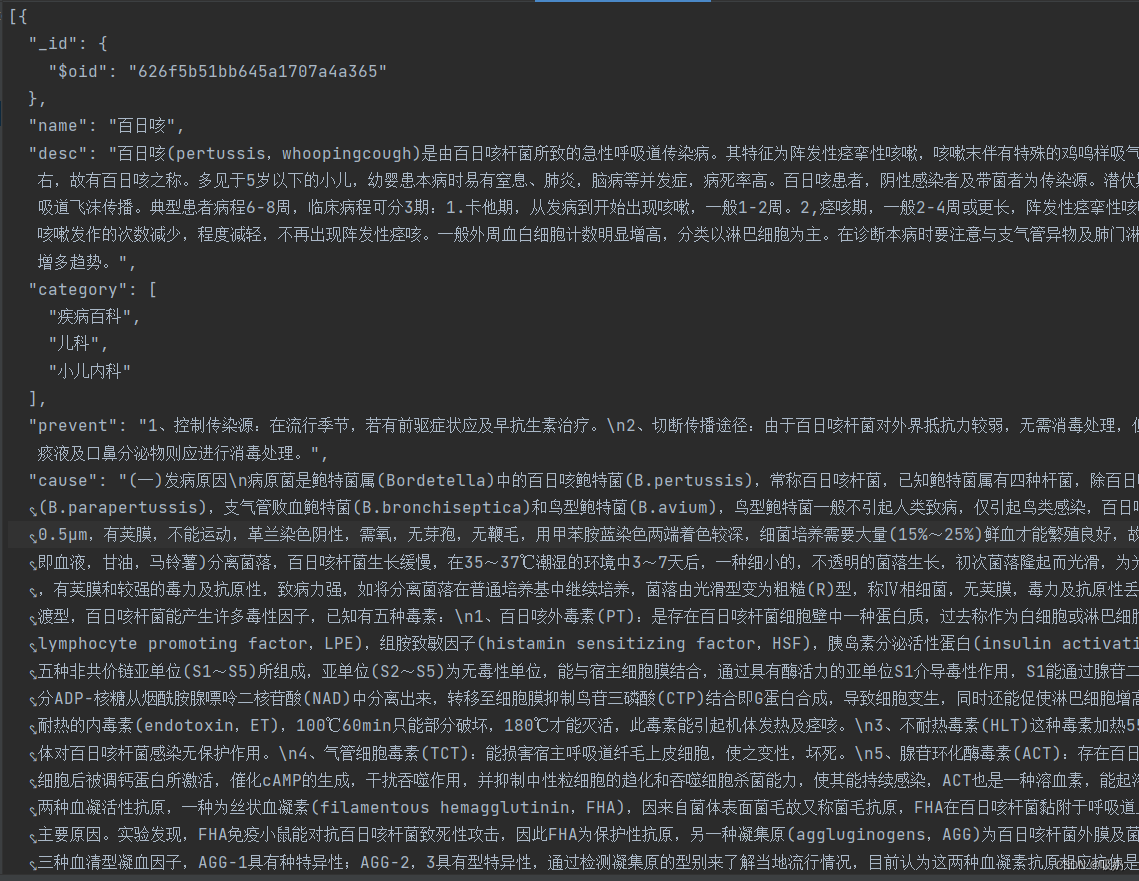
这里我也挖个坑(其实是我不会)
从second_name.txt到medical.json需要进一步操作,如果有哪位小伙伴知道怎么做,请在评论区告诉我。
三、搭建图数据库
1.运行build_medicalgraph.py , 这需要几个小时
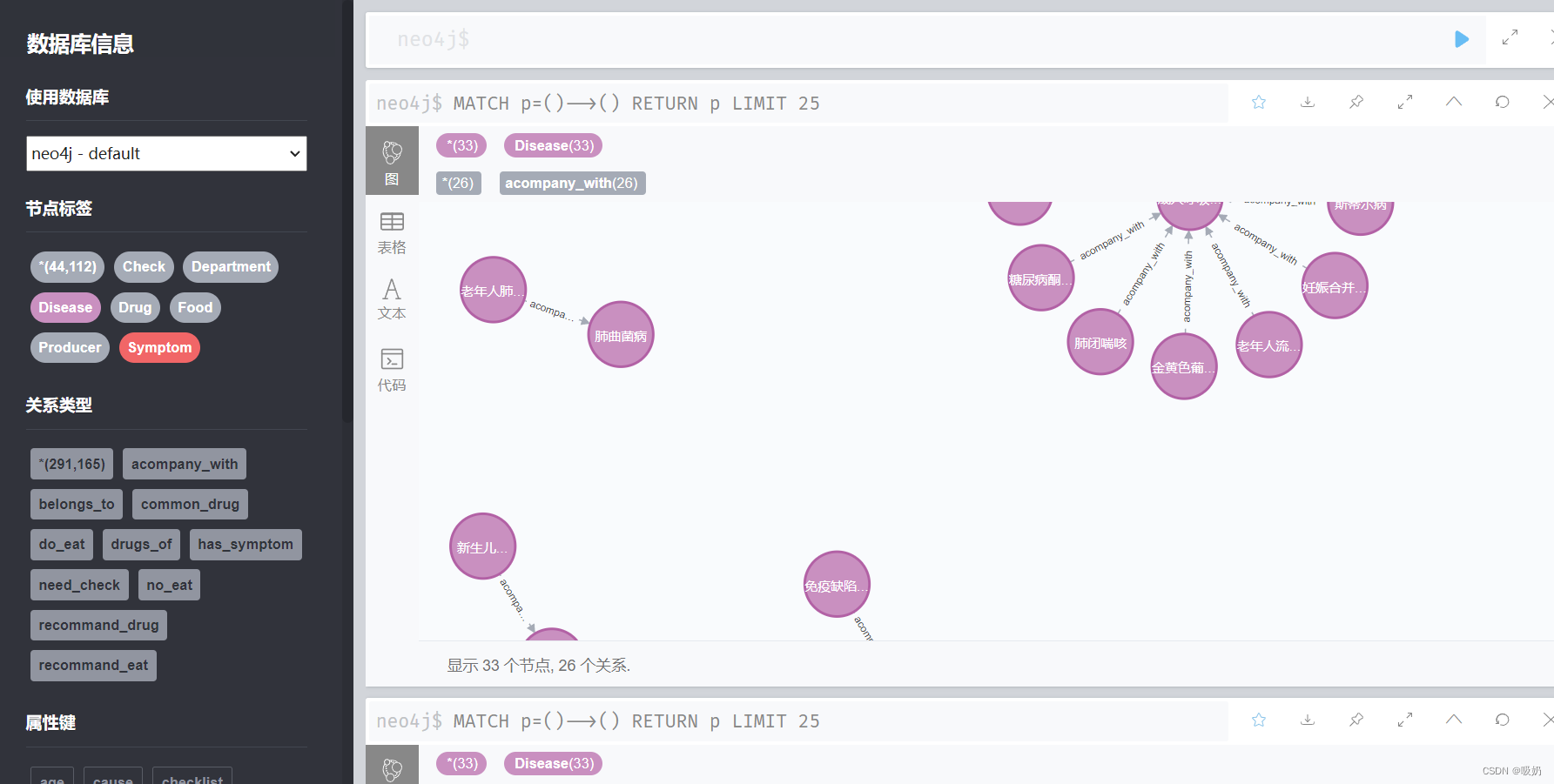
四、智能问答
1.question_classifier.py
该文件中有一段写法报错,已改正
# 加载特征词 这里encoding用的是‘utf-8’模式,不加的话,我的pycharm会报错
self.disease_wds = [i.strip() for i in open(self.disease_path, encoding='utf-8') if i.strip()]
self.department_wds = [i.strip() for i in open(self.department_path, encoding='utf-8') if i.strip()]
