RabbitMQ常见问题与解决方案
原文: https://juejin.cn/post/7008456373931343908面试中MQ是常问的,我认为这并不属于八股文,而是对复杂业务场景下的总结和思考,还有对MQ机制的认知。1. RabbitMQ如何保证消息不丢失?1.1 (生产者需要做的) 生产者重写 RabbitTemplate.ConfirmCallback的 confirm方法以及 returnedMessage 方法。
原文: https://juejin.cn/post/7008456373931343908
面试中MQ是常问的,我认为这并不属于八股文,而是对复杂业务场景下的总结和思考,还有对MQ机制的认知。
1. RabbitMQ如何保证消息不丢失?
1.1 (生产者需要做的) 生产者重写 RabbitTemplate.ConfirmCallback的 confirm方法以及 returnedMessage 方法。
将 ack==false 的消息 持久化到数据库,定时扫描 DB 中投递失败的数据,重新投递到MQ中;
/**
* 生产者 确认消息的配置
* 此函数为回调函数,用于通知producer消息是否投递成功
*
* @param correlationData 消息唯一ID
* @param ack 确认消息是否被MQ 接收,true是已被接收,false反之
* @param cause
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
//投递成功
if (ack) {
//不做处理,等待消费成功
log.info(correlationData.getId() + ":发送成功");
//删除redis里面备份的数据
redisTemplate.delete(correlationData.getId());
} else {
//投递失败 //测试该逻辑时候 把上边的if(ack) 改成if(!ack)即可
//持久化到数据库 (TODO 注意: 有时候 (严格保证消息投递成功的场景下) 可能需要增加定时任务,
//TODO 定时扫描 redis或者DB (这里我们把投递失败的保存到了DB 所以定时任务扫描DB就可以了) 中投递失败的数据,重新投递到MQ中,这也是保证消息投递成功的一个手段)
//TODO (但是 : 如果是需要顺序消费的话,这种重新投递的策略就显得不那么合适了,我想的是某几个顺序消息拥有同一个会话ID 。。。具体的实现我将在后续研究一下,这里先不考虑顺序消费的场景)
log.error(correlationData.getId() + ":发送失败");
log.info("备份到DB的内容:" + redisTemplate.opsForValue().get(correlationData.getId()));
try {
SaveNackMessage strategy = SaveNackMessage.getStrategy(SaveNackMessage.NackTypeEnum.PRODUCER.getType());
HashMap<String, Object> map = new HashMap<>();
map.put("cause", StringUtils.isNoneBlank(cause) ? cause : StringUtils.EMPTY);
map.put("ack", ack ? 1 : 0);
map.put("correlationData", Objects.nonNull(correlationData) ? correlationData : StringUtils.EMPTY);
saveNackMessageThread.execute(strategy.template(map));
} catch (Exception e) {
//TODO 发布event事件 监听方发送钉钉消息提醒开发者
log.error("记录mq发送端错误日志失败", e);
}
}
}
另外除了实现confirm方法,还需要实现returnedMessage方法 即(投递消息后,交换机找不到具体的queue将会回调该方法 一般我们需要配置钉钉预警,告知开发者)

具体代码如下:
@Autowired
private ApplicationEventPublisher publisher;
/**
* 当投递消息后,交换机找不到具体的queue将会回调该方法 一般我们需要配置钉钉预警,告知开发者
*
* @param message
* @param replyCode
* @param replyText
