hadoop3.3.4+flink1.15.2+hbase2.5.0集群搭建[当前最新]
hadoop和hbase部署
hadoop3.3.4+flink1.15.2+hbase2.5.0集群搭建
准备3台centos7 服务器,IP为192.168.10.155~157.
本文约定安装包上传到155的/opt目录,程序安装到各服务器的/usr/java目录.
1.准备工作
均配置hosts
/etc/hosts
#在文件最后增加以下映射
192.168.10.155 master
192.168.10.156 slave1
192.168.10.157 slave2
如果客户端链接zookeeper后出现一直卡住无法操作hbase,请尝试在客户端机器上配置以上映射
这是因为zookeeper中可能注册的是域名master

均重启网络服务(可能需要重启才生效)
systemctl restart network
均关闭防火墙:
#停止firewall
systemctl stop firewalld
#禁止firewall开机启动
systemctl disable firewalld
仅在master配置免密登录,并分发给其他节点服务器
免密登陆用于scp和从master启动集群,不要在多个服务器执行[后果未测试]
#生成密钥
ssh-keygen -t rsa
#分发密钥,在执行过程中需输入服务器密码,按提示操作即可
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
均配置时间同步
yum install ntpdate -y
ntpdate ntp1.aliyun.com
在master安装nc,用于测试服务启动情况[可选]
yum install nc -y
#nc使用样例:
#nc -v -w 10 -z master 8020
均卸载自带openjdk,自带jdk是rpm安装的,通常安装最小版centos,不会自带jdk
#查询是否已安装jdk
rpm -qa|grep java
#如果有安装,根据查询结果卸载
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.242.b08-1.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.251-2.6.21.1.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.251-2.6.21.1.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64
2.安装jdk
下载jdk8的linux压缩包,本文中是jdk-8u221-linux-x64.tar.gz,上传到master的/opt目录并解压
程序包在最后统一分发/usr/java目录,这样各个节点就都有了程序包
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /usr/java/
均配置java环境变量, 最好不要使用远程拷贝,因为每个服务器可能装的软件不一样.
#编辑环境变量文件
vi /etc/profile
#文章的最后加入以下文本,部分代码为后续软件用到,建议一次性配置到位,避免每个服务器多次修改
#java-home
export JAVA_HOME=/usr/java/jdk1.8.0_221
export JRE_HOME=/usr/java/jdk1.8.0_221/jre
export CLASS_PATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
#hadoop
export HADOOP_HOME=/usr/java/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#hbase
export HBASE_HOME=/usr/java/hbase-2.5.0
export PATH=$HBASE_HOME/bin:$PATH
#flink
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH='hadoop classpath'
#使用:wq保存文件[按键盘a开始编辑,esc退出编辑,:q不保存退出,:q!强制退出]
#让环境变量生效,可以不执行,到最后重启服务器也会生效
source /etc/profile
3.安装hadoop
下载hadoop安装包,本文中是hadoop-3.3.4.tar.gz,上传到master的/opt并解压
程序包在最后统一分发/usr/java目录,这样各个节点就都有了程序包
tar zxvf hadoop-3.3.4.tar.gz -C /usr/java/
配置hadoop的core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml和workers
cd /usr/java/hadoop-3.3.4/etc/hadoop/
vi core-site.xml
#在文件最后的configuration标签中增加以下内容并保存
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
<description>表示HDFS的服务地址,8020为datanode的服务端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/java/data/hadoop</value>
<description>临时文件存储位置,通常定义一个明确不易干扰的位置</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
vi hdfs-site.xml
#在文件最后的configuration标签中增加以下内容并保存
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9868</value>
<description>指定备用namenode,会启动secondarynamenode服务</description>
</property>
vi mapred-site.xml
#在文件最后的configuration标签中修改或增加以下内容并保存
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*, $HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
vi yarn-site.xml
#在文件最后的configuration标签中修改或增加以下内容并保存
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<discription>指定resourcemanager服务的位置,其负责与各nodemanger心跳通信</discription>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1600</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>是否内存检查,在虚拟机中设置false很有用</description>
</property>
vi workers
#在文件中输入以下内容并保存
master
slave1
slave2
配置环境变量,如果做jdk时已配置,则跳过
vi /etc/profile