self.check_wds = [i.strip() for i in open(self.check_path, encoding='utf-8') if i.strip()]
self.drug_wds = [i.strip() for i in open(self.drug_path, encoding='utf-8') if i.strip()]
self.food_wds = [i.strip() for i in open(self.food_path, encoding='utf-8') if i.strip()]
self.producer_wds = [i.strip() for i in open(self.producer_path, encoding='utf-8') if i.strip()]
self.symptom_wds = [i.strip() for i in open(self.symptom_path, encoding='utf-8') if i.strip()]
self.region_words = set(
self.department_wds + self.disease_wds + self.check_wds + self.drug_wds + self.food_wds + self.producer_wds + self.symptom_wds)
self.deny_words = [i.strip() for i in open(self.deny_path, encoding='utf-8') if i.strip()]2.运行chatbot_graph.py
 3.编写UI
3.编写UI
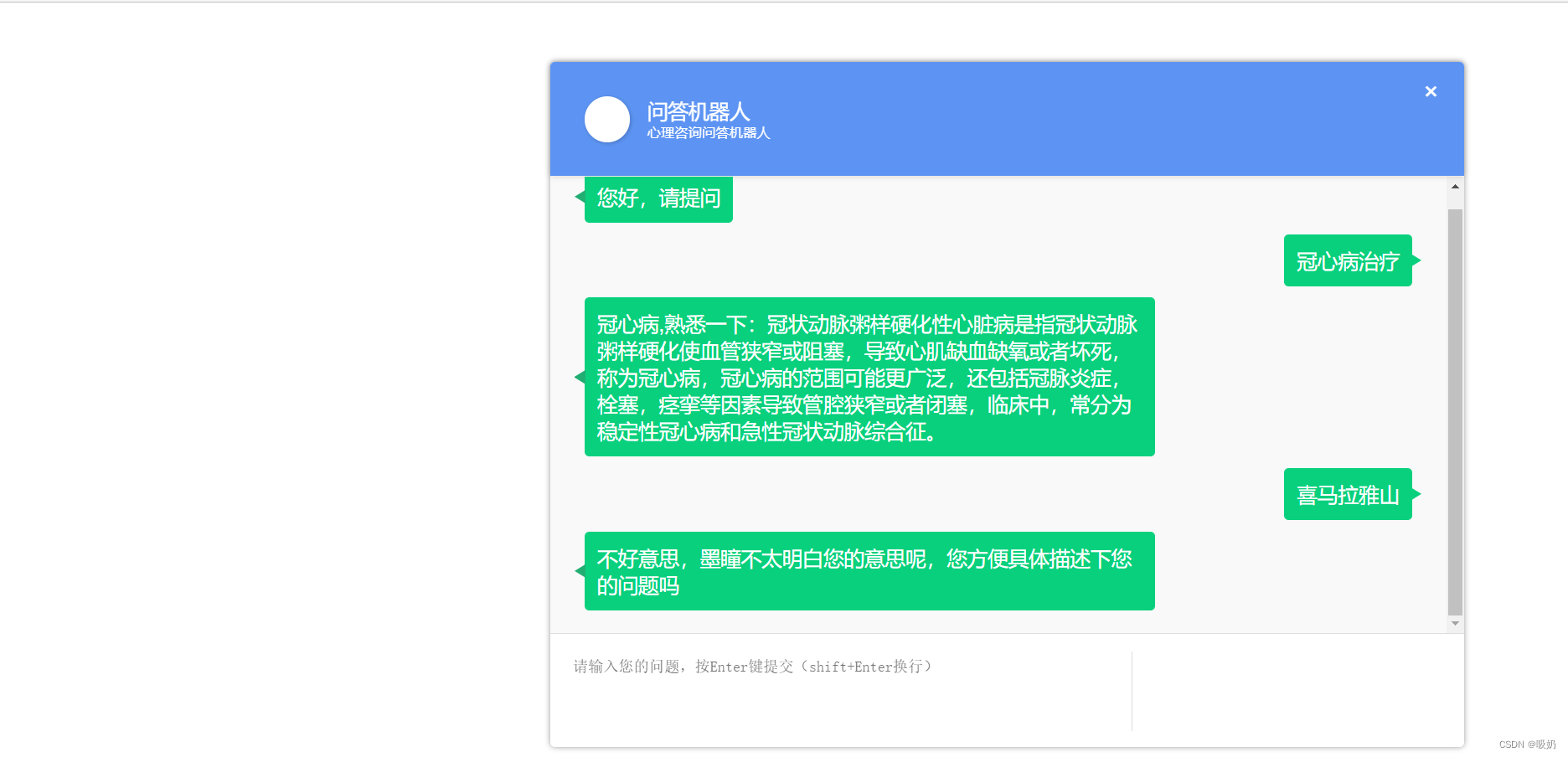
运行 api.py,然后直接进入home.html
效果展示:
结语
最后再次感谢医药领域知识图谱快速及医药问答项目和基于知识图谱的心理咨询智能问答系统这两个项目的创作者。如果有什么遗漏或者错误的话,欢迎在评论区指正。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)