* @param exchange
* @param routingKey
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
log.error("returnedMessage 消息主体 message : {}", message);
log.error("returnedMessage 描述:{}", replyText);
log.error("returnedMessage 消息使用的交换器 exchange : {}", exchange);
log.error("returnedMessage 消息使用的路由键 routing : {}", routingKey);
HashMap<String, Object> maps = Maps.newHashMap();
maps.put("message", message);
maps.put("replyCode", replyCode);
maps.put("replyText", replyText);
maps.put("exchange", exchange);
maps.put("routingKey", routingKey);
String returnedMessage = JSON.toJSONString(maps);
SendFailNoticeEvent noticeEvent = new SendFailNoticeEvent();
noticeEvent.setLevel(1);
noticeEvent.setErrorMsg(
System.lineSeparator() +
"producer投递消息失败;报错信息: " + returnedMessage);
noticeEvent.setTalkTypeEnum(DingTalkTypeEnum.BIZ_NOTICE);
//发送消息投递失败事件,监听器方将信息发送至钉钉机器人群里或者是某个具体的人。
publisher.publishEvent(noticeEvent);
}
1.2 (MQ需要做的) 开启持久化参数 durable=true
在创建队列时候,指定队列属性 durable=true 如下 :
/**
* 2. 创建队列
* <p>
* 队列的三个属性:
* <p>
* durable:是否持久化,默认是false,持久化队列:会被存储在磁盘上,当rabbitmq重启时仍然存在,暂存队列:当前连接有效
* <p>
* exclusive:是否设置为排他队列,默认是false,如果是true的话只能被首次声明他的的连接使用,而且当连接关闭后队列即被删除。此参考优先级高于durable
* <p>
* autoDelete:是否自动删除,当没有生产者或者消费者使用此队列,该队列会自动删除。
*
* @return
*/
@Bean
public Queue testQueue() {
Map<String, Object> args = new HashMap<>(2);
// x-dead-letter-exchange 这里声明当前队列绑定的死信交换机 (队列添加了这个参数之后会自动与该死信交换机绑定,并设置路由键,不需要开发者手动绑定)
args.put("x-dead-letter-exchange", TestMqConstant.TEST_DEAD_LETTER_EXCHANGE);
// x-dead-letter-routing-key 这里声明当前队列的死信路由key
args.put("x-dead-letter-routing-key", TestMqConstant.TEST_DEAD_LETTER_ROUTING_KEY);
//QueueBuilder不调用某方法的话,那么那个值就是false,调用了就是true
//这里的exclusive和autoDelete都设置为false
return QueueBuilder.durable(TestMqConstant.TEST_ZHILIAN_Q)
.withArguments(args)
.build();
}
看下RabbitMQ的控制界面: 一般我们使用时候也是开启这个配置的 不要问为什么 (问就是是男人必须durable)
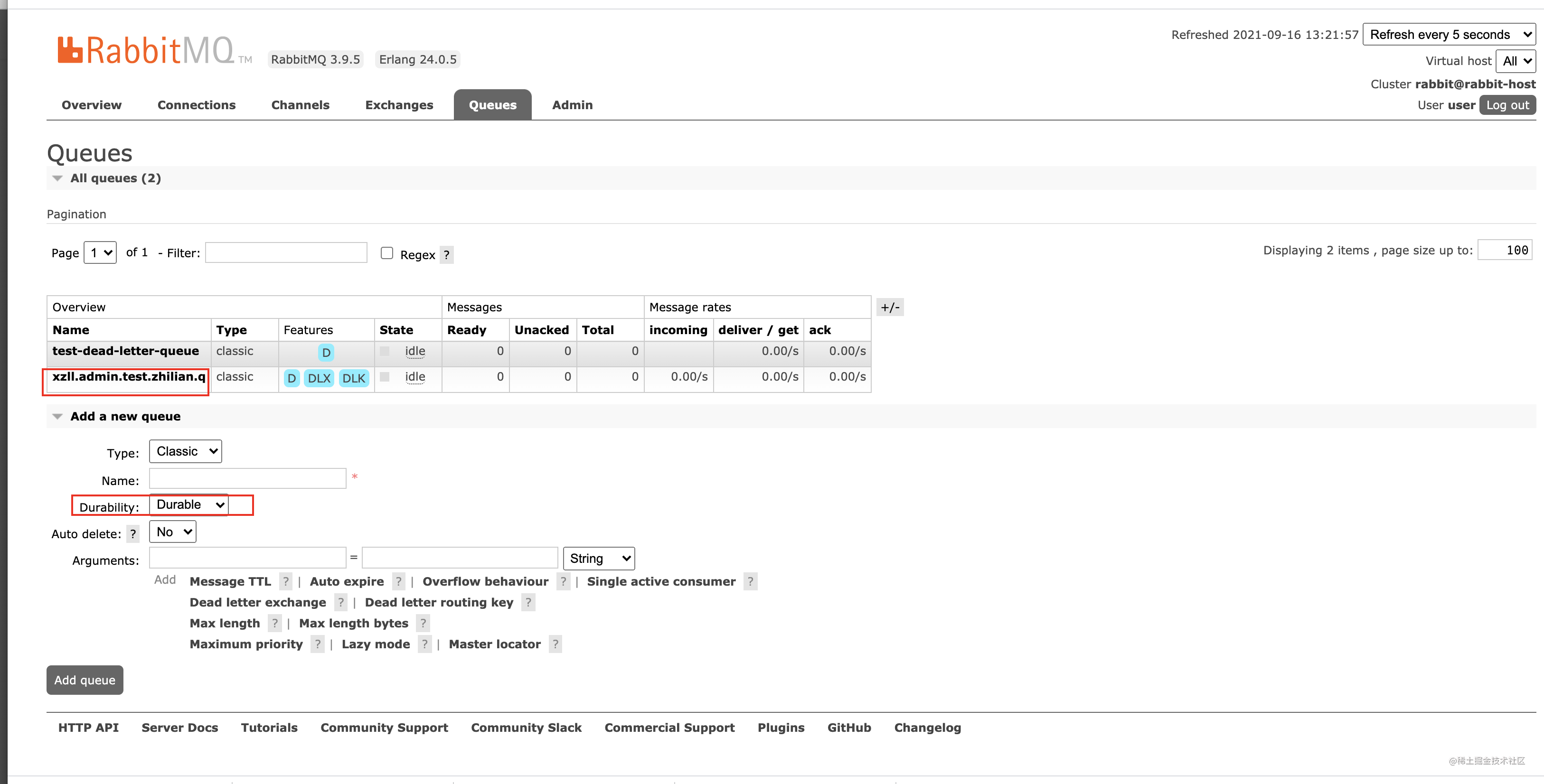
1.3 (消费者) 需要做的 手动ack,保证业务执行完后再ack,通知mq将某条消息删除
默认情况下 RabbitMQ 只要把消息推送到消费者就会认为消息已经被消费,就从队列中删除了(也就是自动ack),但是后边如果发生异常业务没执行,那不是GG了???,这样就相当于消息变相丢失了。