export HADOOP_HOME=/usr/java/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
在master上执行 namenode 格式化,其他节点不能执行,如果多次执行可能出现错误hdfs.server.datanode.DataNode: Block pool ID needed, but service not yet registered with NN
https://www.cnblogs.com/Jomini/p/10926765.html
文中提及的data目录由前面配置的hadoop.tmp.dir参数指定
hdfs namenode -format
解决可能出现的错误
1参考http://t.zoukankan.com/codeOfLife-p-5940642.html
2参考https://blog.csdn.net/weixin_43848614/article/details/112596493
vi hadoop-env.sh
# 必须重新指定java_home,否则报错Error JAVA_HOME is not set and could not be found
export JAVA_HOME=/usr/java/jdk1.8.0_221
# 必须指定root用户,因为我们以root部署,否则报错ERROR: but there is no HDFS_NAMENODE_USER defined
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4.安装hbase
下载hbase安装包,本文中是hbase-2.5.0-bin.tar.gz,上传到master的/opt并解压
程序包在最后统一分发/usr/java目录,这样各个节点就都有了程序包
tar -zxvf hbase-2.5.0-bin.tar.gz -C /usr/java/
修改hbase-env.sh hbase-site.xml
cd /usr/java/hbase-2.5.0/conf
vi hbase-env.sh
#在文件最后新增以下内容并保存
#显式指定jdk
export JAVA_HOME=/usr/java/jdk1.8.0_221
#设置使用外部zookeeper
export HBASE_MANAGES_ZK=false
#设置不扫描hadoop的jar,如果扫描很容易出现异常object is not an instance of declaring class
#参考https://blog.csdn.net/yhj_911/article/details/125481762
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
vi hbase-site.xml
#在hbase-site.xml中新增或修改以下内容,注释不要复制
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.11.211:2181</value>
<!--192.168.11.211:2181是外部zk地址,如果是集群则写为ip1,ip2,ip3:2181-->
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
<!--必须与hadoop中指定的fs.defaultFS参数一致,然后加上hbase-->
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/java/data/hbase</value>
<!--临时文件位置,与hadoop放一起-->
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
修改 regionservers
vi regionservers
master
slave1
slave2
增强可用性,启用1-多个备份mater节点
touch backup-masters
vi backup-masters
#指定一个节点,指定后会在slave1上也启动hmater进程,在管理页面也有显示
slave1
修改环境变量,如果前面统一处理了,则跳过
vi /etc/profile
#hbase
export HBASE_HOME=/usr/java/hbase-2.5.0
export PATH=$HBASE_HOME/bin:$PATH
5.安装flink
下载flink安装包,本文中是flink-1.15.2-bin-scala_2.12.tgz,上传到master的/opt并解压
tar -zxvf flink-1.15.2-bin-scala_2.12.tgz -C /usr/java/
修改flink-conf.yaml 文件(使用rocksdb状态后端 开启HistoryServer 记录历史任务)
cd /usr/java/flink-1.15.2/conf
vi flink-conf.yaml
#在文件中寻找以下参数并去掉注释符号(启用该项)
#JobManager 节点地址.
jobmanager.rpc.address: master
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
state.backend: rocksdb
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
state.checkpoints.dir: hdfs://master:8020/flink-checkpoints
# Default target directory for savepoints, optional.
#
state.savepoints.dir: hdfs://master:8020/flink-savepoints
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
jobmanager.archive.fs.dir: hdfs://master:8020/flink/completed-jobs/
# The address under which the web-based HistoryServer listens.
historyserver.web.address: 0.0.0.0
# The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
historyserver.archive.fs.dir: hdfs://master:8020/flink/completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
historyserver.archive.fs.refresh-interval: 10000
修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点
vi workers
slave2
slave3
配置环境变量,启用yarn模式
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH='hadoop classpath'
6.程序分发
注意/etc/profile文件中配置的环境变量三个服务器都需要有,该文件不建议分发.
scp -r /usr/java root@slave1:/usr
scp -r /usr/java root@slave2:/usr
7.启动服务并校验
可以在master上编写批处理文件/usr/java/start.sh, 关闭则单独执行对应的stop-XXX.sh,也可以单独执行.
