Flink SQL JDBC你踩过的坑
Flink SQL JDBC你踩过的坑
测试环境
- Flink SQL 1.14
- Mysql 5.7
- pom依赖引入Flink-JDBC Connector 以及 Mysql Driver依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.14.4</version>
</dependency>
踩坑
Flink SQL Mysql DDL的使用方式如下:

Mysql既可以作为数据源表,也可以作为目标源表(注意事项:目前只有Bounded方式,不可作为流数据源),也可以作为维表。每种表模式下,都有自己的参数可自定义设置。
不同表模式的公共参数:

数据源表的参数:

维表参数:

目标源表参数:

sink.buffer-flush.max-rows 参数默认值是100,当数据写入Mysql之前,会对数据进行缓存,当达到这个阈值后变会进行flush操作。
sink.buffer-flush.interval 参数默认值为1s, 即每1s变会对buffer中的数据进行flush。
注意事项:如果你把sink.buffer-flush.interval 设置为0,不想使用定时Flush的操作,那么要记住还有sink.buffer-flush.max-rows 这个参数控制Flush。如果缓存的数据量没有达到阈值,是不会Flush到Mysql表,所以当你发现Mysql少数据时候,可以注意这里参数设置。
注意事项:接着上一步,如果你也把sink.buffer-flush.max-rows设置为0, 这个并不意味着不缓存数据,直接把数据下发。如果你想要来一条数据就直接下发,那么需要设置为1。
定时Flush的任务只有在sink.buffer-flush.max-rows 不等于1 并且sink.buffer-flush.interval 不等于0情况下才会初始化。
上面的设置已经把定时任务Flush的功能屏蔽掉了。

再看这里,缓存的数据条数只有大于sink.buffer-flush.max-rows值 时候才会下发,如果进来一条数据,那么batchCount = 1 这个条件是成立的,大于sink.buffer-flush.max-rows = 0 。但是却不满足第一个条件,因为我们误把sink.buffer-flush.max-rows 设置为0。

那么下面我们进行一个完整的测试程序,读Kafka并且做聚合操作然后写入Mysql。
Kafka数据源只有两条数据:

清空目标源Mysql表:

测试SQL: 按照name字段分组统计数据
CREATE TABLE kafkaTableSource (
name string,
age int,
sex string,
address string,
proc as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'hehuiyuan1',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.client.id' = 'test-consumer-group',
'properties.group.id' = 'test-consumer-group',
'format' = 'csv'
);
CREATE TABLE mysqlTable (
name string,
countp bigint
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/test',
'table-name' = 'studentscount',
'username' = 'root',
'password' = '123',
'driver' = 'com.mysql.jdbc.Driver',
'sink.buffer-flush.interval' = '0',
'sink.buffer-flush.max-rows' = '1'
);
INSERT INTO mysqlTable SELECT name, count(*) FROM kafkaTableSource GROUP BY name
报错:

注意事项:如果使用聚合操作时候,数据存在更新,需要在Mysql的DDL中声明Primary key才可以。
CREATE TABLE mysqlTable (
name string,
countp bigint,
PRIMARY KEY (name) NOT ENFORCED
) WITH (
修改完后继续运行程序,消费Kafka两条数据后,查询Mysql表中写入的数据情况:
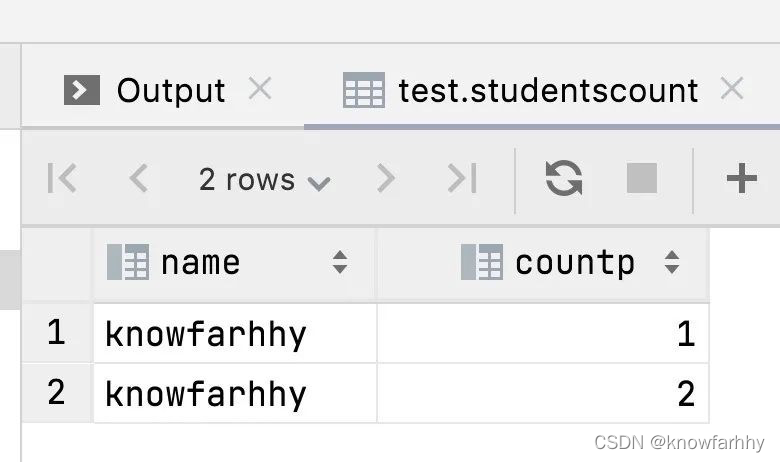
注意事项:在这里你会发现在Flink SQL Mysql的DDL中设置了Primary key,结果数据还是追加并没有执行更新操作,其实应该是一条数据而不是2条。
下面我们换一个目标源Mysql表:

我们再次执行上面的SQL程序:

这里我们发现是正确的了,其实这两个表唯一区别:
注意事项:不仅要在Flink SQL Mysql DDL中指定Primary key,还需要真实的Mysql表同样设置了主键才可以。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)