so 一般我们都是手动ack滴,
开启手动ack参数:
spring.rabbitmq.listener.simple.acknowledge-mode=manual
当开启这个参数时候,我们需要手动应答之后(也就是baseAck之后),RabbitMQ 才会从队列删除这条消息。
手动ack代码如下:
关于参数的一些解释推荐一篇文章: https://www.cnblogs.com/piaolingzxh/p/5448927.html
//第二个参数是 multiple:是否批量.true:将一次性ack所有小于deliveryTag的消息。false,只ack当前消息
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
ok 有了 1.1 1.2 1.3 的保障,基本也不会消息丢失了(注意我是说基本),但是没有人能够保障100%不丢失。实际中还得具体事情具体分析了。
2. RabbitMQ如何保证消息幂等?
注意: 幂等可是个很重要的一点。📢
2.1 生产端做消息幂等 (即不重复投递)
在生产端的话,其实消费端做好幂等,生产端就算投递多次,也无所谓了。
如果实在想在生产者做幂等的话,可以参考消费端的思路,比如通过redis的 setnx (key可以设计成producer:具体业务:具有唯一性的某几个或者某一个业务字段作为key) ,添加防重表等等。但是我个人觉得没必要。把消费端做好幂等就可以了。
2.2 消费端做消息幂等 (即不重复消费)
A方案: 使用redis的set命令: 此时redis的服务一定要保证高可用保证只有一个消息被消费,这种情况下,也保证了多实例(消费者)下,只有一个消费者能消费成功(我也是这么做的)
/**
* 是否能消费,用于防止重复消费
* <p>
* false 代表未消费过 ,true代表消费过
*
* @param content
* @param queueName
* @return
*/
private Boolean checkConsumedFlag(T content, String queueName) {
String messageKey = queueName + ":" + content.getId();
if (StringUtils.isBlank(redisTemplate.opsForValue().get(messageKey))) {
//从redis中没获取到value,说明未消费过该消息,返回true
return false;
} else {
//获取到了value说明消费过,然后将该消息标记为已消费并直接响应ack,不进行下边的业务处理,防止消费n次(保证幂等)
redisTemplate.opsForValue().set(messageKey, "lock", 60, TimeUnit.SECONDS);
//事实上,set操作应该放在业务执行完后,确保真正消费成功后执行。这里偷个懒。写在业务执行前了。
return true;
}
}
B方案(防重表): 并发高情况下可能会有IO瓶颈 (先读在写)该方式需要在发送消息时候,指定一个业务上唯一的字段。如 xzll:order:10001 (10001代表订单id)
然后,在消费端获取该字段,并插入到防重表中(插入代码写在哪?) 如果你声明了事务,那么插入防重这段代码位置无需关注(因为出现异常肯定会回滚),如果没实现事务,那么最好在执行完业务逻辑后,再插入防重表,保证防重表中的数据肯定是消费成功的。
实现步骤:
接收到消息后,select count(0) from 防重表 where biz_unique_id=message.getBizUniqueId();
如果大于0,那么说明以及消费过,将直接ack,告知mq删除该消息。如果=0说明没消费过。进行正常的业务逻辑
C方案(唯一键 : 真正保证了幂等): 直接写)如果消费端业务是新增操作,我们可以为某几个或者某一个字段设置业务上的唯一键约束,如果重复消费将会插入两条相同的记录,数据库会报错从而可以保证数据不会插入两条。
D方案(乐观锁):并发高下也可能会产生IO瓶颈 (先读再写)如果消费端业务是更新操作(例如扣减库存),可以给业务表加一个 version 字段,每次更新把 version 作为条件,更新之后 version + 1。由于 MySQL 的 innoDB 是行锁,当其中一个请求成功更新之后,另一个请求才能进来(注意此时该请求拿到的version还是1),由于版本号 version 已经变成 2,所以更新操作不会执行,从而保证幂等。