vi /usr/java/start.sh
#输入以下内容
/usr/java/hadoop-3.3.4/sbin/start-all.sh
/usr/java/hbase-2.5.0/bin/start-hbase.sh
/usr/java/flink-1.15.2/bin/start-cluster.sh
先重启三个服务器,确保环境变量正常加载了,如果修改,可以使用source /etc/profile来重新加载
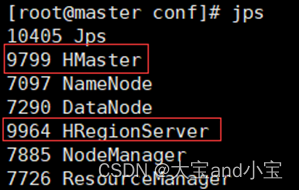
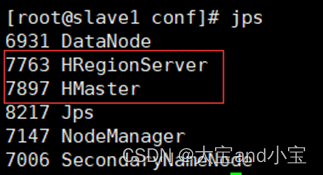
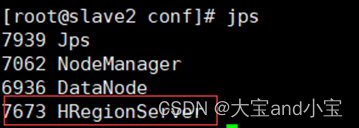
启动hadoop和hbase后进程情况
可以根据进程情况排查什么没有启动,其中红色框起来的是hbase进程.
master:
slave1:
slave2:
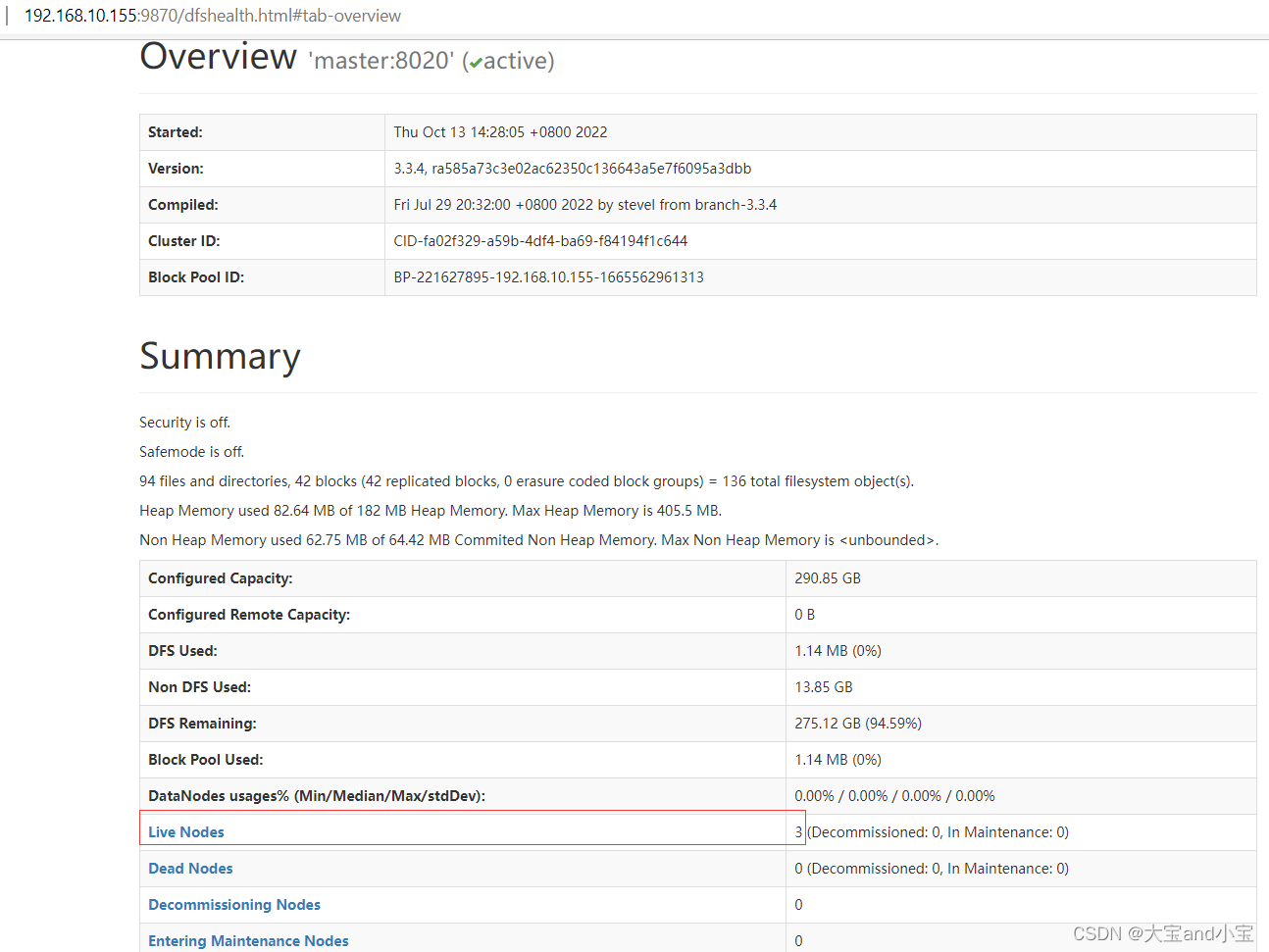
namenode情况
Yarn查看任务运行情况
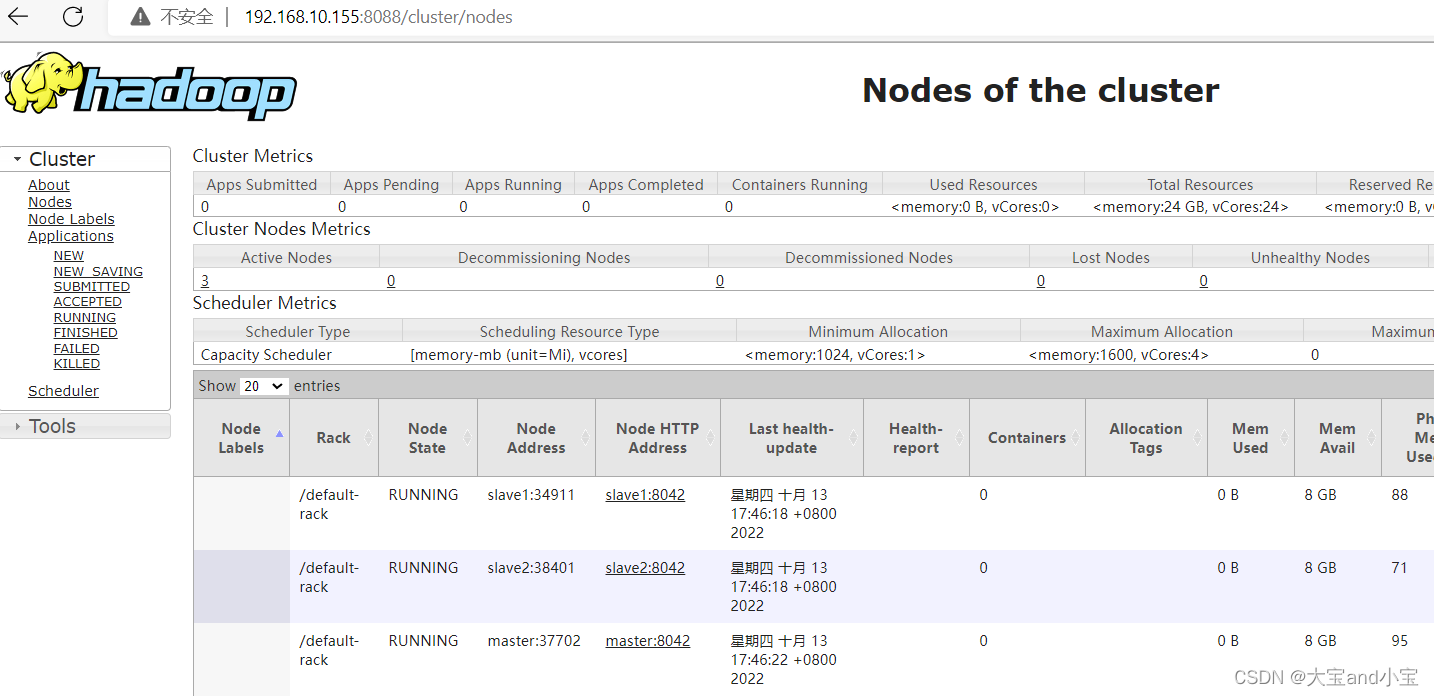
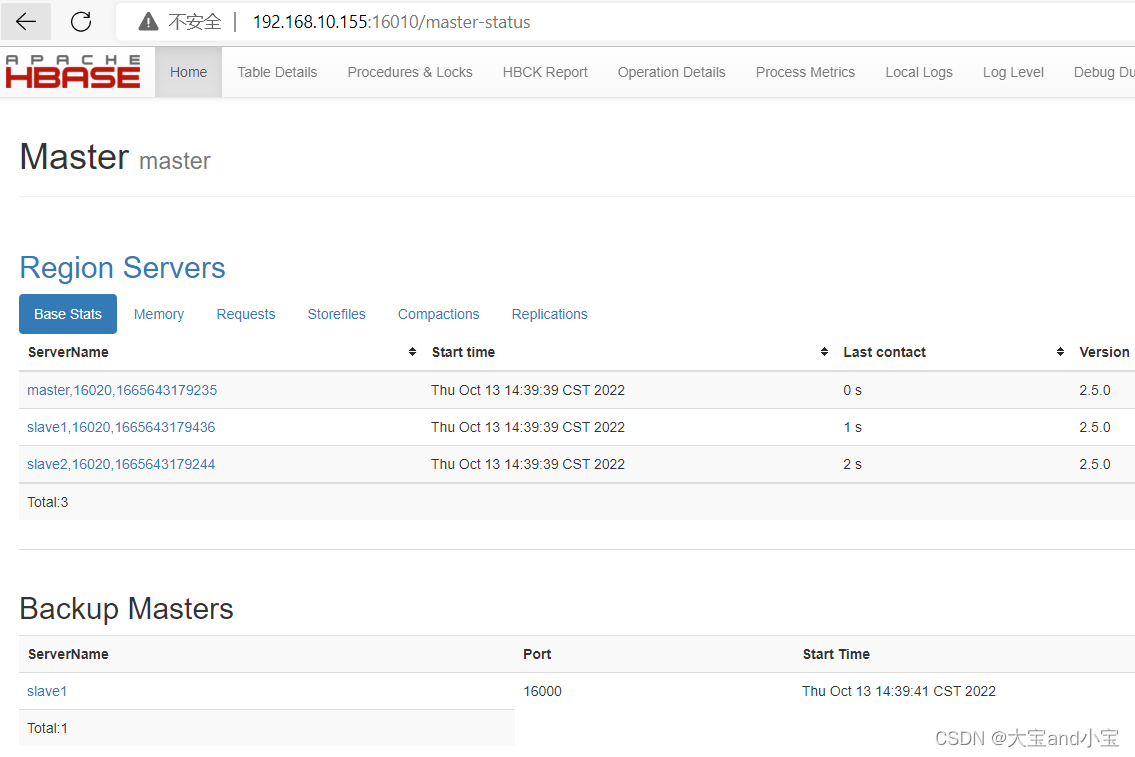
