【kafka基础】-- 读写流程及举例
1. 连接到 zk 集群,从 zookeeper 中拿到对应的 topic 的 partition 信息和 partition 的 leader 的相关信息2. 连接到对应的 leader 对应的 broker3. producer 将消息发送到 partition 的leader上4. leader 将消息写入本地 log, follower 从 leader pull 同步消息5. 写入本地
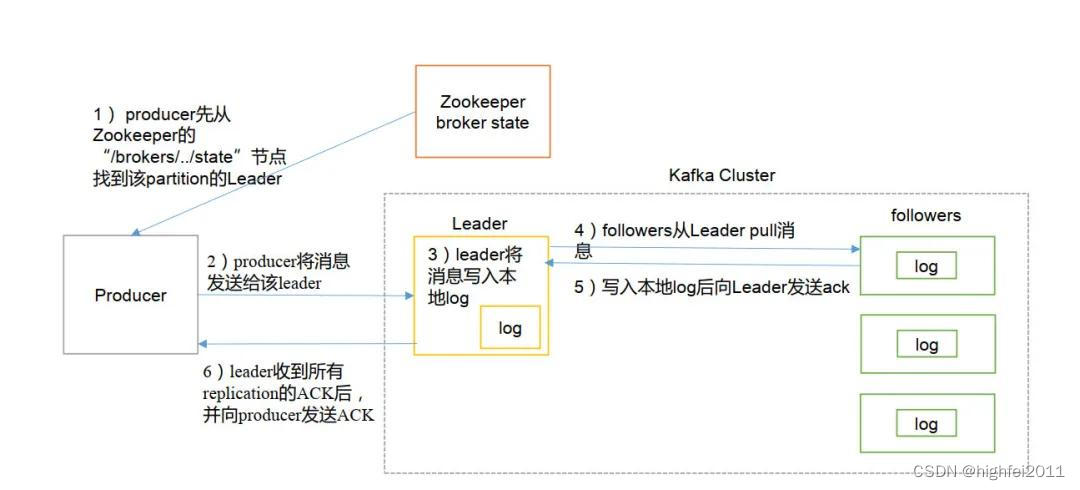
一、Kafka 写数据流程
1. 连接到 zk 集群,从 zookeeper 中拿到对应的 topic 的 partition 信息和 partition 的 leader 的相关信息(注意:kafka0.8 版本以后,producer 写入数据不依赖 zookpeer !)
2. 连接到对应的 leader 对应的 broker
3. producer 将消息发送到 partition 的leader上
4. leader 将消息写入本地 log, follower 从 leader pull 同步消息
5. 写入本地 log 后,依次向 leader 返回/发送 ack
6. leader 收到所有 replication 的 ack 后,向 producer 发送 ack
7. 所有的 ISR 中的数据写入完成,才完成提交,整个写过程结束
流程图如下
二、Kafka 读数据流程
1. 连接到 zk 集群,从zookeeper 中拿到对应的 topic 的 partition 信息和 partition 的 leader 的相关信息
2. 连接到对应的 leader 对应的 broker
3. consumer 将自己保存的 offset 发送给 leader
4. leader 根据 offset 等信息定位到 segment(索引文件 .index 和日志文件 .log )
5. 根据索引文件中的内容,定位到日志文件中该偏移量对应的开始位置读取相应长度的数据并返回给 consumer
查询数据

说明:.index文件 存储大量的索引信息,.log文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
举例:如现在要查找偏移量 offset 为 3 的消息,根据 .index 文件命名我们可以知道,offset 为 3 的索引应该从00000000000000000000.index 里查找。根据上图所示,其对应的索引地址为 756-911,所以 Kafka 将读取00000000000000000000.log 756~911区间的数据。
注:kafka partition 下 data 存储的目录结构及介绍

以上这些文件的含义如下:
| 类别 | 作用 |
|---|---|
| .index | 偏移量索引文件,存储数据对应的偏移量 |
| .timeindex | 时间戳索引文件 |
| .log | 日志文件,存储生产者生产的数据 |
| .snaphot | 快照文件(最近2次,需要参数配置) |
| leader-epoch-checkpoint | 保存了每一任leader开始写入消息时的offset,会定时更新。follower被选为leader时会根据这个确定哪些消息可用 |
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。偏移量 offset 是一个 64 位的长整形数,固定是20 位数字,长度未达到,用 0 进行填补,索引文件和日志文件都由此作为文件名命名规则。所以从上图可以看出,该分区的偏移量是从 57819368 开始的,.index 和 .log 文件名称都为 00000000000057819368。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)