3. RabbitMQ出现消息堆积时候怎么办?
常见的几种
3.1: 是不是nack (回归队列) 次数过多?
3.2: 消费端是不是消费时间(业务执行时间)过长?此时我们可以看下哪些代码可以做异步处理,或者多线程执行。
3.3: 是否可以考虑批量消费消息? 在springboot中批量消息我们需要注入 BatchingRabbitTemplate(目前我没用到哈,对其机制不是很了解)
3.4: 总之我觉得主要还是在消费方找问题的突破口吧。
4. RabbitMQ重试策略如何配置?
默认情况下,RabbitTemplate会重试15次,知道超过该值,将抛出异常;
现在我们开启自动重试开关:
postman调用接口age传入0
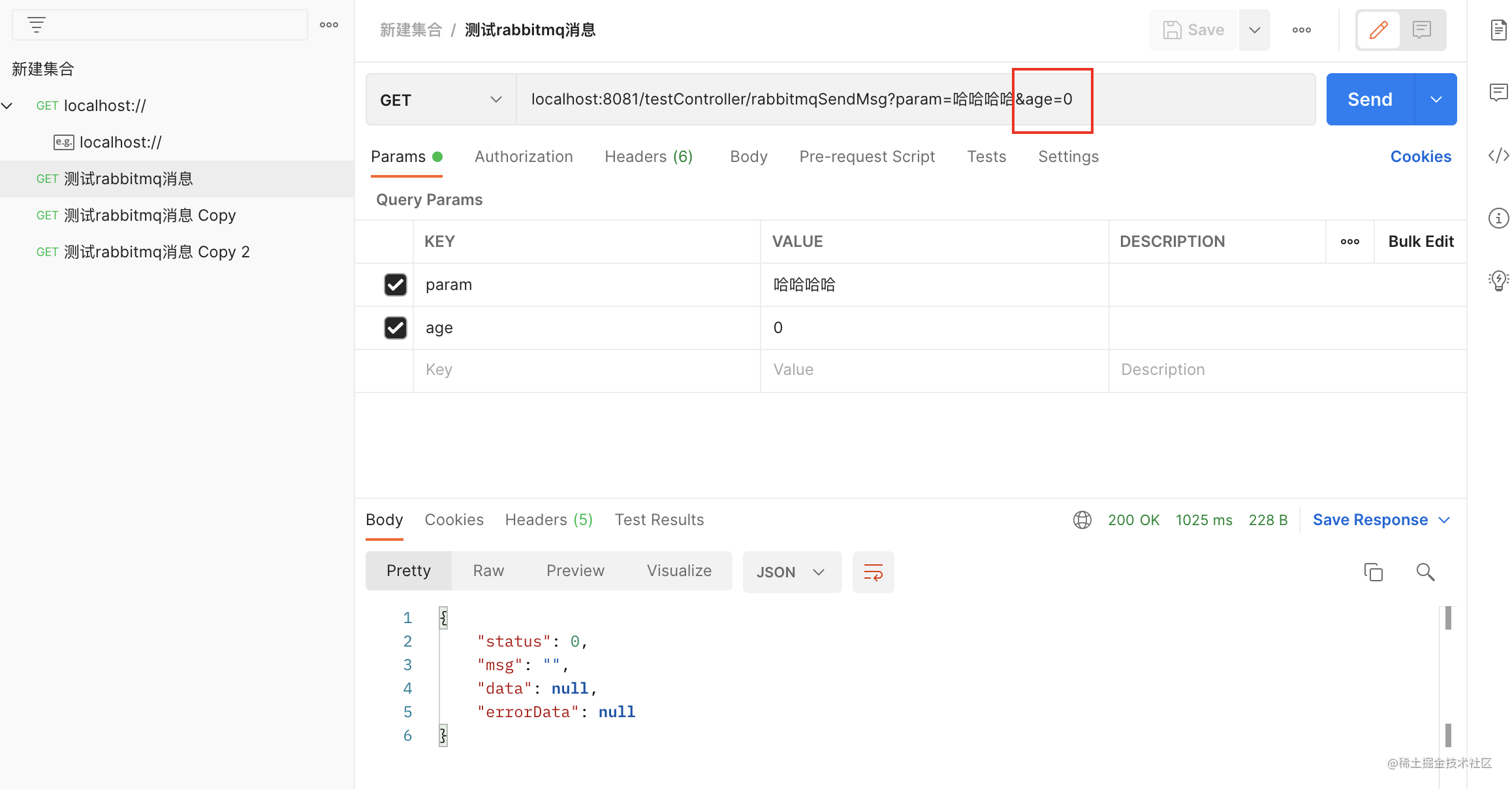
看下结果:

一般情况下我们需要手动nack(也就是回归队列) 从而达到重试消费的效果
第一步receiveMessage接收消息
/**
* 处理接收到的消息, 模板方法 子类一般无需扩展 , 调用方式: super.receiveMessage(message,channel);
*
* @param message
* @param channel
* @throws IOException
*/
protected void receiveMessage(Message message, Channel channel) throws Exception {
/**
* 做数据幂等校验,可以根据传过来的唯一ID先判断缓存 or 数据库中是否有数据(这里使用redis)
* 1、有数据则不消费,直接响应ack
* 2、缓存没有数据,则进行消费处理数据,处理完后手动ack
* 3、如果消息处理异常则,可以存入数据库中(或者存入死信队列),(另外可以增加短信、邮件提醒,钉钉消息等功能)
*/
try {
T content = getContent(message);
//已经消费,直接返回
if (checkConsumedFlag(content, message.getMessageProperties().getConsumerQueue())) {
logger.info(message.getMessageProperties().getConsumerQueue() + "已经消费过");
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} else {
//未消费过的话,消费当前消息
successExecuteHook(content);
logger.info(message.getMessageProperties().getConsumerQueue() + "消费成功");
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
//消费成功后删除重试标志
String redisCountKey = "retry:" + message.getMessageProperties().getConsumerQueue() + content.getId();
redisTemplate.delete(redisCountKey);
}
} catch (Exception e) {
//在catch中手动处理异常,当有异常且不手动处理的话,rabbitmq将会重试,重试参数配置见本类的最下边。
e.printStackTrace();
try {
if (retryConsumer(message, channel)) {
logger.info("回归队列成功:" + message);
} else {
logger.error("回归队列失败:" + message);
//进行持久化 异步 使用线程池提交 Runnable
saveNackMessageThread.execute(SaveNackMessage.getStrategy(SaveNackMessage.NackTypeEnum.CONSUMER.getType()).template(message));
failExecuteHook(getContent(message));
}
} catch (Exception e1) {
//扔掉数据 , 如果配置了死信交换机和队列 那么该消息将会进入死信队列 如果没有,那么MQ将会删除掉该消息
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, false);
logger.error("重试消费失败:" + message);