hbase控制台
flink控制台


8.安装zookeeper
如果hbase使用外部zookeeper,此项可跳过,通常我们使用外部的.
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /usr/java/
配置zk环境变量
vi /etc/profile
#在文件最后输入以下内容
#zk-home
export PATH=$PATH:/usr/java/apache-zookeeper-3.8.0-bin/bin
#:wq保存
#让环境变量生效
source /etc/profile
复制配置文件
cd /usr/java/apache-zookeeper-3.8.0-bin/conf
cp zoo_sample.cfg zoo.cfg
创建zk数据存储目录
mkdir -p /usr/java/data/zookeeper-3.8.0
编辑zoo.cfg配置文件
vi zoo.cfg
dataDir=/usr/java/data/zookeeper-3.8.0
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
添加myid配置
/usr/java/data/zookeeper-3.8.0路径下创建一个文件,文件名为myid ,文件内容为1
echo 1 > /usr/java/data/zookeeper-3.8.0/myid
安装包分发并修改myid的值
第一台机器上面执行以下两个命令
scp -r /usr/java/apache-zookeeper-3.8.0-bin root@slave1:/export/server/
scp -r /usr/java/apache-zookeeper-3.8.0-bin root@slave2:/export/server/
第二台机器上修改myid的值为2
直接在第二台机器任意路径执行以下命令
echo 2 > /usr/java/data/zookeeper-3.8.0/myid
第三台机器上修改myid的值为3
直接在第三台机器任意路径执行以下命令
echo 3 > /usr/java/data/zookeeper-3.8.0/myid
三台机器启动zookeeper服务
三台机器都要执行
/bin/zkServer.sh start
#查看启动状态
/bin/zkServer.sh status

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)