failExecuteHook(getContent(message));
}
}
}
第二步retryConsumer 回归队列:使用channel.basicNack(deliveryTag, false, true); 最后这个true代表回归到队列中,如果false的话,mq将会直接丢弃该消息
/**
* 重试消费 (也就是回归队列 这里设置4次)
*
* @param message
* @param channel
* @return
* @throws IOException
* @throws InterruptedException
*/
private Boolean retryConsumer(Message message, Channel channel) throws IOException, InterruptedException {
T content = getContent(message);
//单个消息控制
String redisCountKey = "retry:" + message.getMessageProperties().getConsumerQueue() + content.getId();
String retryCountValue = redisTemplate.opsForValue().get(redisCountKey);
long deliveryTag = message.getMessageProperties().getDeliveryTag();
//若该条消息没有重试消费过
if (StringUtils.isBlank(retryCountValue)) {
//第一次重试时候 设置重试次数
redisTemplate.opsForValue().setIfAbsent(redisCountKey, "1", 5, TimeUnit.MINUTES);
/*
basicNack参数解释:
deliveryTag:该消息的index
multiple:是否批量nack , true:将拒绝确认所有小于deliveryTag的消息。
requeue:被拒绝的是否重新入队列,false的话是直接丢弃,true是回归到队列中。
*/
logger.info(" {} 开始第一次回归到队列:", deliveryTag);
channel.basicNack(deliveryTag, false, true);
return true;
} else {
switch (Integer.valueOf(retryCountValue)) {
case 1:
redisTemplate.opsForValue().set(redisCountKey, "2");
logger.info(" {} 开始第二次回归到队列:", deliveryTag);
channel.basicNack(deliveryTag, false, true);
return true;
case 2:
redisTemplate.opsForValue().set(redisCountKey, "3");
logger.info(" {} 开始第三次回归到队列:", deliveryTag);
channel.basicNack(deliveryTag, false, true);
return true;
case 3:
redisTemplate.opsForValue().set(redisCountKey, "4");
logger.info(" {} 开始第四次回归到队列:", deliveryTag);
channel.basicNack(deliveryTag, false, true);
return true;
default:
//扔掉消息,放入死信队列或者存入数据库
redisTemplate.delete(redisCountKey);
//b1=false的话,代表丢弃消息(如果配置了死信队列的话,该消息不会被丢弃 而是进入死信队列中)
channel.basicNack(deliveryTag, false, false);
logger.info(" {} 不回归队列,进行持久化处理或者放入死信队列中:", deliveryTag);
return false;
}
}
//实际上最好在这里进行Nack 但是为了看起来清晰些 我把Nack写到上边每一个需要响应Nack的地方了。
}
在retryConsumer中,我们将会重试4次(可以根据实际场景设置重试次数),重试4次还是没消费成功的话,那么我们将消息发送到死信队列(前提是你在创建某个queue时候绑定了死信交换机,死信queue,死信routingKey),或者,我们可以使用线程池异步刷到DB中。根据业务需要,进行具体的处理。
ok以上就是重试的设置。注意一定要设置重试次数,否则如果每次消费失败都无脑nack的话,你可以想想一下,消费失败,nack回归队列,又消费失败,又nack回归队列,又消费失败,nack回归队列。。。。。。。死循环呵呵。
5. 最后贴出RabbitMQ的配置解释:
*************************** 关于rabbitmq的配置参数详解 重要 ***************************
基础信息
spring.rabbitmq.host: 默认localhost
spring.rabbitmq.port: 默认5672
spring.rabbitmq.username: 用户名
spring.rabbitmq.password: 密码
spring.rabbitmq.virtual-host: 连接到代理时用的虚拟主机
spring.rabbitmq.addresses: 连接到server的地址列表(以逗号分隔),先addresses后host
spring.rabbitmq.requested-heartbeat: 请求心跳超时时间,0为不指定,如果不指定时间单位默认为妙
spring.rabbitmq.publisher-confirms: 是否启用【发布确认】,默认false
spring.rabbitmq.publisher-returns: 是否启用【发布返回】,默认false
spring.rabbitmq.connection-timeout: 连接超时时间,单位毫秒,0表示永不超时
SSL
spring.rabbitmq.ssl.enabled: 是否支持ssl,默认false
spring.rabbitmq.ssl.key-store: 持有SSL certificate的key store的路径
spring.rabbitmq.ssl.key-store-password: 访问key store的密码
spring.rabbitmq.ssl.trust-store: 持有SSL certificates的Trust store
spring.rabbitmq.ssl.trust-store-password: 访问trust store的密码
spring.rabbitmq.ssl.trust-store-type=JKS:Trust store 类型.
spring.rabbitmq.ssl.algorithm: ssl使用的算法,默认由rabiitClient配置
spring.rabbitmq.ssl.validate-server-certificate=true:是否启用服务端证书验证
spring.rabbitmq.ssl.verify-hostname=true 是否启用主机验证
缓存cache
spring.rabbitmq.cache.channel.size: 缓存中保持的channel数量
spring.rabbitmq.cache.channel.checkout-timeout: 当缓存数量被设置时,从缓存中获取一个channel的超时时间,单位毫秒;如果为0,则总是创建一个新channel
spring.rabbitmq.cache.connection.size: 缓存的channel数,只有是CONNECTION模式时生效
spring.rabbitmq.cache.connection.mode=channel: 连接工厂缓存模式:channel 和 connection
Listener
spring.rabbitmq.listener.type=simple: 容器类型.simple或direct
spring.rabbitmq.listener.simple.auto-startup=true: 是否启动时自动启动容器
spring.rabbitmq.listener.simple.acknowledge-mode: 表示消息确认方式,其有三种配置方式,分别是none、manual和auto;默认auto
spring.rabbitmq.listener.simple.concurrency: 最小的消费者数量
spring.rabbitmq.listener.simple.max-concurrency: 最大的消费者数量
spring.rabbitmq.listener.simple.prefetch: 一个消费者最多可处理的nack消息数量,如果有事务的话,必须大于等于transaction数量.
spring.rabbitmq.listener.simple.transaction-size: 当ack模式为auto时,一个事务(ack间)处理的消息数量,最好是小于等于prefetch的数量.若大于prefetch, 则prefetch将增加到这个值
spring.rabbitmq.listener.simple.default-requeue-rejected: 决定被拒绝的消息是否重新入队;默认是true(与参数acknowledge-mode有关系)
spring.rabbitmq.listener.simple.missing-queues-fatal=true 若容器声明的队列在代理上不可用,是否失败; 或者运行时一个多多个队列被删除,是否停止容器
spring.rabbitmq.listener.simple.idle-event-interval: 发布空闲容器的时间间隔,单位毫秒
spring.rabbitmq.listener.simple.retry.enabled=false: 是否开启重试
spring.rabbitmq.listener.simple.retry.max-attempts=3: 最大重试次数
spring.rabbitmq.listener.simple.retry.max-interval=10000ms: 最大重试时间间隔
spring.rabbitmq.listener.simple.retry.initial-interval=1000ms:第一次和第二次尝试传递消息的时间间隔
spring.rabbitmq.listener.simple.retry.multiplier=1: 应用于上一重试间隔的乘数
spring.rabbitmq.listener.simple.retry.stateless=true: 重试时有状态or无状态
spring.rabbitmq.listener.direct.acknowledge-mode= ack模式
spring.rabbitmq.listener.direct.auto-startup=true 是否在启动时自动启动容器
spring.rabbitmq.listener.direct.consumers-per-queue= 每个队列消费者数量.
spring.rabbitmq.listener.direct.default-requeue-rejected= 默认是否将拒绝传送的消息重新入队.
spring.rabbitmq.listener.direct.idle-event-interval= 空闲容器事件发布时间间隔.
spring.rabbitmq.listener.direct.missing-queues-fatal=false若容器声明的队列在代理上不可用,是否失败.
spring.rabbitmq.listener.direct.prefetch= 每个消费者可最大处理的nack消息数量.
spring.rabbitmq.listener.direct.retry.enabled=false 是否启用发布重试机制.
spring.rabbitmq.listener.direct.retry.initial-interval=1000ms # Duration between the first and second attempt to deliver a message.
spring.rabbitmq.listener.direct.retry.max-attempts=3 # Maximum number of attempts to deliver a message.
spring.rabbitmq.listener.direct.retry.max-interval=10000ms # Maximum duration between attempts.
spring.rabbitmq.listener.direct.retry.multiplier=1 # Multiplier to apply to the previous retry interval.
spring.rabbitmq.listener.direct.retry.stateless=true # Whether retries are stateless or stateful.
Template
spring.rabbitmq.template.mandatory: 启用强制信息;默认false
spring.rabbitmq.template.receive-timeout: receive() 操作的超时时间
spring.rabbitmq.template.reply-timeout: sendAndReceive() 操作的超时时间
spring.rabbitmq.template.retry.enabled=false: 发送重试是否可用
spring.rabbitmq.template.retry.max-attempts=3: 最大重试次数
spring.rabbitmq.template.retry.initial-interva=1000msl: 第一次和第二次尝试发布或传递消息之间的间隔
spring.rabbitmq.template.retry.multiplier=1: 应用于上一重试间隔的乘数
spring.rabbitmq.template.retry.max-interval=10000: 最大重试时间间隔
我的项目中RabbitMQ配置情况
# rabbitmq配置
spring.rabbitmq.host=127.0.0.1
spring.rabbitmq.port=5672
spring.rabbitmq.username=user
spring.rabbitmq.password=password
spring.rabbitmq.virtual-host=/
spring.rabbitmq.publisher-confirms=true
spring.rabbitmq.publisher-returns=true
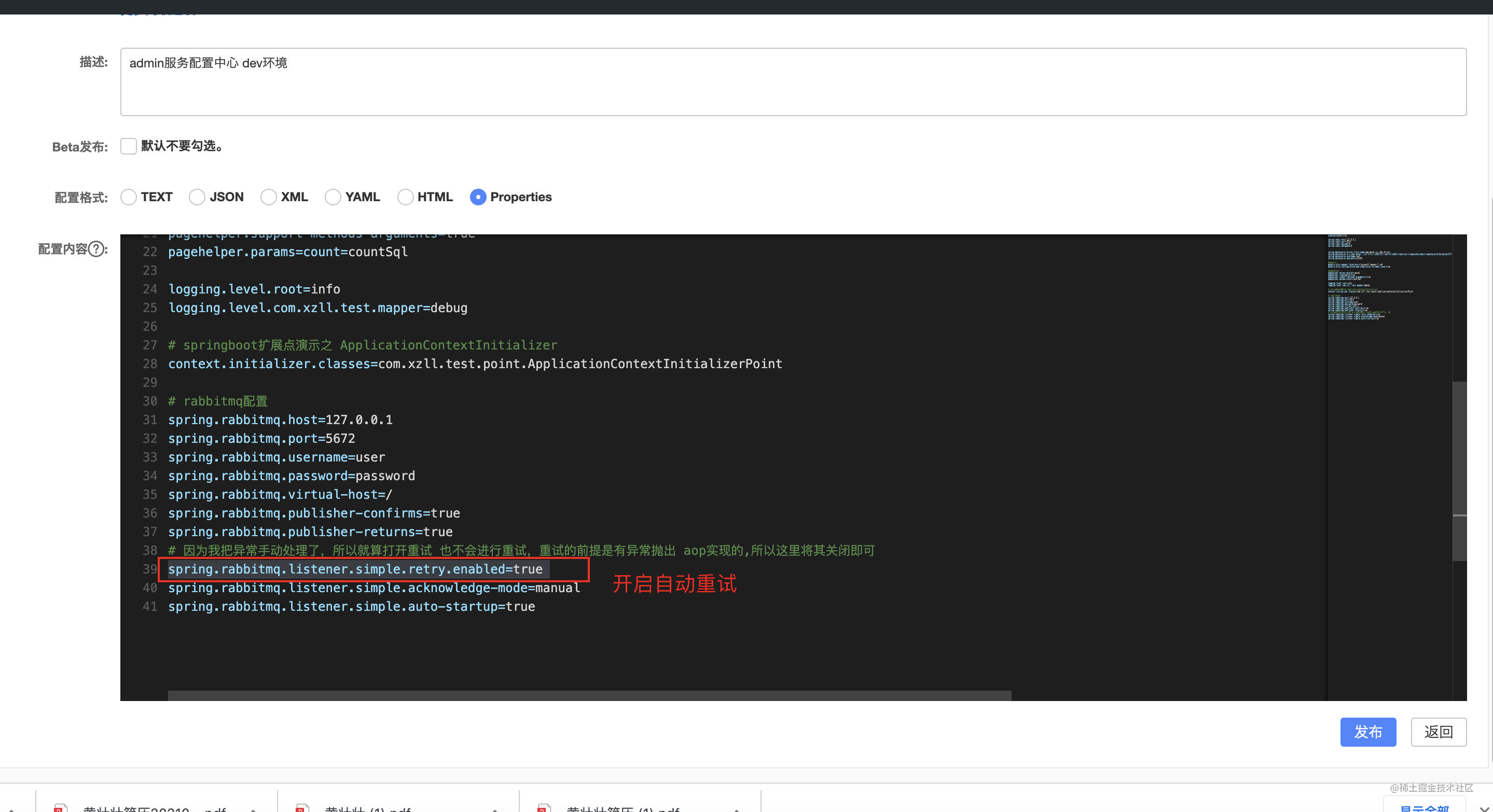
# 因为我把异常手动处理了,所以就算打开重试 也不会进行重试,重试的前提是有异常抛出 aop实现的,所以这里将其关闭即可
spring.rabbitmq.listener.simple.retry.enabled=false
spring.rabbitmq.listener.simple.acknowledge-mode=manual
spring.rabbitmq.listener.simple.auto-startup=true
最后的最后,我想说一句,没有最好的设计,只有最合适的设计。用哲学来讲就是: 具体问题具体分析 哈哈~~~
本文代码均已经上传到我的github 戳这里即可

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)